




Vulkan官方英文原文:https://vulkan-tutorial.com/Drawing_a_triangle/Graphics_pipeline_basics/Introduction
对应的Vulkan技术规格说明书版本: Vulkan 1.3.2
Over the course of the next few chapters, we'll be setting up a graphics pipeline that is configured to draw our first triangle. The graphics pipeline is the sequence of operations that take the vertices and textures of your meshes all the way to the pixels in the render targets. A simplified overview is displayed below:
接下来的几个章节结束之后,我们会建立起一个图形管线,它被配置成能画出我们的第一个三角形。图形管线是一系列的有序操作(工作流):将模型网格上的顶点和纹理数据一直带到位于渲染目标中的像素。简化的流程图示如下:
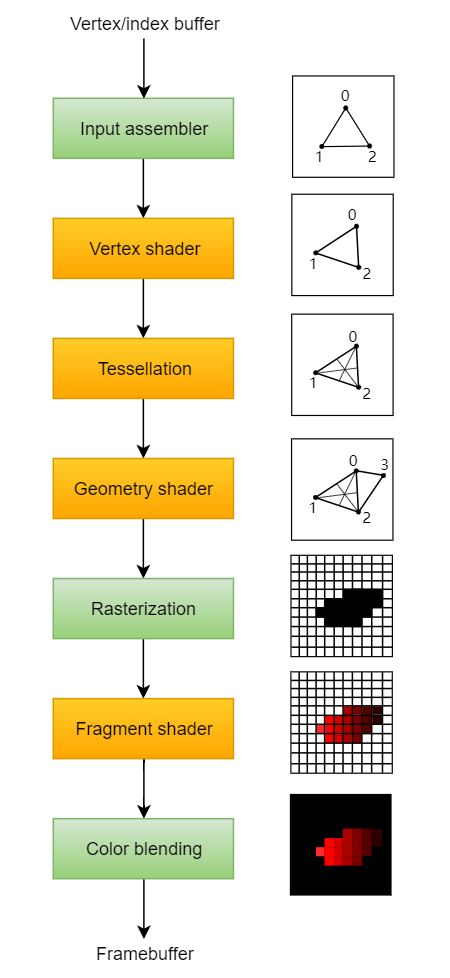
The input assembler collects the raw vertex data from the buffers you specify and may also use an index buffer to repeat certain elements without having to duplicate the vertex data itself.
输入装配器(input assembler) 从你指定的缓冲区中收集原始的顶点数据,也可能用一个索引缓冲区来重复收集特定元素而无需重复自身的顶点数据。
The vertex shader is run for every vertex and generally applies transformations to turn vertex positions from model space to screen space. It also passes per-vertex data down the pipeline.
顶点着色器(vertex shader) 是运行在每一个顶点上,通常用于从物体空间到屏幕空间变换顶点的空间位置。它也逐顶点地将数据沿着管线往下传。
The tessellation shaders allow you to subdivide geometry based on certain rules to increase the mesh quality. This is often used to make surfaces like brick walls and staircases look less flat when they are nearby.
细分着色器(tessellation shader)允许你基于一定的规则进一步细分几何体以提升模型网格的细节精度。像砖墙和楼梯,当它们靠近的时候,这个技术经常被用于产生表面细节使之看起来不那么平(看起来结构细节更多更真实)。
The geometry shader is run on every primitive (triangle, line, point) and can discard it or output more primitives than came in. This is similar to the tessellation shader, but much more flexible. However, it is not used much in today's applications because the performance is not that good on most graphics cards except for Intel's integrated GPUs.
几何着色器(geometry shader)是运行在每一个图元上(例如:三角形,线段,点),并且可以选择抛弃它或者输出比输入进来的图元更多的图元。这类似于细分着色器,但是更灵活。但是在当今的应
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3042
3042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









