






【惊呆了!】你居然还在用flatten方式进行timing signoff
文章右侧广告为官方硬广告,与吾爱IC社区无关,用户勿点。点击进去后出现任何损失与社区无关。
随着工艺制程的不断升级,芯片的规模也是越来越大了。以 14nm 违例,一个中等规模的 chip,整个 design 的 instance 可达到 6000 万。这样的设计,如果走 flatten flow,对于数字后的工程师的后端实现来说,完全不可能。一方面是这么大规模的 design,你的 server 是否能跑得起来?另外一方面,即使能够 run 下去,run time 你是否能接受(比如跑一个 place 要一个月)?
工具的 run time 主要取决于以下几方面:
-
timing 是否比较 critical
-
congestion 是否严重
-
面积是否严重不足
Hierarchical design flow 的优点
-
数字后端 P&R(Place&Route)实现时能够有效控制好每个子模块的实现过程,因为 run time 可以大量减少,而且不同子模块可以并行实现
-
将设计中新添加的模块单独切出来,预防因为新设计模块存在 bug 而导致大规模 block 重做,大大降低项目风险
-
解决绕线问题(为什么?大家好好思考,涉及 logical hierarchical 和 physical hierarchical 的概念)
-
寄生参数抽取(RC Extraction)时间大量减少
-
加速 Timing Signoff 进程
第一,将一个含有 5000 万 instance 的 design,进行 flatten timing signoff 时,Prime time 本身的 runtime 会非常慢,而且极度消耗内存(比如 14nm timing signoff 的 corner 也比较多)。所以,很多公司都采用 hierarchical flow 进行 timing signoff。based hierarchical flow 进行 timing signoff 时,各个子模块可以单独进行 timing signoff。
第二,由于可以将设计中比较大的子模块,单独进行 timing signoff,所以在 top level signoff 的时候,可以不必等各个子模块 timing 都差不多了再进行 flatten。
Hierarchical design flow 的缺点:
- Interface timing buget
P&R 实现时,需要考虑 IO 接口的 timing(预留 timing buget),防止因接口相关的逻辑没有进行充分的优化而导致的 timing violations。至于预留多少 timing margin,留给大家思考。这个技能是数字后端工程师最基本的技能之一。各大公司的面试经常也会问到这个问题。
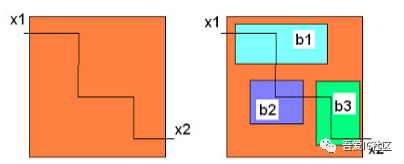
图 1 各个子模块接口 timing
- RC 准确性
第一,dummy 的插法往往是 flatten 抽取出来的。如果是 hierarchical 的 rc extraction,模块接口处的 RC 是否可信
第二,相邻子模块边界处的 RC 是否准确
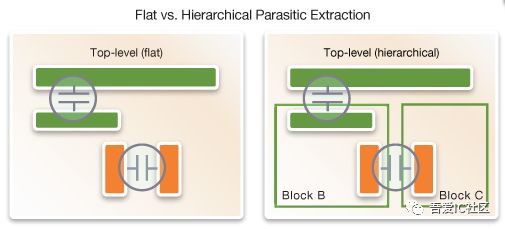
图 2 Hierarchical RC 抽取
- Timing 的准确性
比如一个 chip 中,有的模块频率要求比较低,我们想用 7Track 的 libray 来实现。而对频率要求比较高的模块,我们则可以用 9Track 甚至 12Track 来实现。
那么问题来了,如果有一条 path,startpoint 是 7Track 中的,而 endpoint 是 9Track 中的。你们觉得应该如何处理呢?
如果 top level 的 clock tree 上存在 crosstalk(等效于之前介绍过的 common clock tree 上存在 crosstalk,分析对 setup,hold 的影响),子模块 timing 的准确性是否可信?
其实现在很多公司都是采用 hierarchical flow 来设计实现,并进行 timing signoff 的,大大缩短了整个数字 IC 设计周期。但是前提是需要处理好以上所列的几大问题。处理好了,其实也是那么一回事。而且整个 timing signoff 过程就变成流水线工作了。
好了,今天的内容分享就到这里。如果你比较有心,我相信你会想着整理一份S家对应命令汇总,那就赶紧去做吧!如果小编的分享对你有所帮助,帮忙点击“在看”并转发给你的朋友,算是对小编的一点帮助。
小编知识星球简介(如果你渴望进步,期望高薪,喜欢交流,欢迎加入):
在这里,目前已经规划并正着手做的事情:
- ICC/ICC2 lab的编写
- 基于arm CPU的后端实现流程
- 利用ICC中CCD(Concurrent Clock Data)实现高性能模块的设计实现
- 基于ARM 四核CPU 数字后端Hierarchical Flow 实现教程
- 时钟树结构分析
- 低功耗设计实现
- 定期将项目中碰到的问题以案例的形式做技术分享
- 基于90nm项目案例实现教程(ICC和Innovus配套教程)
- 数字IC行业百科全书
吾爱IC社区知识星球星主为公众号”吾爱IC社区”号主,从事数字ic后端设计实现工作近八年,拥有55nm,40nm,28nm,22nm,14nm等先进工艺节点成功流片经验,成功tapeout过三十多颗芯片。
这里是一个数字IC设计实现高度垂直细分领域的知识社群,是数字IC设计实现领域中最大,最高端的知识交流和分享的社区,这里聚集了无数数字ic前端设计,后端实现,模拟layout工程师们。
在这里大家可以多建立连接,多交流,多拓展人脉圈,甚至可以组织线下活动。在这里你可以就数字ic后端设计实现领域的相关问题进行提问,也可以就职业发展规划问题进行咨询,也可以把困扰你的问题拿出来一起讨论交流。对于提问的问题尽量做到有问必答,如遇到不懂的,也会通过查阅资料或者请教专家来解答问题。在这里鼓励大家积极发表主题,提问,从而促进整个知识社群的良性循环。每个月小编会针对活跃用户进行打赏。
最重要的是在这里,能够借助这个知识社群,短期内实现年薪百万的梦想!不管你信不信,反正已经进来的朋友肯定是相信的!相遇是一种缘分,相识更是一种难能可贵的情分!如若有缘你我一定会相遇相识!知识星球二维码如下,可以扫描或者长按识别二维码进入。目前已经有680位星球成员,感谢这680童鞋的支持!欢迎各位渴望进步,期望高薪的铁杆粉丝加入!终极目标是打造实现本知识星球全员年薪百万的宏伟目标。

相关文章推荐(不看保证后悔)
合理的时钟结构能够加速 Timing 收敛(时钟树综合中级篇)
【机密】从此没有难做的 floorplan(数字后端设计实现 floorplan 篇)
听说 Latch 可以高效修 hold 违例(Timing borrowing 及其应用)
秒杀数字后端实现中 clock gating 使能端 setup violation 问题
教你轻松调 DCT 和 ICC 之间 Timing 与 Congestion 的一致性
Scan chain reordering 怎么用你知道吗?
数字后端实现时 congestion 比较严重,你 hold 得住吗?
Final netlist release 前,你应该做好哪些工作?
深入浅出讲透 set_multicycle_path,从此彻底掌握它
数字后端实现时 congestion 比较严重,你 hold 得住吗?
时钟树综合(clock tree synthesis)基础篇
好了,今天的码字就到这里了,原创不容易,喜欢的可以帮忙转发和赞赏,你的转发和赞赏是我不断更新文章的动力。小编在此先谢过!与此同时,吾爱 IC 社区(52-ic.com)也正式上线了。吾爱 IC 社区(52-ic.com)是一个专业交流和分享数字 IC 设计与实现技术与经验的 IC 社区。如果大家在学习和工作中有碰到技术问题,欢迎在微信公众号给小编留言或者添加以下几种联系方式进行提问交流。

打赏的朋友,请长按下方二维码,识别小程序进行打赏,欢迎砸钱过来!小编晚饭能不能加个鸡腿,全靠它了,呵呵!

作者微信:
















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









