







强强化学习基础:强化学习分类,强化学习表示,值函数,策略迭代/值迭代, 主要的强化学习技术(蒙特卡洛学习/时间差分学习,DQN.REINFORCE,策略梯度/PPO/AC/A2C/TRPO)
策略梯度法问题和优化
引用GAE论文的观点,策略梯度法存在的两个方面问题:
- 样本利用率低,由于样本利用率低需要大量采样;
- 算法训练不稳定,需要让算法在变化的数据分布中稳定提升;
目前比较常用的四种置信域方法TRPO、ACER、ACKTR、PPO,就是围绕策略梯度法的上述两方面问题进行改进和优化。
参考:置信域方法总结——TRPO、ACER、ACKTR、PPO

一 置信域策略梯度优化TRPO(Trust Region Policy Optimization)
策略梯度算法即沿着梯度方向迭代更新策略参数 。但是这种算法有一个明显的缺点:
当策略网络沿着策略梯度更新参数,可能由于步长太长,策略突然显著变差,进而影响训练效果。
针对以上问题,考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到某种策略性能的安全性保证,这就是信任区域策略优化(trust region policy optimization,TRPO)算法的主要思想。
它通过约束策略更新的步幅,防止策略的剧烈变化,从而提高训练的稳定性和效率。
参考:TRPO论文推导
1.1 重写η(π) ——写成增量式
TRPO有2种变体:
single-path:就是我们用来学习非线性策略π \piπ的model-free算法。
vine:仅仅用于仿真。
这篇论文中开始将RL的目标——期望累计奖励,用符号η(π)表示:
我们通常用值函数来表示目标:

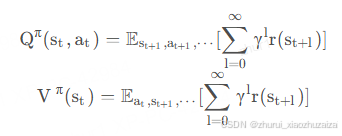
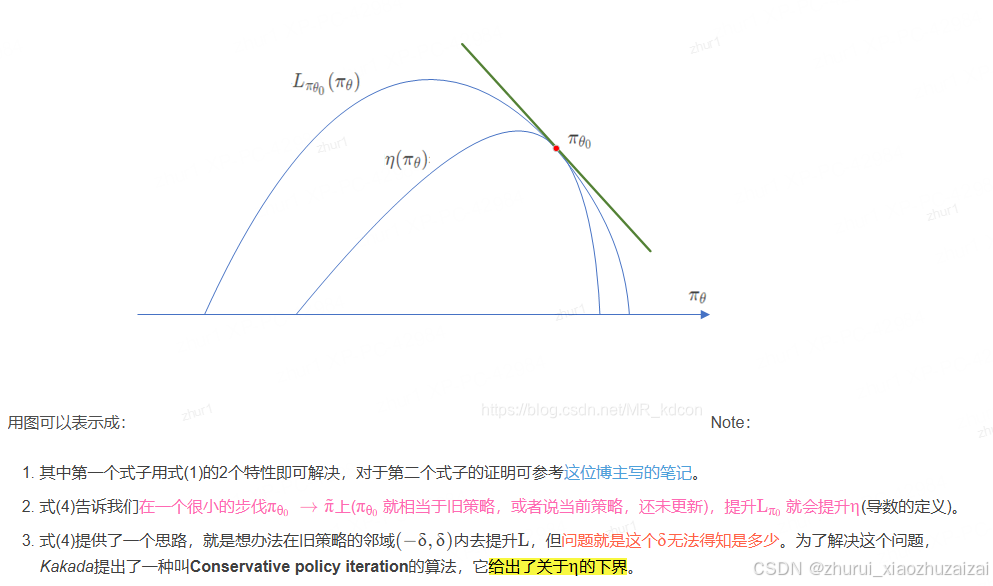
TRPO算法的核心就是去考虑如何学习一个策略从而让性能度量J单调不减。那么一个很直观的思想就是将新策略的性能度量
J( π~)拆成前一个时间步旧的性能度量J(θ)加上某个东西G。即J(π ~)=J(π)+G。那么如果每次更新都能保证G非负,就能保证策略的单调性。那么其实这个等式是存在的:
A 为优势函数,我们在A2C、Dueling-network中都遇到过,满足:
上述式子还有2个特性,根据《Sutton强化学习》有



式(1)告诉我们:新旧策略的回报差是存在的,它等于
显然这个回报差可能正也可能负。
将新旧策略回报差利用“多变量展开”:
注意:



1.2 进一步改写 η(π)——显式的写出 s 和 a


1.3 第一次近似与证明

证明1

证明2




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









