






TFLite 模型转换
机器学习框架具有用于存储神经网络模型的特定格式。高通神经处理SDK 通过将各种模型转换为与框架无关的深度学习容器 (DLC)格式来支持这些模型。高通神经处理SDK 运行时使用 DLC 文件来执行神经网络。
可以使用https://www.tensorflow.org/lite/convert#python_api_上的说明将训练好的 Tensorflow 模型转换为 TFLte 模型 (.tflite) 文件
snpe-tflite-to-dlc工具 可将 TFLite 模型转换为等效的 高通神经处理SDK DLC 文件。以下命令可将 Inception v3 TFLite 模型转换为 高通神经处理 SDK DLC 文件。
snpe-tflite-to-dlc --input_network inception_v3.tflite
--input_dim input "1,299,299,3"
--output_path inception_v3.dlc
Inception v3 模型文件可以从https://tfhub.dev/tensorflow/lite-model/inception_v3/1/default/1获取
笔记:
-
要查看当前支持的 TFlite Ops 列表,请参阅Op 支持表。
-
高通神经处理 SDK 和 TFlite Converter 目前仅支持浮点输入数据类型。
-
某些基于 MLIR 的 TFLite 转换器的旧版本存在一些已知问题,可能导致模型加载失败。
PyTorch 模型转换
机器学习框架具有用于存储神经网络模型的特定格式。高通神经处理SDK 通过将各种模型转换为与框架无关的深度学习容器 (DLC)格式来支持这些模型。高通神经处理SDK 运行时使用 DLC 文件来执行神经网络。
snpe-pytorch-to-dlc工具 可将 PyTorch TorchScript 模型转换为等效的高通神经处理SDK DLC 文件。以下命令将 ResNet18 PyTorch 模型转换为高通神经处理SDK DLC 文件。
snpe-pytorch-to-dlc --input_network resnet18.pt
--input_dim input "1,3,224,224"
--output_path resnet18.dlc
训练好的PyTorch模型可以转换为TorchScript模型(.pt)文件,教程位于 Loading a TorchScript Model in C++ — PyTorch Tutorials 2.7.0+cu126 documentation
以下代码可用于将预训练的 PyTorch ResNet18 模型转换为 TorchScript (.pt) 模型。
import torch
import torchvision.models as models
resnet18_model = models.resnet18()
input_shape = [1, 3, 224, 224]
input_data = torch.randn(input_shape)
script_model = torch.jit.trace(resnet18_model, input_data)
script_model.save("resnet18.pt")
笔记:
-
要查看当前支持的 PyTorch Ops 列表,请参阅 Op 支持表。
-
高通神经处理SDK 和 PyTorch Converter 目前仅支持浮点输入数据类型。
ONNX 模型转换
机器学习框架具有用于存储神经网络模型的特定格式。高通神经处理通过将各种模型转换为与框架无关的深度学习容器 (DLC)格式来支持这些模型。高通神经处理SDK 运行时使用 DLC 文件来执行神经网络。高通神经处理SDK 包含一个名为“snpe-onnx-to-dlc”的工具,用于将序列化的 ONNX 格式模型转换为 DLC 格式。
将模型从 ONNX 转换为 DLC
snpe -onnx-to-dlc 工具将序列化的 ONNX 模型转换为等效的 DLC 表示。
使用按照https://github.com/onnx/models/blob/main/validated/vision/classification/alexnet/README.md中的说明获取的 ONNX alexnet 模型 ,以下命令将生成 alexnet 的 DLC 表示:
snpe-onnx-to-dlc --input_network models/bvlc_alexnet/bvlc_alexnet/model.onnx
--output_path bvlc_alexnet.dlc
笔记:
-
有关高通神经处理 SDK 支持的操作、版本和参数的信息,请参阅支持的 ONNX Ops。
-
snpe-onnx-to-dlc 和高通神经处理 SDK 运行时均不支持符号张量形状变量。有关在初始化时调整 高通神经处理 SDK 网络大小的信息,请参阅网络大小调整。
-
通常,高通神经处理 SDK 会根据运行时和构建器参数的需求来确定张量和操作的数据类型。ONNX 模型指定的数据类型通常会被忽略。
-
如果模型包含 ONNX 函数,转换器总是会进行函数节点的内联。
量化模型
每个 snpe - framework -to-dlc 转换工具都会将非量化模型转换为非量化的 DLC 文件。量化需要另一个步骤。snpe -dlc-quantize工具用于将模型量化为支持的定点格式之一。
例如,以下命令将 Inception v3 DLC 文件转换为量化的 Inception v3 DLC 文件。
snpe-dlc-quantize --input_dlc inception_v3.dlc --input_list image_file_list.txt
--output_dlc inception_v3_quantized.dlc
图像列表指定用于量化的原始图像文件的路径。 更多详情请参阅snpe-dlc-quantize 。
该工具要求在模型转换期间将 DLC 输入文件的批次维度设置为 1。通过 在初始化期间调整网络大小,可以将批次维度更改为其他值以进行推理。
有关量化算法的详细信息以及何时使用量化模型的信息,请参阅量化模型与非量化模型。
量化的输入数据
为了正确计算量化参数的范围,需要使用一组有代表性的输入数据作为 snpe-dlc-quantize的输入。
实验表明,在snpe-dlc-quantize的 input_list 中提供 5-10 个输入数据示例 通常就足够了,并且对于快速实验来说绝对实用。为了获得更稳健的量化结果,我们建议为给定的模型用例提供 50-100 个代表性输入数据示例,而不使用训练集中的数据。理想情况下,代表性输入数据集应包含代表/生成模型所有输出类型/类别的所有输入数据模态,最好每个输出类型/类别都有多个输入数据示例。
在“支持的网络层”中,我们列出了保证成功量化的层/操作。对于其他层/操作,我们无法提供任何保证。
HTP 上 DSP 运行时的离线图形缓存
在搭载 Hexagon 张量处理器 (HTP) 的目标设备上,高通神经处理 SDK DSP 运行时支持离线图缓存功能,这有助于在 Linux x86-64 平台上准备后端图。这有助于缩短初始化时间,并在执行模型时直接将缓存加载到设备上。
高通神经处理 SDK 用户的工作流程变化:
-
使用 snpe-<framework>-to-dlc 进行模型转换
-
使用 snpe-dlc-quant 进行模型量化
-
使用 snpe-dlc-graph-prepare 进行模型离线图缓存准备
-
使用 snpe-net-run 或自定义应用程序在目标上执行模型
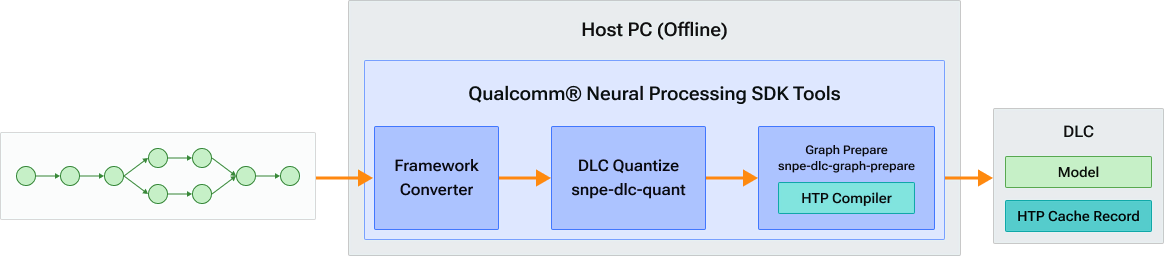
上图中的 DLC 量化包含两个步骤,即首先量化模型,然后生成离线缓存。snpe -dlc-graph-prepare工具用于在通过snpe-dlc- quant工具 量化 DLC 后为 高通神经处理 SDK HTP 运行时生成 DLC 缓存 blob。snpe -dlc-graph-prepare工具还可以与浮点模型一起使用,为 HTP FP16 运行时生成缓存。
例如,以下命令将 Inception v3 DLC 文件转换为量化的 Inception v3 DLC 文件,并生成 HTP 图形缓存并存储在 DLC 中。
snpe-dlc-quant --input_dlc inception_v3.dlc --input_list image_file_list.txt --output_dlc inception_v3_quantized.dlc
snpe-dlc-graph-prepare --input_dlc inception_v3_quantized.dlc --output_dlc inception_v3_quantized_cache.dlc --htp_socs sm8750
运行snpe-dlc-graph-prepare会触发在给定模型上生成 HTP 图,并将生成的缓存添加到 DLC 中的 HTP 记录中。如果 HTP 编译器无法处理/编译网络的任何部分, snpe-dlc-graph-prepare会发出错误消息。
snpe-dlc-graph-prepare可以帮助使用相同/不同版本的 高通神经处理SDK 快速重新准备图形的离线缓存,而无需重新执行量化步骤,如果输入数据集很大,这可能需要花费大量时间。
类似地,snpe-dlc-quantize工具使用 enable_htp 选项为高通神经处理 SDK HTP 运行时生成 DLC 缓存 blob,作为量化过程的一部分。
例如,以下命令将 Inception v3 DLC 文件转换为量化的 Inception v3 DLC 文件,并生成 HTP 图形缓存并存储在 DLC 中。
snpe-dlc-quantize --input_dlc inception_v3.dlc --input_list image_file_list.txt --output_dlc inception_v3_quantized.dlc --enable_htp --htp_socs sm8750
注意:
-
离线准备的图形缓存和运行时的 SNPE 对象必须指定相同的图形输出。如果运行时相同的图形输出与准备图形中指定的不同,则准备图形将被视为无效并被忽略。然后,图形准备将在运行时完成(称为在线准备),从而拒绝 DLC 中的缓存 blob,在这种情况下,初始化时间会明显增加。
-
为了启用 CPU 回退以进行离线准备,CPU 子网之前的 DSP 子网需要将输入到后续子网的所有输出张量标记为图形输出。
-
图形输出指定给 snpe-dlc-graph-prepare 工具,如下所示:
-
输出层名称 (--set_output_layers),在这种情况下,该层的所有输出张量都被视为图输出。或者
-
如果不是该层的所有输出都被视为图形输出,则输出张量名称(--set_output_tensors)
例如,如果存在一个中间层,该中间层的一个(或多个)输出张量应被视为图输出。默认情况下,该工具将选择序列化图中最后一层的所有输出张量。
-
-
也可以使用 snpe-dlc-graph-prepare 的可选 input_list 来指定图的输出。为了指定 snpe-dlc-graph-prepare 的输出层名称,需要在 input_list 参数中添加一个以“#”开头的特殊行,用于指定层名称:
#<output_op_name>[<space><output_op_name>]*或者,要为 snpe-dlc-graph-prepare 指定输出张量名称,需要在 input_list 参数中添加一个以“%”开头的特殊行,用于指定输出张量名称:
%<output_tensor_name>[<space><output_tensor_name>]* -
要在运行时指定输出张量名称:
-
对于snpe-net-run,必须使用命令行上的 --set_output_tensors 参数传递名称语法:[ --set_output_tensors=<val> ] 指定执行后要输出的张量逗号分隔列表。
-
使用 API 时 - 使用此 SNPE Builder API Snpe_SNPEBuilder_SetOutputTensors() / SNPEBuilder::setOutputTensors() 指定相同的输出张量名称。
-
-
为特定 SoC 创建的缓存记录可以在另一个 SoC 上运行。这种互操作性取决于 VTCM 的大小以及已准备并正在运行的 SoC 的 DSP 架构。HTP 离线缓存兼容性遵循以下经验规则:
-
为较新 DSP Arch 生成的缓存无法在较低 DSP Arch 的 SoC 上运行。例如,为 v69 设备(例如 sm8450)生成的缓存记录无法在 v68 设备(例如 sm8350)上运行,即使缓存已使用 2MB vtcm 准备。
-
对于同一个 DSP Arch,如果为一个 SoC 准备的缓存的 VTCM 小于或等于正在运行的 SoC 的 VTCM,则该缓存可以在另一个 SoC 上运行。
-
为 v68 或 v69 设备生成的缓存将无法在 v73 设备上运行。
-
-
snpe-dlc-graph-prepare工具中的 --optimization_level 命令行选项具有一些固有的权衡和不确定性行为:
-
默认优化级别为 2。更高的优化级别会导致更长的离线准备时间,但会产生更优化的图形,从而加快大多数图形的执行时间。
-
在大多数情况下,级别 3 应该提供更优化的图表,但在某些情况下也可能导致不太优化的图表。
-
级别 3 可能会产生更大的 HTP 离线缓存记录大小,因此可能会导致初始化时间的缩短。
-
-
使用 snpe-dlc-quantize 进行离线图形准备的功能未来将被弃用。目前,snpe-dlc-quantize 用于支持旧版工作流程。建议迁移到 snpe-dlc-graph-prepare 进行离线 HTP 图形缓存 Blob 准备。
-
请注意,旧式 HTA SOC 的 AIP 运行时不支持输出张量名称。
-
可以使用 –input_name 和 –input_dimensions 参数或使用Snpe_SNPEBuilder_SetInputDimensions API来缓存已调整大小的网络。缓存记录对其准备的输入维度集很敏感。如果使用不同的输入维度准备,则具有相同记录标识符的多个缓存记录可能会共存。在执行期间,仅当执行期间的输入维度与用于准备缓存记录的维度匹配时,才可以使用缓存记录。这也适用于使用网络运行参数(–input_name 和 –input_dimensions)以及用于调整输入张量维度的 API(Snpe_SNPEBuilder_SetInputDimensions API)进行在线准备。
-
例如,假设一个网络有一个输入,其原始尺寸为 1x3x4x5。如果用户在缓存准备期间将此输入的大小调整为 2x3x4x5,并在未将该输入的大小调整为 2x3x4x5 的情况下尝试后续运行推理,则此原本兼容的缓存记录将因输入尺寸不匹配而被拒绝。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









