










废话不多说,直接先上全局注意力机制的模型结构图。
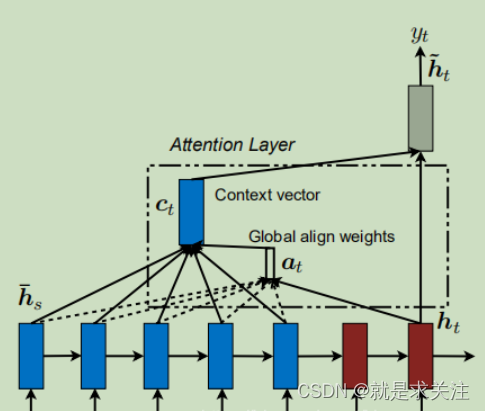
如何通过Global Attention获得每个单词的上下文向量,从而获得子句向量呢?如下几步:

代码如下所示:
x = Embedding(input_dim = nb_tokens, input_length = s_length, output_dim = latent_dim, embeddings_regularizer = keras.regularizers.l2(.001))(inp)
hs = LSTM(64, return_sequences = True, dropout = 0.2, recurrent_dropout = 0.2)(x) 代码如下所示:
代码如下所示:
att = K.expand_dims(K.softmax(K.squeeze(K.tanh(K.dot(hs,self.weight) + self.bias), axis=-1)), axis=-1)
ct=K.sum(hs*att, axis=1)完整Global Attention的代码如下:
class Attention(Layer):
def __init__(self,**kwargs):
super(Attention,self).__init__(**kwargs)
def build(self,input_shape):
self.weight = self.add_weight(name="watt", shape=(input_shape[-1], 1), initializer="normal")
self.bias = self.add_weight(name="batt", shape=(input_shape[1], 1), initializer="zeros")
super(Attention, self).build(input_shape)
def call(self,x):
att = K.expand_dims(K.softmax(K.squeeze(K.tanh(K.dot(x,self.weight) + self.bias), axis=-1)), axis=-1)
return K.sum(x*att, axis=1)
def compute_output_shape(self,input_shape):
return (input_shape[0], input_shape[-1])
def get_config(self):
return super(Attention,self).get_config()
因此,Global Attention模型结构图可以细化为如下:
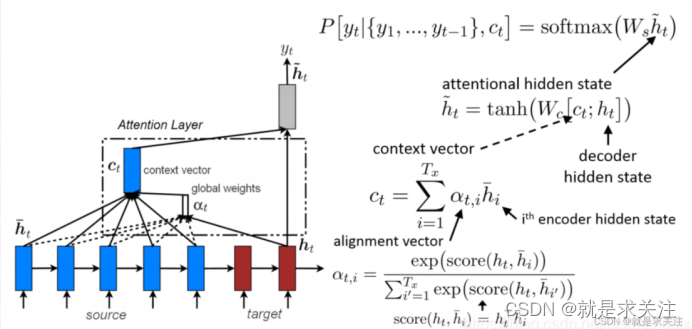
上述公式的含义如下:

其中,和
的关系为:
在LSTM模型中,依次输入一句话中的各个单词的词向量,由LSTM的结构可知,每一个时刻s(每输入一个单词)都会得到一个hidden state ,当到达最后一个时刻t时,会得到target hidden state
。在之前的做法中,只会用到LSTM最终产生的
,而LSTM中间产生的一系列
并不会被用上。这就会产生一些问题:
模型对于一句话中的每个单词都是“一视同仁”的,但当人在读一句话的时候,往往对于某些关键的单词会给予更多的关注。LSTM是长短时记忆网络,其中包含的遗忘门,对于先进入网络的单词,忘记的程度更大,所以该网络更加倾向于记住后输入网络的单词,也就是说得到的向量会过多地关注一句话中结尾的单词
而使用Gobal Attention的目的:是为了在生成上下文向量(也可以认为是句向量)时将所有的hidden state都考虑进去。Attention机制认为每个单词在一句话中的重要程度是不一样的,通过学习得到一句话中每个单词的权重。即为关注重要特征,忽略无关特征。
接下来,如何运用上述Global Attention的代码呢?
上面已经封装了Global Attention的代码,可以直接进行调用。调用方法和形式如下:
x = LSTM(64, return_sequences = True, dropout = 0.2, recurrent_dropout = 0.2)(x)
x = Attention()(x) 为了验证其对LSTM模型的提升效果,我们在亚马逊商品评论数据(amazon_cells_labelled.txt)
上进行了实验。搭建的模型结构如下所示:
x = Embedding(input_dim = nb_tokens, input_length = s_length, output_dim = latent_dim, embeddings_regularizer = keras.regularizers.l2(.001))(inp)
x = LSTM(64, return_sequences = True, dropout = 0.2, recurrent_dropout = 0.2)(x)
x = Attention()(x)
out = Dense(1, activation='sigmoid')(x) #Our output neuron for the sentiment analysis.
model = Model(inp, out)
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.summary()
train_attention_history = model.fit(x = text_pad, y = df[1], batch_size = 64, epochs = 15,
verbose = 1, shuffle = True, validation_split=0.2)
plt.plot(train_no_attention_history.history["val_acc"])
plt.plot(train_attention_history.history["val_acc"], color="red")#红色为加注意力机制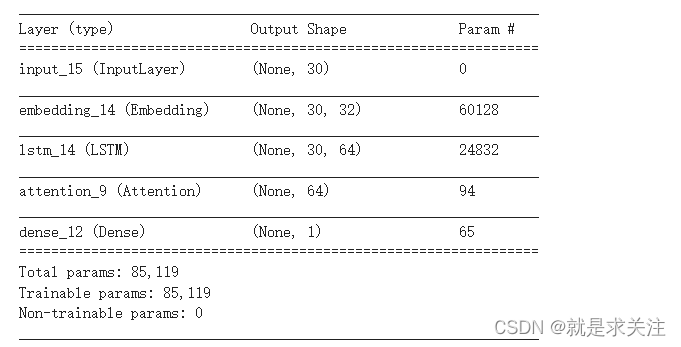
为了加快训练速度,我们直接采用one-hot进行嵌入词向量特征。得到的实验结果与传统LSTM模型准确率对比如下所示:(红色为加注意力机制)
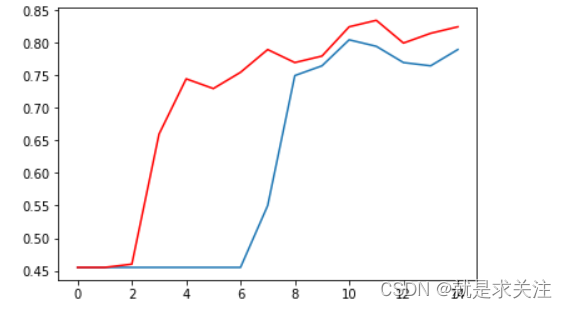
我们看到带有Global Attention(红色)的模型能够更快地捕获词特征和语义特征分布并取得更好的分类准确率。
完整代码:联系QQ:525894654;点击添加群:正在跳转
代码链接:一文读懂——全局注意力机制(globalattention)详解与代码实现-深度学习文档类资源-CSDN下载
参考文献:
1.NLP中的全局注意力机制(Global Attention)
2.Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











