







 本文详细解析了 vLLM 模型推理框架中的 Block 模块,包括逻辑 Block 和物理 Block 的概念、大小计算、数量计算以及管理策略。Block 通过内存划分策略降低了内存碎片化问题,每个 Block 可以存储固定数量的 token kv cache 数据。Block 的大小取决于 token 数量和单个 token 的 kv cache 占用内存,而数量则基于 GPU 内存使用情况动态计算。vLLM 使用逻辑 Block 和物理 Block 的映射关系来管理内存,通过 BlockManager 类实现分配和回收,确保高效利用资源。
本文详细解析了 vLLM 模型推理框架中的 Block 模块,包括逻辑 Block 和物理 Block 的概念、大小计算、数量计算以及管理策略。Block 通过内存划分策略降低了内存碎片化问题,每个 Block 可以存储固定数量的 token kv cache 数据。Block 的大小取决于 token 数量和单个 token 的 kv cache 占用内存,而数量则基于 GPU 内存使用情况动态计算。vLLM 使用逻辑 Block 和物理 Block 的映射关系来管理内存,通过 BlockManager 类实现分配和回收,确保高效利用资源。
目录
1. Block 概览
vLLM 的一个很大创新点是将物理层面的 GPU 和 CPU 可用内存切分成若干个 block,这样可以有效降低内存碎片化问题。具体而言,vLLM 的 block 分为逻辑层面(logical)和物理层面(physical),二者之间存在映射关系。下图很好解释了两个层面 block 的关系。
假设每个 block 可以用来存 4 个 token 的 kv cache 数据。一个句子的 token 在逻辑层面是紧邻的,每次 decoding 生成新的 token 就往空闲的 block 里放。但是对应到物理层面的 block,一个句子的 token 可能分布在并不相邻的 block 内,不过没关系,vLLM 会为每个句子的每个 token 记录逻辑和物理 block 的映射关系,方便查找和读取。
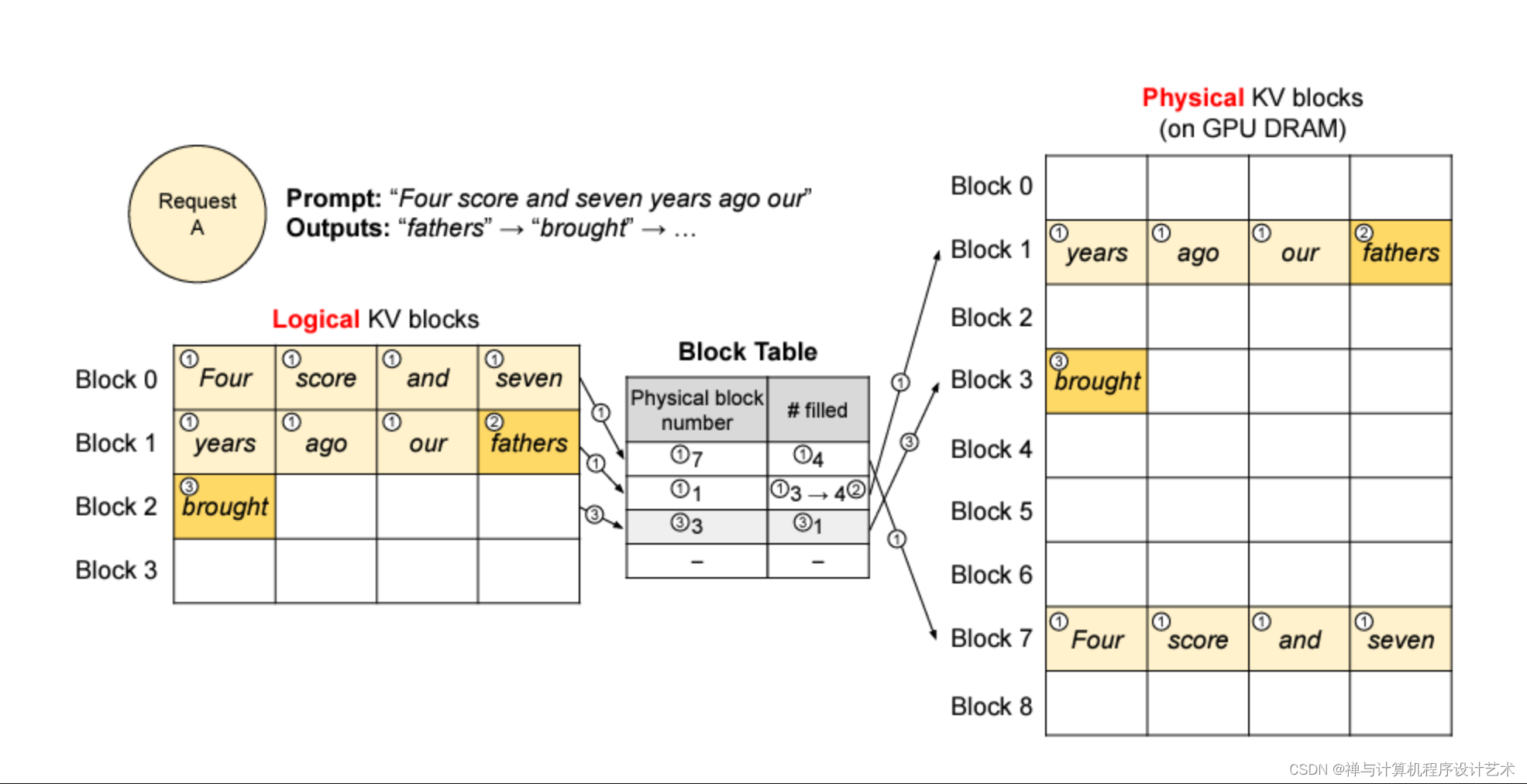
vLLM Block
接下来我们详细介绍 block 大小的含义,以及 block 的数量是如何计算的,最后介绍 vLLM 是如何管理 block 的。
2. Block 大小如何计算
block 的大小可以自定义,上面定义为 4,简单理解就是每个 block 最多存储 4 个 token 的 kv cache 数据。但是 block 设置为 4 的时候对应到 GPU 内存到底是多大呢?其实这很好计算,
一个 block 占用内存大小(Byte)= token 数量 (block_size) ✖️ 一个 token 的 kv cache 占用 内存大小。
所以,我们只需要计算出单个 token 的 kv cache 对应的大小即可。block 大小的计算方法由vllm/vllm/worker/cache_engine.py文件里CacheEngine类的get_cache_block_size函数实现,代码也很简单,简化后如下:
# vllm/vllm/worker/cache_engine.py
class CacheEngine:
@staticmethod
def get_cache_block_size(
block_size: int,
cache_dtype: str,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
head_size = model_config.get_head_size()
num_heads = model_config.get_num_kv_heads(parallel_config)
num_layers = model_config.get_num_layers(parallel_config)
key_cache_block = block_size * num_heads * head_size
value_cache_block = key_cache_block
total = num_layers * (key_cache_block + value_cache_block)
if cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_dtype]
dtype_size = _get_dtype_size(dtype)
return dtype_size * total
上面代码中首先拿到 num_heads和head_size两个变量的值, num_heads * head_size就表示单个 token 在单层多头注意力机制计算中所需要的参数量,不过这只是 key 或者 value cache 所占用的参数量。
一个 block 占用的内存 = token 数量(block_size)✖️ 层数 (num_layers) ✖️ 单层 kv cache 占用内存 (2✖️num_heads✖️head_size)✖️ 数据类型大小(如果是 fp16,则每个数据占用 2 Bytes)
举例来说,假设 block_size=4, num_layers=4, num_heads=8, heads_size=128,采用 fp16 存储数据,那么
一个 block 占用内存大小 = 4 ✖️ 4 ✖️ 8 ✖️ 128 ✖️ 2 = 32,768 Bytes。
总结,一个 block 所占用的内存大小就是 block_size 个 token kv cache 说占内存的总和。不同模型的 block 各不相同。
2. Block 数量如何计算
block 数量计算由vllm/vllm/worker/worker.py文件中Worker类的profile_num_available_blocks函数实现,该函数很简单,简化代码如下:
class Worker
@torch.inference_mode()
def profile_num_available_blocks(
self,
block_size: int,
gpu_memory_utilization: float,
cpu_swap_space: int,
cache_dtype: str,
) -> Tuple[int, int]:
torch.cuda.empty_cache()
# 这一行其实就是用模拟数据跑一下forward 来统计GPU 的使用情况
self.model_runner.profile_run()
torch.cuda.synchronize()
free_gpu_memory, total_gpu_memory = torch.cuda.mem_get_info()
peak_memory = total_gpu_memory - free_gpu_memory
cache_block_size = CacheEngine.get_cache_block_size(
block_size, cache_dtype, self.model_config, self.parallel_config)
num_gpu_blocks = int(
(total_gpu_memory * gpu_memory_utilization - peak_memory) //
cache_block_size)
num_cpu_blocks = int(cpu_swap_space // cache_block_size)
num_gpu_blocks & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2675
2675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











