






使用 TFLite 进行图像分割和编码
该用例使用 deeplabv3_resnet50 TFLite 模型来合成语义分割和原始视频流,对该数据流进行编码,然后在 MP4 容器中对其进行多路复用。
运行用例:
gst-launch-1.0 -e --gst-debug=2 \
qtiqmmfsrc name=camsrc ! video/x-raw\(memory:GBM\),format=NV12,width=1280,height=720,framerate=30/1,compression=ubwc ! queue ! tee name=split \
split. ! queue ! qtivcomposer name=mixer sink_1::dimensions="<1920,1080>" sink_1::alpha=0.5 ! queue ! video/x-raw\(memory:GBM\),format=NV12,width=1920,height=1080,interlace-mode=progressive,colorimetry=bt601 ! v4l2h264enc capture-io-mode=5 output-io-mode=5 ! h264parse ! queue ! mp4mux ! queue ! filesink location=/opt/video.mp4 \
split. ! queue ! qtimlvconverter ! queue ! qtimltflite delegate=external external-delegate-path=libQnnTFLiteDelegate.so external-delegate-options="QNNExternalDelegate,backend_type=htp;" model=/opt/deeplabv3_resnet50.tflite ! queue ! qtimlvsegmentation module=deeplab-argmax labels=/opt/deeplabv3_resnet50.labels ! video/x-raw,width=256,height=144 ! queue ! mixer.
如需停止用例,可按下 CTRL + C。
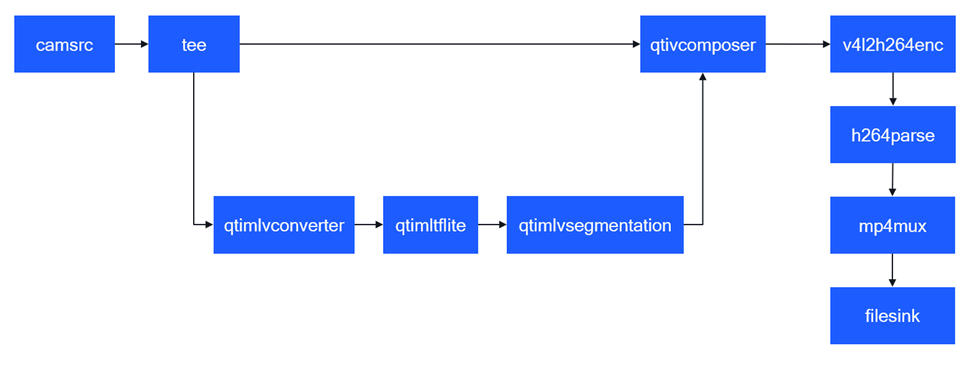
下图显示了用例执行流程:
- 识别来自摄像头源的视频流中的场景。
- 使用 qtivcomposer 合成语义分割和视频流。
- 将数据流编码为 H.264 码流,并在 MP4 容器中对流进行多路复用。
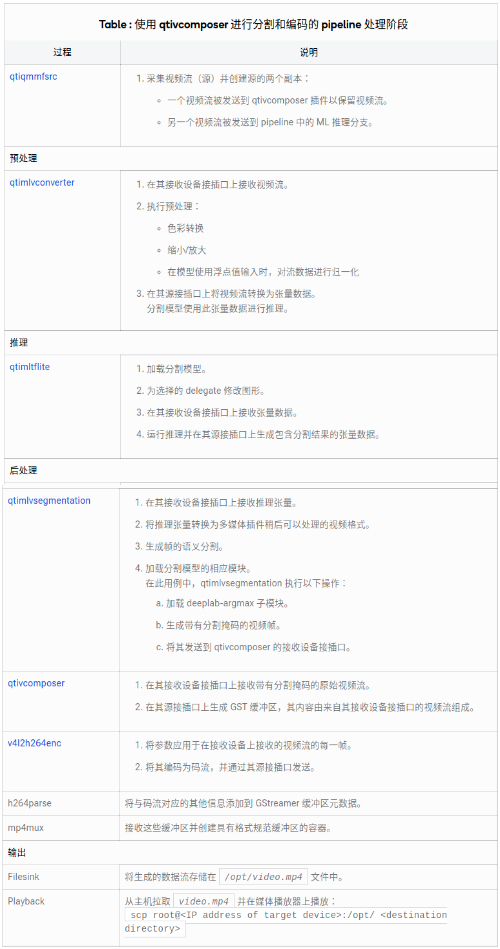
pipeline 执行的顺序处理阶段如下表所示:
使用 TFLite 进行姿态估计和显示
这些用例使用 PoseNet TFLite 模型来处理具有姿态估计的单个摄像头流。
变体 1:使用 qtioverlay 插件应用姿态估计叠加
运行用例:
setprop persist.overlay.use_c2d_blit 2
gst-launch-1.0 -e \
qtiqmmfsrc name=camsrc ! video/x-raw\(memory:GBM\),format=NV12,width=1280,height=720,framerate=30/1,compression=ubwc ! queue ! tee name=split \
split. ! queue ! qtimetamux name=metamux ! queue ! qtioverlay ! queue ! waylandsink fullscreen=true sync=false \
split. ! queue ! qtimlvconverter ! queue ! qtimltflite delegate=external external-delegate-path=libQnnTFLiteDelegate.so external-delegate-options="QNNExternalDelegate,backend_type=htp;" model=/opt/posenet_mobilenet_v1.tflite ! queue ! qtimlvpose threshold=51.0 results=2 module=posenet labels=/opt/posenet_mobilenet_v1.labels constants="Posenet,q-offsets=<128.0,128.0,117.0>,q-scales=<0.0784313753247261,0.0784313753247261,1.3875764608383179>;" ! text/x-raw ! queue ! metamux.
如需停止用例,可按下 CTRL + C。
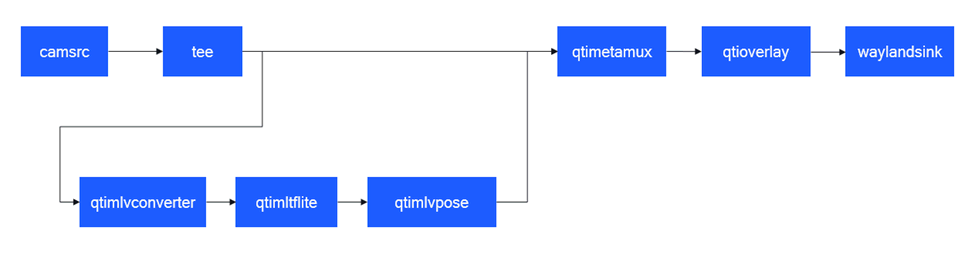
下图显示了用例执行流程:
- 从摄像头源传来的视频流中识别场景中人物的姿态。
- 使用 overlaylib 叠加可用的姿态。
- 显示结果。
pipeline 执行的顺序处理阶段如下表所示:

变体 2:使用 qtivcomposer 混合原始帧与姿态估计掩码
运行用例:
gst-launch-1.0 -e --gst-debug=2 \
qtiqmmfsrc name=camsrc ! video/x-raw\(memory:GBM\),format=NV12,width=1280,height=720,framerate=30/1,compression=ubwc ! queue ! tee name=split \
split. ! queue ! qtivcomposer name=mixer ! queue ! waylandsink fullscreen=true sync=false \
split. ! queue ! qtimlvconverter ! queue ! qtimltflite delegate=external external-delegate-path=libQnnTFLiteDelegate.so external-delegate-options="QNNExternalDelegate,backend_type=htp;" model=/opt/posenet_mobilenet_v1.tflite ! queue ! qtimlvpose threshold=51.0 results=2 module=posenet labels=/opt/posenet_mobilenet_v1.labels constants="Posenet,q-offsets=<128.0,128.0,117.0>,q-scales=<0.0784313753247261,0.0784313753247261,1.3875764608383179>;" ! video/x-raw,format=BGRA,width=640,height=360 ! queue ! mixer.
如需停止用例,可按下 CTRL + C。
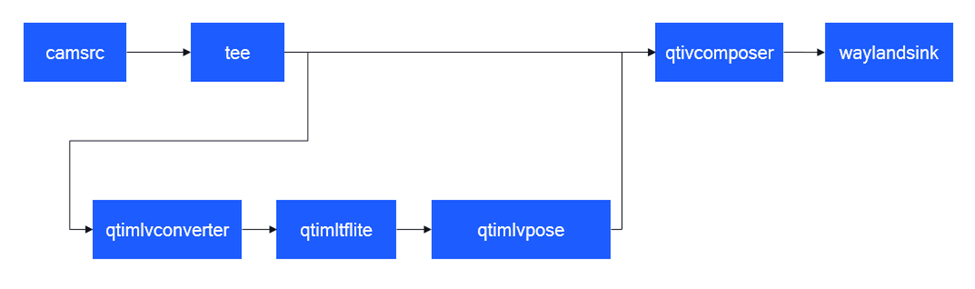
下图显示了用例执行流程:
- 对来自摄像头源的视频流识别场景中人物的姿态。
- 使用 qtivcomposer 合成姿态和视频流。
- 显示结果。
pipeline 执行的顺序处理阶段如下表所示:


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









