






输入图像格式
输入图像
除了转换模型之外,高通神经处理 SDK 还要求输入图像采用可能与源框架不同的特定格式。
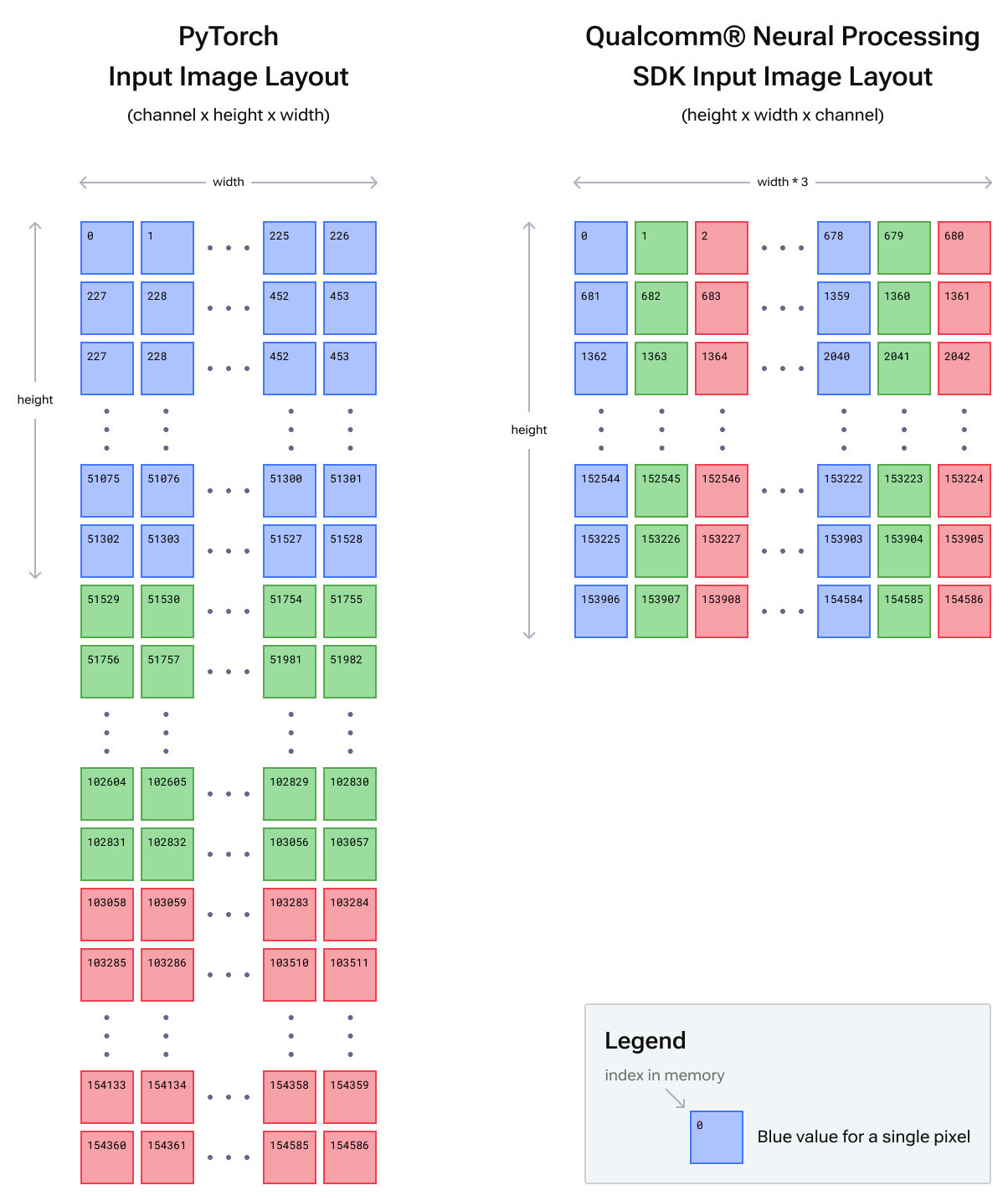
在某些框架(例如 Pytorch)中,图像可能呈现为形状为 的张量 ,其中宽度是变化最快的维度,其次是高度,然后是颜色通道。这意味着第一个颜色通道的所有像素值在内存中是连续的,然后是下一个颜色通道的所有像素值,依此类推。(batch x channel x height x width)
在高通神经处理 SDK 中,图像必须呈现为形状为 的张量 ,其中通道是变化最快的维度。这意味着单个像素所有颜色通道的值在内存中是连续的,然后是下一个像素的所有颜色值,依此类推。(batch x height x width x channel)
如果批次维度大于 1,则必须手动将各个图像连接在一起形成每个批次的单个文件。
请参见下图,了解两个输入图像内存布局的直观表示。
笔记:
推理时使用的通道阶必须与训练时使用的通道阶一致。例如,某些框架下训练的 ImageNet 模型可能要求通道阶为 BGR。
Imagenet 模型的输入图像
一些框架(例如 bvlc_alexnet、bvlc_googlenet 等)中的 ImageNet 模型使用 BGR 图像(蓝色像素在前,绿色像素在后,红色像素在前)进行训练。推理引擎必须以相同的通道顺序提供像素值。
MNIST 模型的输入图像
某些框架中的 MNIST 模型(例如 lenet)需要尺寸为 28x28 的单通道灰度图像。需要注意的是,虽然只有一个通道,但这些框架(1x1x28x28)以及 高通神经处理 SDK 仍然需要 4 维的输入张量(1x28x28x1)。
输出
Pytorch 和 高通神经处理 SDK 之间的示例输出保持不变:对于批次中的每张图像,包含每个类别的概率的一维张量。
对于 Imagenet 模型(例如 bvlc_alexnet),这是 1000 个 Imagenet 类的大小为 1000 的张量。
如果模型的批量维度大于 1,则各个输出张量将沿着批量维度连接在一起。

















 6116
6116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









