










Qualcomm Cloud AI SDK 用户指南(8)
2.2 编译模型
编译准备好的ONNX文件会生成一个QPC,可以在Cloud AI设备上加载和执行。为了根据用户对吞吐量和延迟的要求从设备获得最佳性能,需要使用正确的参数进行编译。调整性能涉及如何导出最佳编译参数。
2.2.1 编译模型
AI/ML 模型编译步骤将以其他格式(首选 ONNX)定义的预训练模型编译为 QPC(Qaic 程序容器)格式。这是必需的,因为云 AI 设备使用这种格式来运行推理。
预训练模型可以通过三种方式编译:
- 使用 qaic-exec(Apps SDK 附带的二进制可执行文件)。此 CLI 工具支持所有最新的编译器标志。
- 使用高级 Python API
- 使用 C++ API
将模型编译为 QPC 格式之前:
- 使用 ONNX 格式作为输入。
- 尝试将原始模型压缩为单个文件 ONNX 格式。
使用 qaic-exec 编译
qaic-exec(QAic执行器)是一个CLI工具,用于编译模型。qaic-exec是一个具有许多参数的复杂工具。
qaic-exec CLI 位于/opt/qti-aic/exec/qaic-exec
教程和模型文件夹 (#FIXME) 提供了几个qaic-exec使用示例。
help/usage 命令提供了广泛的参数列表及其用法描述。
/opt/qti-aic/exec/qaic-exec -h
/opt/qti-aic/exec/qaic-exec --usage
很少有经常使用的参数被额外解释:
-m=<path>;, -model=<path> # specifies the path of input ONNX model
-onnx-define-symbol=<sym, value> # defines the names and values of the ONNX symbols that needed to be passed into the QPC.
For example
-onnx-define-symbol=sequence,10 # For single symbol
-onnx-define-symbol=sequence,10 -onnx-define-symbol=batch_size,8 # For more than one symbol
-aic-num-cores=<numCores>
The Cloud AI cards can have a number of Neural Signal Processing cores (a.k.a AI cores) based on the SKU. The Inferencing workload can be distributed among different cores, so that they can execute concurrently and can produce more efficient inferencing. Refer to Tune Performance section on how to set this value.
-ols= <1,2,4,8.. numCores>
Factor to increase splitting of network operations for more fine-grained parallelism. Refer to Tune Performance section on how to set this value.
-mos= <1,2,4,8.. numCores>
Effort level to reduce on-chip memory usage. Refer to Tune Performance section on how to set this value.
-multicast-weights
Reduce DDR bandwidth by loading weights used on multiple-cores only once and multicasting to other cores.
-convert-to-fp16
mandatory flag, ensures that compiled QPC executes all floating point computations on the AIC 100 device is 16-bit precision.
-batchsize=<numBatch>
batchsize refers to number of number of input samples that can be passed to the model during inferencing. Ideally a careful selection of batch size can facilitate better parallel processing and hence a better throughput from the device. Tune performance section expands on batchsize selection.
-stats-batchsize=<numBatch>
Set this value to numBatch. Used in performance statistics reporting
-aic-binary-dir=<path>
specifies the output QPC path.
-aic-hw
Mandatory flag. This flag enables the QPC to be run on hardware.
-compile-only
Mandatory flag, allows to only compile and produce the QPC format file for the model and does not run the model with random data. Use qaic-runner CLI to execute the QPC.
-aic-hw-version=2.0
The version string must be passed as "2.0" which is the .
-aic-profiling-type=<stats|trace|latency>
Used in device level profiling. Refer to Profiler notebook under tutorials.
qaic-exec还可以用于转储跨 onnx、tensorflow、pytorch、caffe 或 caffe2 ML 框架支持的运算符。
/opt/qti-aic/exec/qaic-exec -operators-supported=<onnx | tensorflow | pytorch | caffe | caffe2>
2.2.2 调整性能
调整性能
本节讨论云 AI 平台的吞吐量(每秒推理次数)和延迟(每次推理时间)调整技术。
关键性能参数
核心、批量大小、实例(也称为激活)和集合大小是需要调整以获取最佳性能的关键性能参数。
- 核心数和批量大小是编译参数。
- Instances 和 Set-size 是运行时参数。
核
云 AI 平台包含多个 AI 核心,具体取决于 SKU。每个 AI 核心都包含一个或多个标量、向量和张量引擎,这些引擎提供丰富的指令集来加速 ML 操作。可以为一个或多个 AI 核心编译模型。
实例(又名激活)
实例是指在一组 AI 核心上执行推理的模型的编译二进制文件。假设 bert-large 是为 2 个 AI 核心编译的,而 Cloud AI 设备有 14 个 AI 核心。每个实例将在 2 个 AI 核心上运行。最多可以并行执行 7 个实例(在 14 个 AI 核心上)。
批量大小
批量大小是指实例推断的输入元素的数量。
设定大小
Set-size 表示每次激活可以在主机上排队的推理数量。Set-size 通过管道推理帮助隐藏主机端开销。需要传输大量输入/输出数据(从/向主机和设备)或在主机上进行某些预处理/后处理的模型可以看到吞吐量随着集大小的增加而增加,直到达到某个值,超过该值设备利用率就会增加无法改进。
实例和批量大小
实例数量和批量大小的乘积提供了可以在单个 Cloud AI 设备上并行推断的总输入样本。
核心和实例
“实例数量”和“每个实例使用的AI核心数量”的乘积不能超过云AI平台/卡上可用的AI核心总数。
优化以获得最佳吞吐量/最短延迟
模型配置器是一种硬件在环测试工具,可运行各种配置并确定模型的最佳配置。模型配置器工具提供两种工作流程 - 最高吞吐量和最低延迟。
请参阅性能调优教程 #1 - CV和教程 #2 - NLP,了解性能调优的分步演练。
请参阅性能调整教程,了解优化最佳吞吐量和最小延迟的工作流程。
对于最小延迟配置,batch-size 应设置为 1。将大小设置为 1 可提供最小延迟。
对于需要一些主机端预处理的模型(例如 CV 模型),较高的集合大小可能会显着提高吞吐量,但延迟会略有增加。
一般性能调优观察
现在我们已经介绍了关键的性能调整参数,下面有一些一般性的观察结果可以帮助开发人员编译模型以获得最佳性能。
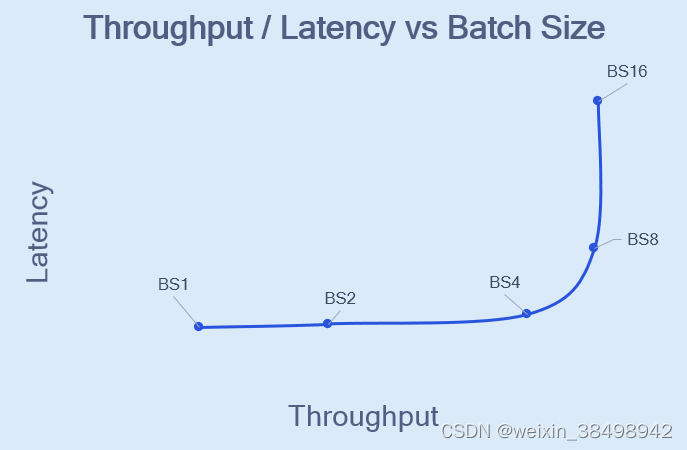
吞吐量和延迟与批量大小
对于固定数量核心上的实例,将批量大小 (BS) 从 1 增加通常会提高吞吐量。增加超过最佳 BS 将导致性能下降。
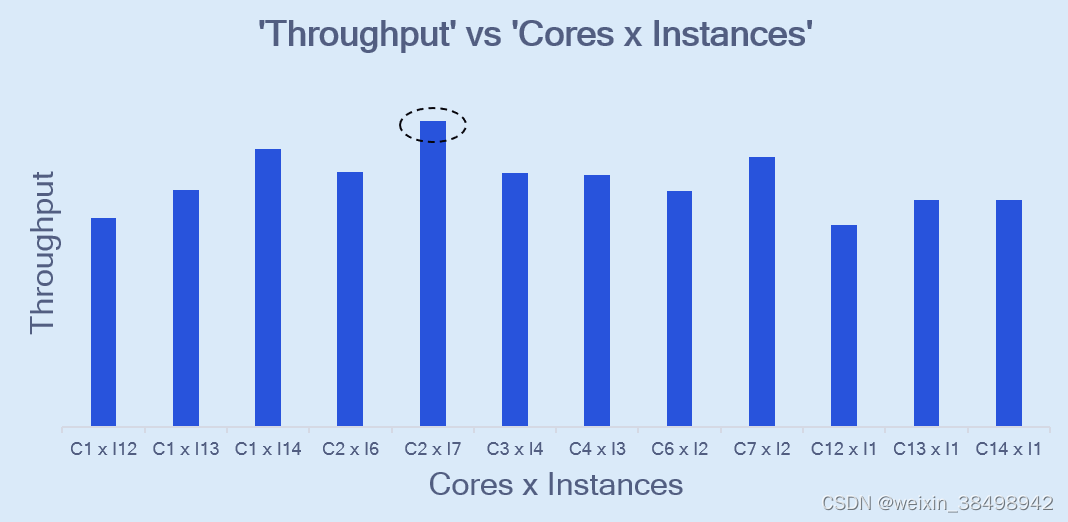
吞吐量与核心和实例
根据设备上可用的 AI 核心总数,存在一些核心和实例组合,其中一些组合比其他组合提供更好的性能。
我们以具有 14 个 AI 核心的 Cloud AI 100 标准 SKU 来说明这一点。下图显示了不同核心和实例组合的吞吐量。批量大小是固定的。例如:C1 x I12 表示在 1 个核心上编译的模型和在 12 个核心上部署的 12 个实例。

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









