









异常检测有新突破了!清华和华科大推出了INP-Former,从单张图像中提取正常模式,展现出卓越的性能和强大的泛化能力!成功被CVPR 2025收录。
仔细一瞧,今年的CVPR上异常检测相关的研究还挺多,比如最新零样本工业缺陷异常检测SOTA:AA-CLIP,还有突破跨领域限制的UniVAD,通过统一模型实现无需训练的泛化异常检测!
这些成果也足以证明,2025年异常检测仍然会是顶会热门!而且根据其在AIGC等新兴技术领域的拓展,未来在跨学科交叉方面应该会更有搞头。同时,我们也可以关注可解释、低资源等核心挑战,再结合垂直场景的深层次需求做创新。
本文整理了11篇异常检测2025新论文,基本都有开源代码,需要参考的同学可无偿获取。
全部论文+开源代码需要的同学看文末
Exploring Intrinsic Normal Prototypes within a Single Image for Universal Anomaly Detection
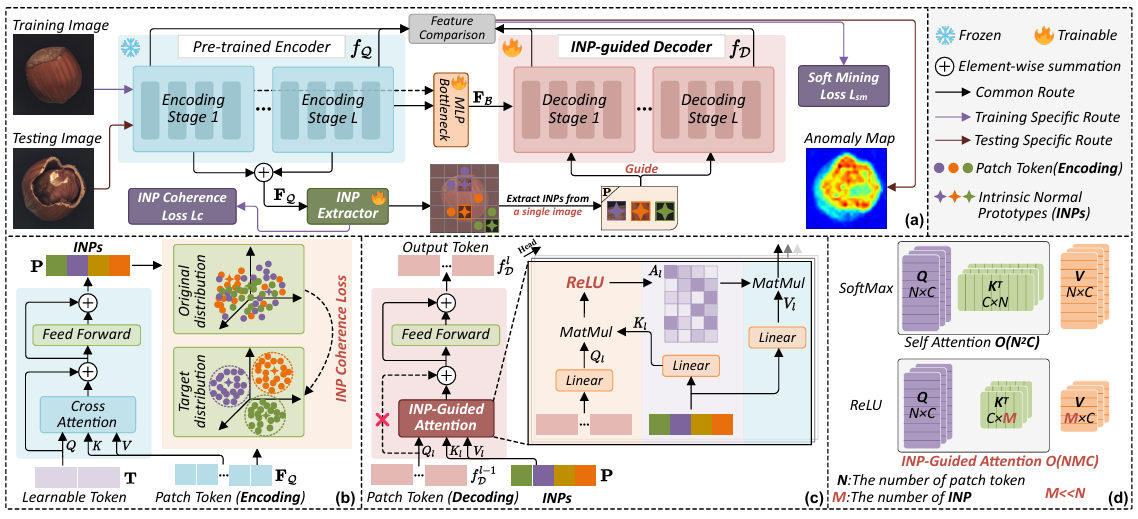
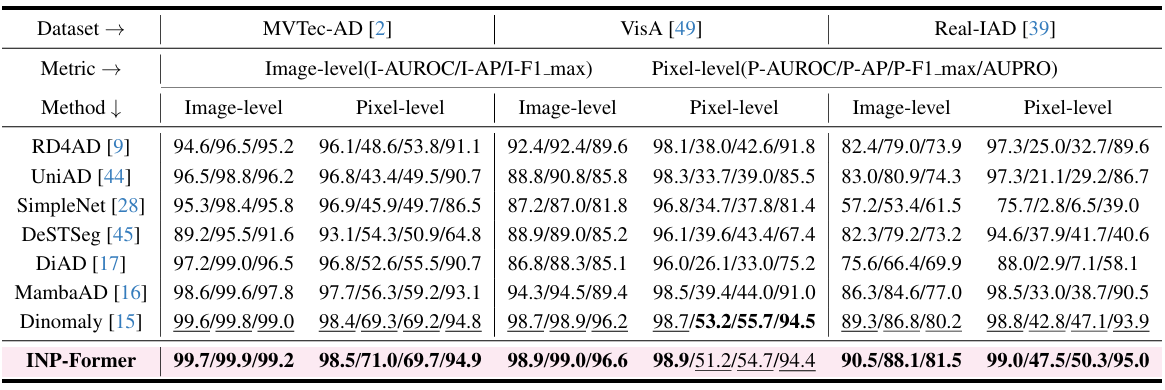
方法:论文介绍了一种新的异常检测方法INP-Former,它可以从单张测试图像中提取“内在正常原型”(INPs),并用这些INPs来重建图像中的正常部分,通过比较重建误差来检测异常。这种方法在多种异常检测任务上表现优异。
创新点:
-
提出INP-Former方法,从单张测试图像中直接提取“内在正常原型”(INPs)用于异常检测。
-
引入INP一致性损失,确保提取的INPs准确代表正常特征,避免异常干扰。
-
设计软挖掘损失,优化训练过程,重点关注难以重建的正常区域,提升检测性能。
AA-CLIP: Enhancing Zero-Shot Anomaly Detection via Anomaly-Aware CLIP
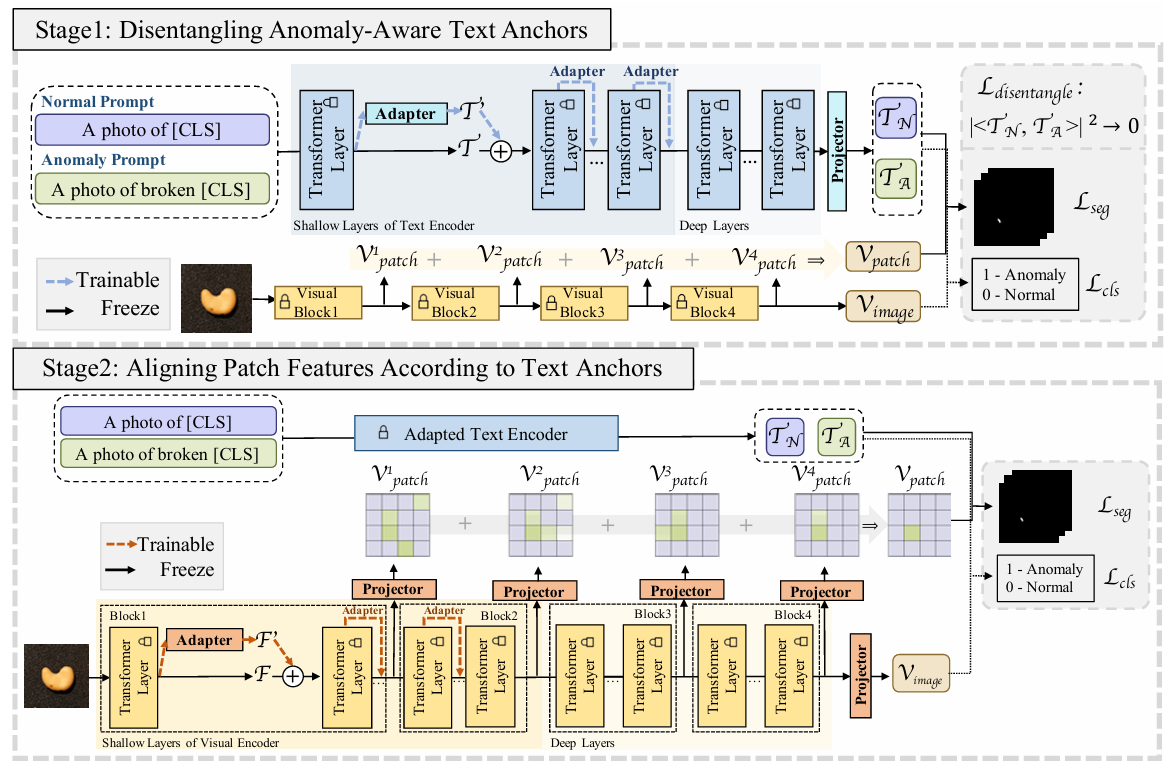
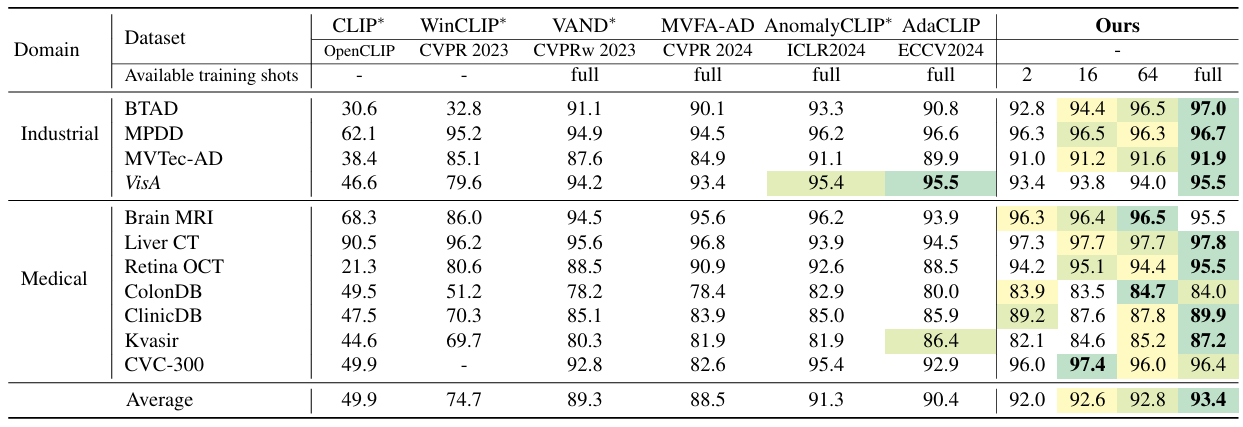
方法:论文提出AA-CLIP,一种改进CLIP模型的方法,用于零样本异常检测。它通过两阶段训练:第一阶段创建区分正常和异常的文本锚点,第二阶段将视觉特征与这些锚点对齐,从而提高异常检测的准确性。这种方法在保持CLIP泛化能力的同时,显著提升了异常检测性能。
创新点:
-
提出AA-CLIP,通过两阶段训练策略增强CLIP对异常的感知能力。
-
在第一阶段,引入残差适配器和解耦损失函数,清晰区分正常和异常的文本特征。
-
在第二阶段,将视觉特征与文本锚点对齐,实现精准的异常定位和检测。
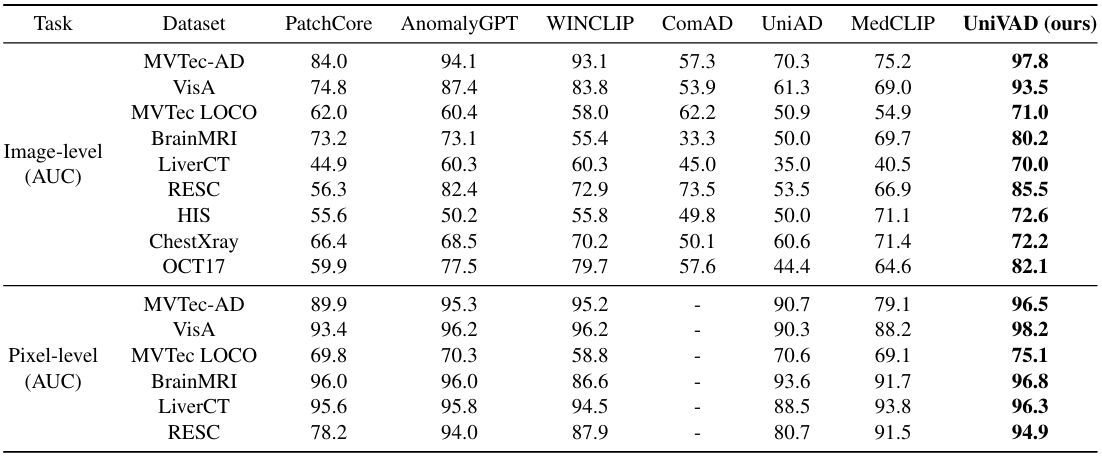
UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection
方法:UniVAD是一种无需训练的统一模型,用于少样本视觉异常检测。它通过三个模块实现跨领域的异常检测:C3模块分割图像组件,CAPM模块检测结构异常,GECM模块检测逻辑异常。最终结果由多级异常检测结果聚合而成,实验表明其在多个领域的异常检测性能优于现有方法。
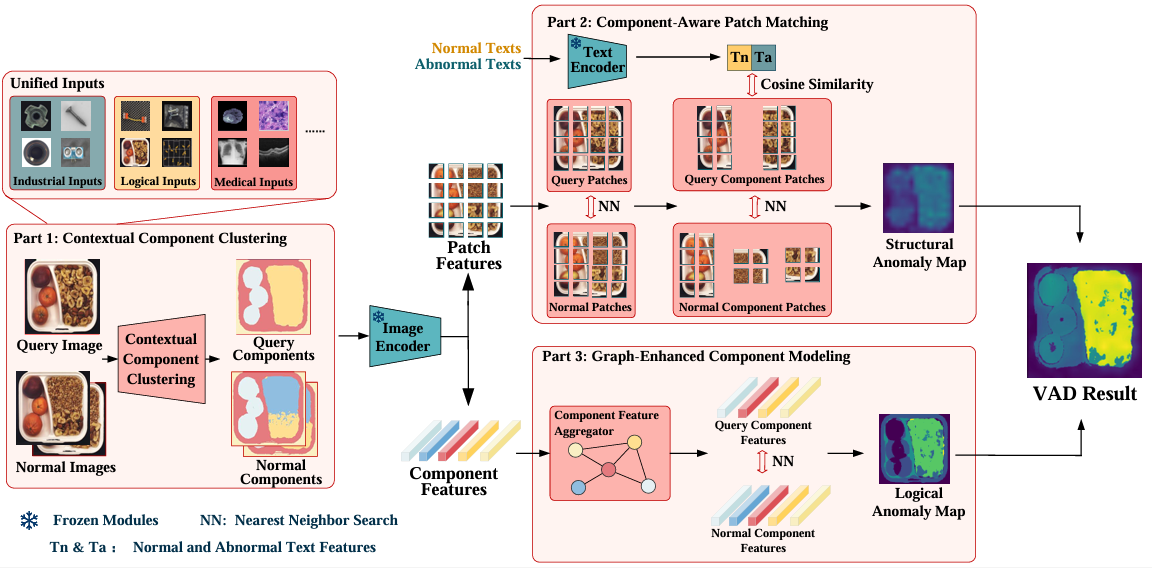
创新点:
-
UniVAD实现了跨领域异常检测,无需针对每个领域单独训练,仅用少量正常样本即可检测多种领域的异常。
-
C3模块结合视觉基础模型和聚类技术,精准分割图像组件,适应少样本场景。
-
CAPM和GECM模块分别检测结构和逻辑异常,聚合多级信息提升检测性能。
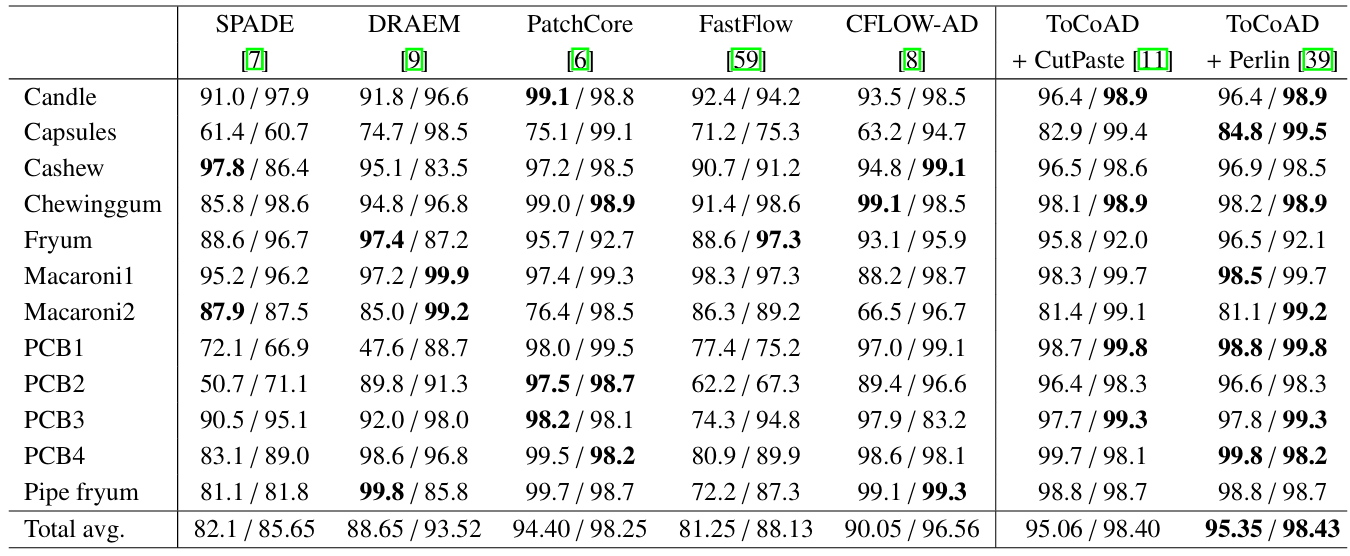
ToCoAD: Two-Stage Contrastive Learning for Industrial Anomaly Detection
方法:ToCoAD是一种用于工业异常检测的两阶段训练方法。第一阶段通过合成异常样本训练一个判别网络来粗略定位异常;第二阶段利用该网络提供负样本指导,通过对比学习微调特征提取器,增强模型对异常的敏感性。最终通过记忆库和距离计算实现异常定位。该方法在多个数据集上表现出色。
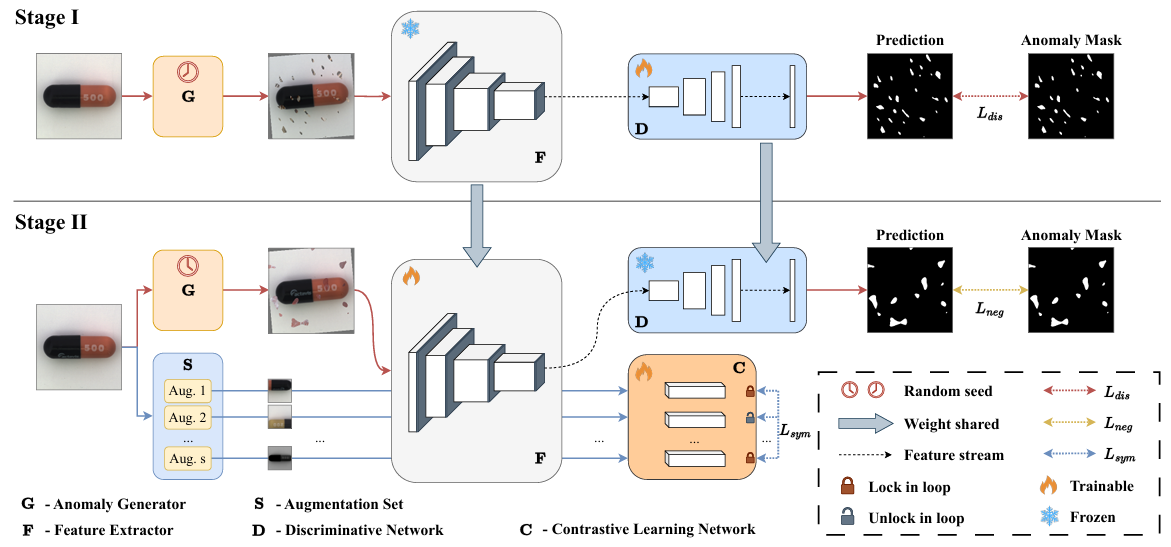
创新点:
-
两阶段训练:先用合成异常训练判别网络,再用其引导对比学习微调特征提取器。
-
负样本引导:通过正负样本联合训练,增强模型对异常的敏感性。
-
性能优异:在多个数据集上取得高AUROC分数,证明了方法的有效性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









