







 本文详细介绍如何通过巨潮资讯网查阅及下载A股上市公司的年报,包括年报的两种版本及其获取方式,为投资者提供全面的财务信息分析指南。
本文详细介绍如何通过巨潮资讯网查阅及下载A股上市公司的年报,包括年报的两种版本及其获取方式,为投资者提供全面的财务信息分析指南。

实现财务自由 之 A 股上市公司的年报(年度财报)查阅查看、下载地址、以及下载的方法
目录
实现财务自由 之 A 股上市公司的年报(年度财报)查阅查看、下载地址、以及下载的方法
5、即可看到该上市公司近几年的所有上传的详细或简单的年报半年报信息
年报是每年出版一次的定期bai刊物。又du称年刊, 根据证券交易委员会规定,必须提zhi交股东的公司年度财务报表。dao报表包括描述公司经营状况,以及资产负债和收入的报告、年报长表称为10-K,其中的财务信息更为详尽,可以向公司秘书处索取,或者指定网站下载。
年报在上市公司中有两种版本,一种是在公开媒体上披露的年报摘要,其内容较简单;另一版本是交易所网站披露的详细版本。
注意:进行年报分析,建议最好连续几年的年报一起看,这样数据多了,分析会更全面,而且还能总结一些数据趋势来。
A 股上市公司年报,下载具体方法
1、打开浏览器,输入网址,打开巨潮资讯网
网址:http://www.cninfo.com.cn/new/index
2、找到输入框,输入想要查看或下载上市公司的名称或代码
这里以贵州茅台为例,如下图
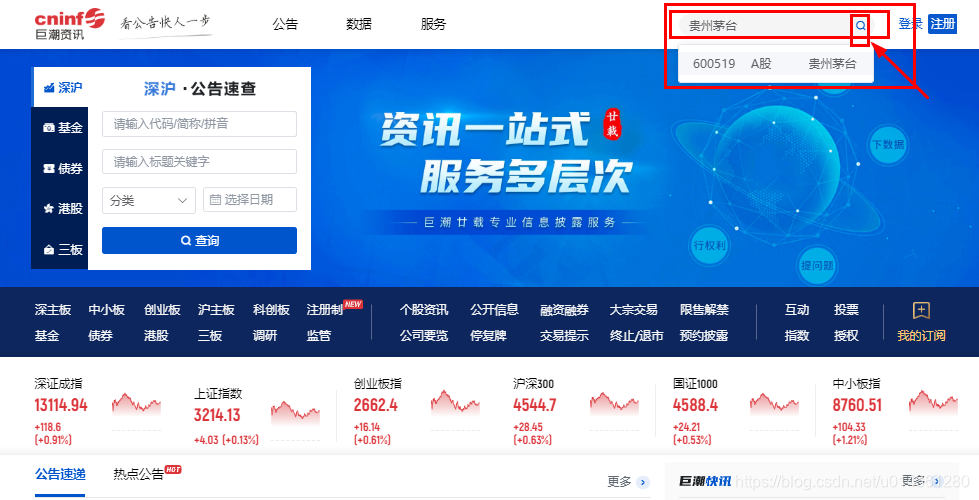
3、点击搜索,跳转到搜索上市公司的资讯界面
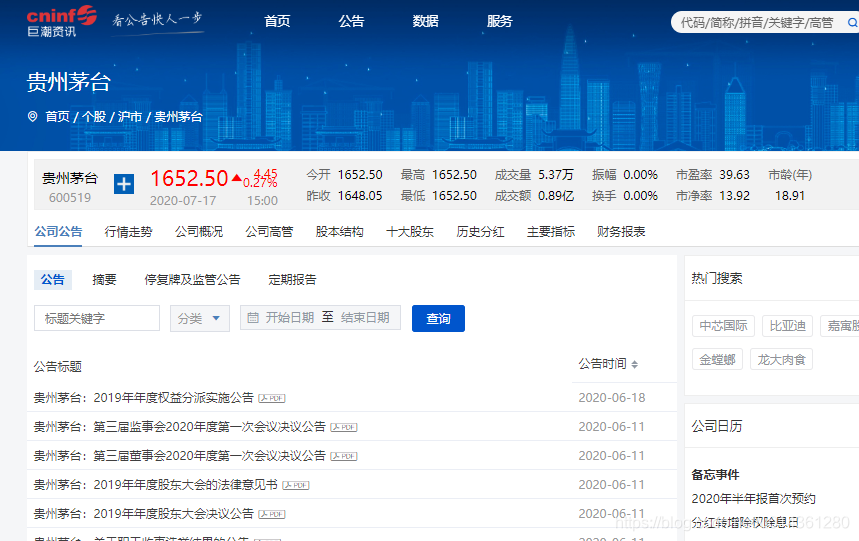
4、在标题关键字中输入 年报,进行搜索信息
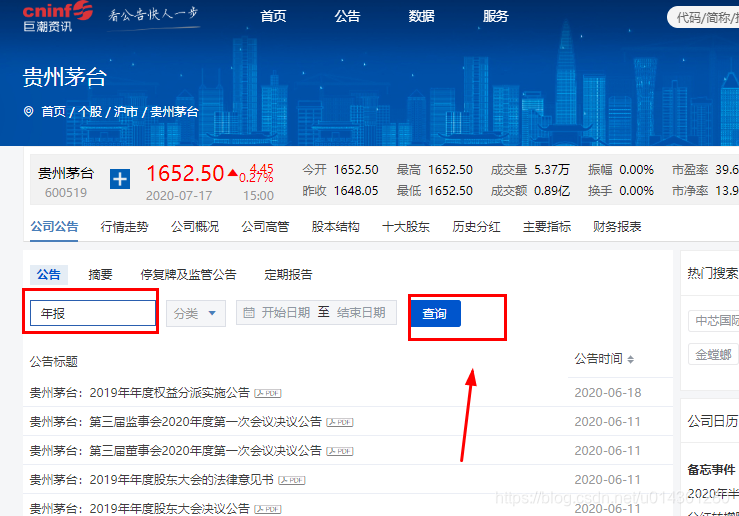
5、即可看到该上市公司近几年的所有上传的详细或简单的年报半年报信息
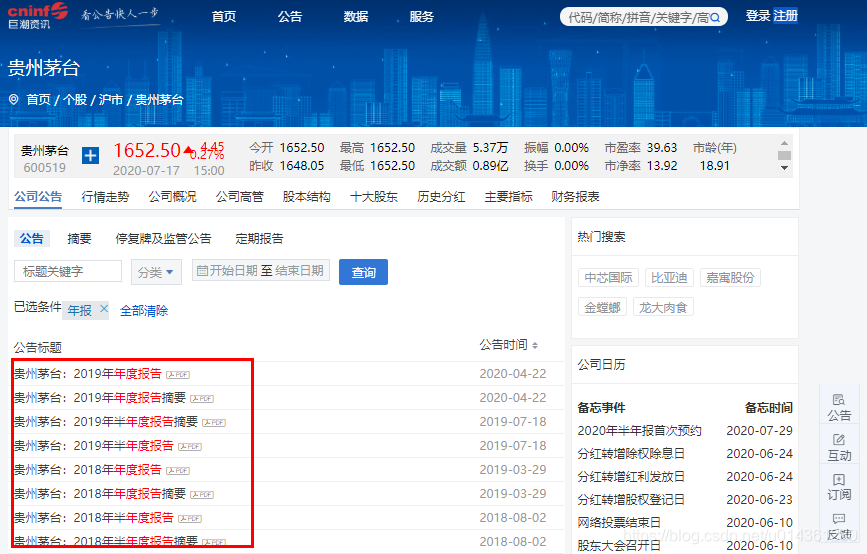
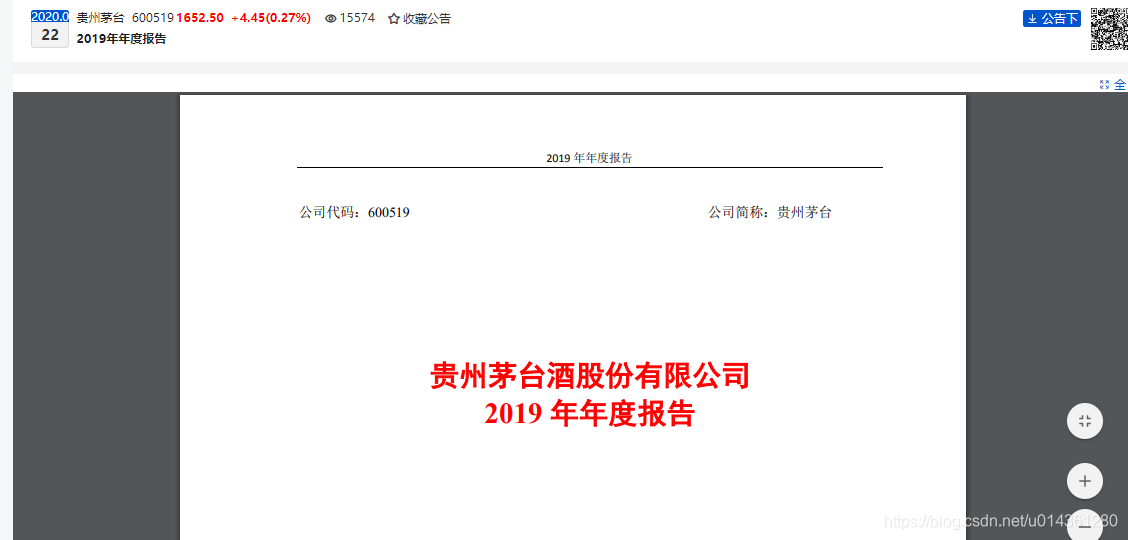
6、点击对应年报标题,即可查看
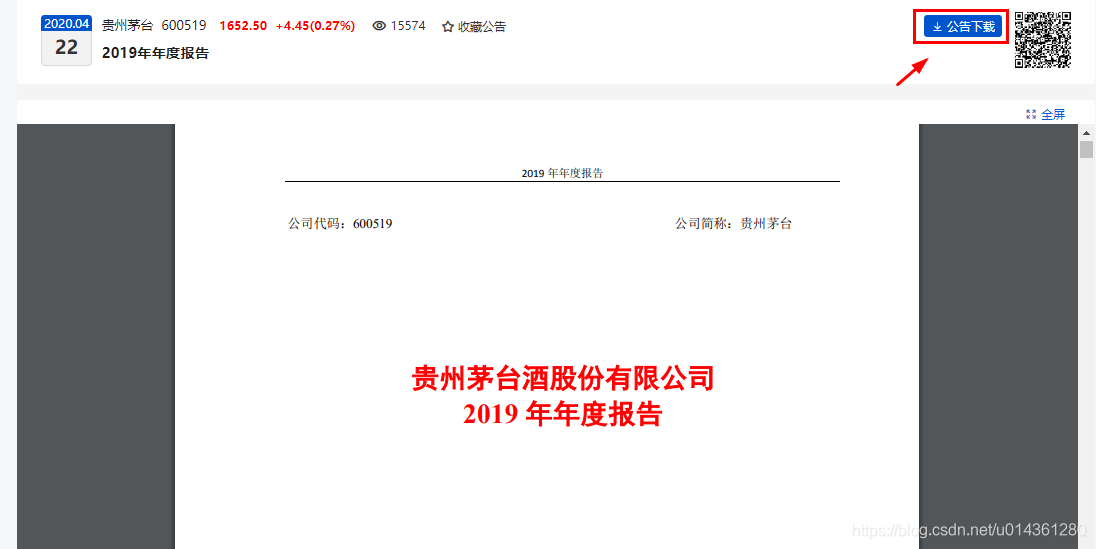
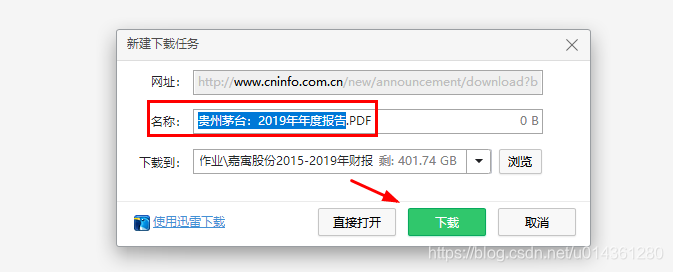
7、点击 公告下载,即可下载对应年报文件
查看下载A股上市年报的方式多种多样,以上方法,仅供参考,祝大家早日实现财务自由



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











