









神经网络滑模控制
前面介绍的万能逼近原理中,主要的万能逼近器有:多项式函数逼近器、神经网络逼近器、T-S模糊系统。学习文献[1]后,对神经网络滑模控制进行介绍和总结。
文献[1]第九章介绍:
如果被控对象的数学模型已知,滑模控制器可以使系统输出直接跟踪期望指令,但较大的建模不确定性需要较大的切换增益,这就造成了抖振,抖振是滑模控制中难以避免的问题。
将滑模控制结合神经网络逼近用于非线性系统的控制中,采用神经网络实现模型未知部分的自适应逼近,可以有效降低模糊增益 (?) 。神经网络自适应律通过Lyapunov方法导出,通过自适应权重调节,保证整个闭环系统的稳定性和收敛性。
RBF(Radial Basis Function, 径向基函数)神经网络具有良好的泛化能力,网络结构简单,避免不必要的和冗长的计算,能在一个紧凑集和任意精度下,逼近任何非线性函数。
神经网络控制策略的优点:
- 神经网络对任意函数具有学习能力,神经网络的自学习能力可避免在传统自适应控制理论中占据重要地位的复杂数学分析。
- 针对传统控制方法不能解决的高度非线性控制问题,多层神经网络的隐含层神经元采用了具有非线性映射功能的激活函数,这种映射可以逼近任意非线性函数,为解决非线性控制问题提供了有效的解决途径。
- 传统自适应控制方法需要模型先验信息来设计控制方案,如需要建立被控对象的数学模型。由于神经网络的自学习能力,控制器不需要许多系统的模型和参数信息。因此,神经网络控制可以广泛应用于解决具有不确定模型的控制问题。
- 采用神经元芯片或并行硬件,为大规模神经网络并行处理提供了非常快速的多处理技术。
- 在神经网络的大规模并行处理架构下,网络的某些节点损坏并不影响整个神经网络的整体性能,有效地提高了控制系统的容错性。
针对MIMO模型,常规控制器的设计方法一般要求建立最小相位系统的结构和精确的数学模型,在许多情况下模型参数还要求精确已知。神经网络可以通过前向或反向的动态行为在线学习复杂模型,通过适应环境的变化设计自适应MIMO控制器。从理论上讲,一个基于神经网络的控制系统的设计相对简单,因为它不要求有关该模型的任何先验知识。以上,都需要真实数据进行投喂,数据可靠性越高,量越大,拟合模型越精确,控制器效果越好。
一、RBF神经网络介绍[2]
1. 什么是径向基函数
1985年,Powell提出了多变量插值的径向基函数方法。径向基函数是一个取值仅仅依赖于离原点距离的实值函数,也就是
Φ
(
x
)
=
Φ
(
∣
∣
x
∣
∣
)
Φ(x) = Φ(||x||)
Φ(x)=Φ(∣∣x∣∣),或者还可以是到任意一点c的距离,c点称为中心点,也就是
Φ
(
x
,
c
)
=
Φ
(
∣
∣
x
−
c
∣
∣
)
Φ(x, c) = Φ(||x-c||)
Φ(x,c)=Φ(∣∣x−c∣∣)。任意一个满足
Φ
(
x
)
=
Φ
(
∣
∣
x
∣
∣
)
Φ(x) = Φ(||x||)
Φ(x)=Φ(∣∣x∣∣)特性的函数
Φ
Φ
Φ都叫做径向基函数,标准的一般使用欧氏距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。最常用的径向基函数是高斯核函数 ,形式为
k
(
∣
∣
x
−
x
c
∣
∣
)
=
e
−
∣
∣
x
−
x
c
∣
∣
2
(
2
σ
)
2
k\left(||x-x_c|| \right) = e^{ - \frac{||x-x_c||^2}{(2σ)^2}}
k(∣∣x−xc∣∣)=e−(2σ)2∣∣x−xc∣∣2
其中, x c x_c xc为核函数中心, σ \sigma σ为函数的宽度参数 , 控制了函数的径向作用范围。
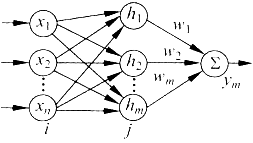
RBF神经网络有3层,输入层、隐含层和输出层。隐含层的神经元激活函数由径向基函数构成。隐含层组成的数组运算单元称为隐含层节点。每个隐含层节点包含一个中心向量
c
\boldsymbol{c}
c,该向量和输入参数向量
x
\boldsymbol{x}
x具有相同的维数,二者之间的欧氏距离定义为
∣
∣
x
(
t
)
−
c
j
(
t
)
∣
∣
||x(t) - c_j(t)||
∣∣x(t)−cj(t)∣∣。隐含层的输出由非线性激活函数
h
j
(
t
)
h_j(t)
hj(t)构成:
h
j
(
t
)
=
exp
(
−
∣
∣
x
−
c
j
(
t
)
∣
∣
2
2
b
j
2
)
,
j
=
1
,
⋯
,
m
h_j(t) = \exp \left( - \frac{||\boldsymbol{x} - \boldsymbol{c}_j(t)||^2}{2 b_j^2} \right) \quad , j = 1, \cdots, m
hj(t)=exp(−2bj2∣∣x−cj(t)∣∣2),j=1,⋯,m
其中,
b
j
b_j
bj是一个正的标量,表示高斯基函数的宽度,
m
m
m是隐含层的节点数量。网络的输出由如下加权函数实现:
y
i
(
t
)
=
∑
j
=
1
m
w
j
i
h
j
(
t
)
,
i
=
1
,
⋯
,
n
y_i(t) = \sum_{j = 1}^m w_{ji} h_j(t) \quad , i = 1, \cdots, n
yi(t)=j=1∑mwjihj(t),i=1,⋯,n
其中, w w w是输出层的权值, n n n是输出节点的个数, y y y是神经网络输出。
2. RBF神经网络
RBF神经网络效果
神经网络最小参数学习法
通过参数的估计代替神经网络权值的调整,自适应算法简单,便于实际工程应用。
二、一种简单的RBF网络自适应滑模控制
1. 控制器设计
考虑一种简单的动力学系统:
θ
¨
=
f
(
θ
,
θ
˙
)
+
u
(1)
\ddot{\theta} = f(\theta, \dot{\theta}) + u \tag{1}
θ¨=f(θ,θ˙)+u(1)
其中, θ \theta θ是转动角度, u u u为控制输入。
写成状态方程的形式:
{
x
˙
1
=
x
2
x
˙
2
=
f
(
x
)
+
u
(2)
\left \{ \begin{aligned} \dot{x}_1 &= x_2 \\ \dot{x}_2 &= f(x) + u \end{aligned} \right. \tag{2}
{x˙1x˙2=x2=f(x)+u(2)
其中, f ( x ) f(x) f(x)为未知项。
位置指令为
x
d
x_d
xd,则误差及其导数为:
e
=
x
1
−
x
d
,
e
˙
=
x
2
−
x
˙
d
(3)
e = x_1 - x_d, \quad \dot{e} = x_2 - \dot{x}_d \tag{3}
e=x1−xd,e˙=x2−x˙d(3)
定义滑模函数:
s
=
c
e
+
e
˙
(4)
s = c e + \dot{e} \tag{4}
s=ce+e˙(4)
则:
s
˙
=
c
e
˙
+
e
¨
=
c
e
˙
+
x
˙
2
−
x
¨
d
=
c
e
˙
+
f
(
x
)
+
u
−
x
¨
d
\dot{s} = c \dot{e} + \ddot{e} = c \dot{e} + \dot{x}_2 - \ddot{x}_d = c \dot{e} + f(x) + u - \ddot{x}_d
s˙=ce˙+e¨=ce˙+x˙2−x¨d=ce˙+f(x)+u−x¨d
由于RBF神经网络具有万能逼近特性,采用RBF神经网络逼近
f
(
x
)
f(x)
f(x),算法为:
h
j
=
exp
(
∣
∣
x
−
c
j
∣
∣
2
2
b
j
2
)
f
=
W
∗
T
h
(
x
)
+
ε
(5)
\begin{aligned} h_j &= \exp \left( \frac{||\boldsymbol{x} - \boldsymbol{c}_j||^2}{2 b_j^2} \right) \\ f &= \boldsymbol{W}^{*T} \boldsymbol{h}(\boldsymbol{x}) + \varepsilon \end{aligned} \tag{5}
hjf=exp(2bj2∣∣x−cj∣∣2)=W∗Th(x)+ε(5)
其中, x \boldsymbol{x} x为网络的输入, j j j为网络隐含层第 j j j个节点, h ( x ) = [ h j ] T \boldsymbol{h}(\boldsymbol{x}) = [h_j]^{\text{T}} h(x)=[hj]T为网络的高斯基函数输出, W ∗ \boldsymbol{W}^* W∗为网络的理想权值 (为常数), ε \varepsilon ε为网络的逼近误差, ∣ ε ∣ ≤ ε N |\varepsilon| \leq \varepsilon_N ∣ε∣≤εN。
由于
f
(
x
)
−
f
^
(
x
)
=
W
∗
T
h
(
x
)
+
ε
−
W
^
T
h
(
x
)
=
W
~
T
h
(
x
)
+
ε
(6)
f(x) - \hat{f}(x) = \boldsymbol{W}^{*\text{T}} \boldsymbol{h}(\boldsymbol{x}) + \varepsilon - \hat \boldsymbol{W}^{\text{T}} \boldsymbol{h}(\boldsymbol{x}) = \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{h}(\boldsymbol{x}) + \varepsilon \tag{6}
f(x)−f^(x)=W∗Th(x)+ε−W^Th(x)=W~Th(x)+ε(6)
定义Lyapunov函数为:
V
=
1
2
s
2
+
1
2
γ
W
~
T
W
~
V = \frac{1}{2} s^2 + \frac{1}{2 \gamma} \tilde \boldsymbol{W}^{\text{T}} \tilde \boldsymbol{W}
V=21s2+2γ1W~TW~
其中, γ > 0 \gamma > 0 γ>0, W ~ = W ^ − W ∗ \tilde{\boldsymbol{W}} = \hat{\boldsymbol{W}} - \boldsymbol{W}^* W~=W^−W∗。
对上式求导,可得:
V
˙
=
s
s
˙
+
1
γ
W
~
T
W
~
˙
=
s
s
˙
+
1
γ
W
~
T
W
^
˙
=
s
(
c
e
˙
+
f
(
x
)
+
u
−
x
¨
d
)
+
1
γ
W
~
T
W
^
˙
(7)
\begin{aligned} \dot{V} &= s \dot{s} + \frac{1}{\gamma} \tilde \boldsymbol{W}^{\text{T}} \dot{\tilde \boldsymbol{W}} = s \dot{s} + \frac{1}{\gamma} \tilde \boldsymbol{W}^{\text{T}} \dot{\hat \boldsymbol{W}} \\ &= s (c \dot{e} + f(x) + u - \ddot{x}_d) + \frac{1}{\gamma} \tilde \boldsymbol{W}^{\text{T}} \dot{\hat \boldsymbol{W}} \end{aligned} \tag{7}
V˙=ss˙+γ1W~TW~˙=ss˙+γ1W~TW^˙=s(ce˙+f(x)+u−x¨d)+γ1W~TW^˙(7)
设计控制律为:
u
=
−
c
e
˙
−
f
^
(
x
)
+
x
¨
d
−
η
sgn
(
s
)
(8)
u = - c \dot{e} - \hat{f}(x) + \ddot{x}_d - \eta \text{sgn}(s) \tag{8}
u=−ce˙−f^(x)+x¨d−ηsgn(s)(8)
将式
(
8
)
(8)
(8)代入式
(
7
)
(7)
(7),可得:
V
˙
=
s
(
f
(
x
)
−
f
^
(
x
)
−
η
sgn
(
s
)
)
+
1
γ
W
~
T
W
^
˙
=
s
(
−
W
~
T
h
(
x
)
+
ε
−
η
sgn
(
s
)
)
+
1
γ
W
~
T
W
^
˙
=
ε
s
−
η
∣
s
∣
+
W
~
T
(
1
γ
W
^
˙
−
s
h
(
x
)
)
(9)
\begin{aligned} \dot{V} &= s (f(x) - \hat{f}(x) - \eta \text{sgn}(s)) + \frac{1}{\gamma} \tilde \boldsymbol{W}^{\text{T}} \dot{\hat \boldsymbol{W}} \\ &= s (- \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{h}(\boldsymbol{x}) + \varepsilon - \eta \text{sgn}(s)) + \frac{1}{\gamma} \tilde \boldsymbol{W}^{\text{T}} \dot{\hat \boldsymbol{W}} \\ &= \varepsilon s - \eta |s| + \tilde \boldsymbol{W}^{\text{T}} \left( \frac{1}{\gamma} \dot{\hat{\boldsymbol{W}}} - s \boldsymbol{h}(\boldsymbol{x}) \right) \end{aligned} \tag{9}
V˙=s(f(x)−f^(x)−ηsgn(s))+γ1W~TW^˙=s(−W~Th(x)+ε−ηsgn(s))+γ1W~TW^˙=εs−η∣s∣+W~T(γ1W^˙−sh(x))(9)
取
η
>
ε
N
\eta > \varepsilon_N
η>εN,自适应律为:
W
^
˙
=
γ
s
h
(
x
)
(10)
\dot{\hat{\boldsymbol{W}}} = \gamma s \boldsymbol{h}(\boldsymbol{x}) \tag{10}
W^˙=γsh(x)(10)
令
η
=
η
0
+
ε
N
,
η
0
>
0
\eta = \eta_0 + \varepsilon_N, \eta_0 > 0
η=η0+εN,η0>0,则式
(
9
)
(9)
(9)可化为:
V
˙
=
ε
s
−
η
∣
s
∣
≤
−
η
0
∣
s
∣
≤
0
\dot{V} = \varepsilon s - \eta |s| \leq - \eta_0 |s| \leq 0
V˙=εs−η∣s∣≤−η0∣s∣≤0
当 V ˙ ≡ 0 \dot{V} \equiv 0 V˙≡0时, s ≡ 0 s \equiv 0 s≡0,根据LaSalle不变集原理,闭环系统渐近稳定,即 t → ∞ t \rightarrow \infin t→∞时, s → 0 s \rightarrow 0 s→0。由于 V ≥ 0 V \geq 0 V≥0且 V ˙ ≤ 0 \dot{V} \leq 0 V˙≤0,则当 t → ∞ t \rightarrow \infin t→∞时, V V V有界,则 W ^ \hat{\boldsymbol{W}} W^有界,但无法保证收敛于 W \boldsymbol{W} W。控制律 ( 8 ) (8) (8)中的鲁棒项 η sgn ( s ) \eta \text{sgn}(s) ηsgn(s)的作用是克服神经网络的逼近误差,以保证系统稳定性。
问题:
- 高斯基函数中的参数 c i \boldsymbol{c}_i ci和 b i b_i bi如何取值?
- RBF神经网络的权值如何取?按自适应律 ( 10 ) (10) (10)来取值。
- 逼近误差 ε \varepsilon ε的上界 ε N \varepsilon_N εN是多少?
- 控制律中的参数 γ \gamma γ和 η \eta η如何取值?对系统的控制效果会产生什么影响?
2. 仿真分析
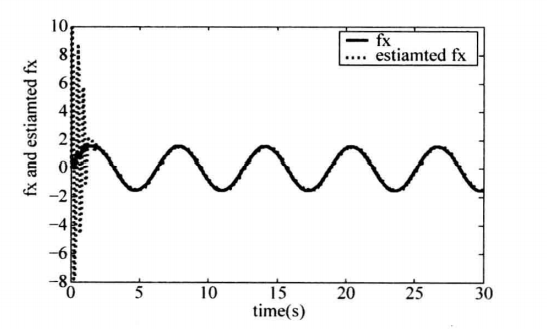
详细过程见参考文献[1]第九章。其他方法与之类似,都是用神经网络逼近模型未知部分,下面一种方法是用神经网络直接拟合控制律,因为控制律也是一个未知函数。
三、基于神经网络的直接自适应滑模控制
1. 控制律设计
考虑如下非线性二阶系统:
{
x
˙
1
=
x
2
x
˙
2
=
α
(
x
)
+
β
(
x
)
u
y
=
x
1
(11)
\left \{ \begin{aligned} \dot{x}_1 &= x_2 \\ \dot{x}_2 &= \alpha(\boldsymbol{x}) + \beta(\boldsymbol{x}) u \\ y &= x_1 \end{aligned} \right. \tag{11}
⎩⎪⎨⎪⎧x˙1x˙2y=x2=α(x)+β(x)u=x1(11)
其中,。。。。。 α ( x ) \alpha(\boldsymbol{x}) α(x)和 β ( x ) \beta(\boldsymbol{x}) β(x)未知光滑函数, β ( x ) > 0 \beta(\boldsymbol{x}) > 0 β(x)>0, ∣ β ( x ) ∣ ≤ β ˉ |\beta(\boldsymbol{x})| \leq \bar{\beta} ∣β(x)∣≤βˉ。定义 x = [ x 1 , x 2 ] T ∈ R \boldsymbol{x} = [x_1, x_2]^{\text{T}} \in \mathbb{R} x=[x1,x2]T∈R。
定义向量
x
d
\boldsymbol{x}_d
xd、
e
\boldsymbol{e}
e和滑模函数
s
s
s:
x
d
=
[
y
d
,
y
˙
d
]
T
e
=
x
−
x
d
=
[
e
,
e
˙
]
T
s
=
[
λ
,
1
]
e
=
λ
e
+
e
˙
\begin{aligned} \boldsymbol{x}_d &= [y_d, \dot{y}_d]^{\text{T}} \\ \boldsymbol{e} &= \boldsymbol{x} - \boldsymbol{x}_d = [e, \dot{e}]^{\text{T}} \\ s &= [\lambda, 1] \boldsymbol{e} = \lambda e + \dot{e} \end{aligned}
xdes=[yd,y˙d]T=x−xd=[e,e˙]T=[λ,1]e=λe+e˙
其中,
λ
>
0
\lambda > 0
λ>0。对滑模函数
s
s
s求导,可得:
s
˙
=
λ
e
˙
+
e
¨
=
⋯
=
α
(
x
)
+
v
+
β
(
x
)
u
(12)
\dot{s} = \lambda \dot{e} + \ddot{e} = \cdots = \alpha(\boldsymbol{x}) + v + \beta(\boldsymbol{x}) u \tag{12}
s˙=λe˙+e¨=⋯=α(x)+v+β(x)u(12)
其中, v = − y ¨ d + λ e ˙ v = -\ddot{y}_d + \lambda \dot{e} v=−y¨d+λe˙。
那么,针对被控对象
(
11
)
(11)
(11),理想滑模控制器为 (这里不应该采用这种比较复杂的滑模控制器,or应该说明为什么采用这种控制器):
u
∗
=
−
1
β
(
x
)
(
α
(
x
)
+
v
)
−
(
1
ε
β
(
x
)
+
1
ε
β
2
(
x
)
−
β
˙
(
x
)
2
β
2
(
x
)
)
s
(13)
u^* = - \frac{1}{\beta(\boldsymbol{x})} (\alpha(\boldsymbol{x}) + v) - \left( \frac{1}{\varepsilon \beta(\boldsymbol{x})} + \frac{1}{\varepsilon \beta^2(\boldsymbol{x})} - \frac{\dot{\beta}(\boldsymbol{x})}{2 \beta^2(\boldsymbol{x})} \right)s \tag{13}
u∗=−β(x)1(α(x)+v)−(εβ(x)1+εβ2(x)1−2β2(x)β˙(x))s(13)
其中, ε > 0 \varepsilon > 0 ε>0。
由
u
∗
u^*
u∗的表达式可知,
u
∗
u^*
u∗为关于
x
\boldsymbol{x}
x、
s
s
s、
ε
\varepsilon
ε、
v
v
v的连续函数,所以可以采用RBF神经网络来逼近
u
∗
u^*
u∗,则该函数的神经网络输入可表示为 (为什么这么选呢?为了提高网络逼近的精度):
z
=
[
x
,
s
,
s
ε
,
v
]
T
∈
Ω
z
⊂
R
5
(14)
\boldsymbol{z} = \left[ \boldsymbol{x}, s, \frac{s}{\varepsilon}, v \right]^{\text{T}} \in \Omega_z \sub \mathbb{R}^5 \tag{14}
z=[x,s,εs,v]T∈Ωz⊂R5(14)
存在理想的网络权值
W
∗
\boldsymbol{W}^*
W∗,使得:
u
∗
(
z
)
=
W
∗
T
h
(
z
)
+
μ
l
(15)
u^* (\boldsymbol{z}) = \boldsymbol{W}^{* \text{T}} \boldsymbol{h} (\boldsymbol{z}) + \mu_l \tag{15}
u∗(z)=W∗Th(z)+μl(15)
其中,
h
(
z
)
\boldsymbol{h} (\boldsymbol{z})
h(z)为高斯基函数,
μ
l
\mu_l
μl为网络的逼近误差,且满足
∣
μ
l
∣
≤
μ
0
|\mu_l| \leq \mu_0
∣μl∣≤μ0。因此可得:
W
∗
=
arg
min
W
∈
R
l
{
sup
z
∈
Ω
z
∣
W
T
h
(
z
)
−
u
∗
(
z
)
}
(16)
\boldsymbol{W}^* = \arg \min_{\boldsymbol{W} \in \mathbb{R}^l} \left \{ \sup_{\boldsymbol{z} \in \Omega_z} | \boldsymbol{W}^{\text T} \boldsymbol{h} (\boldsymbol{z}) - u^*(\boldsymbol{z}) \right \} \tag{16}
W∗=argW∈Rlmin{z∈Ωzsup∣WTh(z)−u∗(z)}(16)
控制律设计为RBF神经网络的输出,即:
u
=
W
^
T
h
(
z
)
(17)
u = \hat \boldsymbol{W}^{\text{T}} \boldsymbol{h} (\boldsymbol{z}) \tag{17}
u=W^Th(z)(17)
其中, W ^ \hat \boldsymbol{W} W^是 W ∗ \boldsymbol{W}^* W∗的估计值。
自适应律设计为 (why):
W
^
˙
=
−
Γ
(
h
(
z
)
s
+
σ
W
^
)
(18)
\dot{\hat \boldsymbol{W}} = - \boldsymbol{\Gamma} (\boldsymbol{h}(\boldsymbol{z}) s + \sigma \hat \boldsymbol{W}) \tag{18}
W^˙=−Γ(h(z)s+σW^)(18)
其中, Γ = Γ T > 0 \boldsymbol{\Gamma} = \boldsymbol{\Gamma}^{\text{T}} > 0 Γ=ΓT>0, σ > 0 \sigma > 0 σ>0。
将控制器
(
17
)
(17)
(17)代入式
(
12
)
(12)
(12),得:
s
˙
=
α
(
x
)
+
v
+
β
(
x
)
W
^
T
h
(
z
)
(19)
\dot{s} = \alpha(\boldsymbol{x}) + v + \beta(\boldsymbol{x}) \hat \boldsymbol{W}^{\text{T}} \boldsymbol{h} (\boldsymbol{z}) \tag{19}
s˙=α(x)+v+β(x)W^Th(z)(19)
将式
(
15
)
(15)
(15)代入式
(
19
)
(19)
(19),可得 (这里相对于把约束条件“0=0”代入):
s
˙
=
α
(
x
)
+
v
+
β
(
x
)
(
W
^
T
h
(
z
)
−
W
∗
T
h
(
z
)
−
μ
l
)
+
β
(
x
)
u
∗
(
z
)
(20)
\dot{s} = \alpha(\boldsymbol{x}) + v + \beta(\boldsymbol{x}) \left( \hat \boldsymbol{W}^{\text{T}} \boldsymbol{h} (\boldsymbol{z}) - \boldsymbol{W}^{* \text{T}} \boldsymbol{h} (\boldsymbol{z}) - \mu_l \right) + \beta(\boldsymbol{x}) u^* (\boldsymbol{z}) \tag{20}
s˙=α(x)+v+β(x)(W^Th(z)−W∗Th(z)−μl)+β(x)u∗(z)(20)
进一步将理想滑模控制器
(
13
)
(13)
(13)代入上式,经化简后可得:
s
˙
=
β
(
x
)
(
W
~
T
h
(
z
)
−
μ
l
)
−
(
1
ε
+
1
ε
β
(
x
)
−
β
˙
(
x
)
2
β
(
x
)
)
s
(21)
\dot{s} = \beta(\boldsymbol{x}) \left( \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{h} (\boldsymbol{z}) - \mu_l \right) - \left( \frac{1}{\varepsilon} + \frac{1}{\varepsilon \beta(\boldsymbol{x})} - \frac{\dot{\beta}(\boldsymbol{x})}{2 \beta(\boldsymbol{x})} \right) s \tag{21}
s˙=β(x)(W~Th(z)−μl)−(ε1+εβ(x)1−2β(x)β˙(x))s(21)
其中, W ~ = W ^ − W ∗ \tilde \boldsymbol{W} = \hat \boldsymbol{W} - \boldsymbol{W}^* W~=W^−W∗。
为了防止
β
(
x
)
\beta (\boldsymbol{x})
β(x)项包含在自适应律
W
^
˙
\dot{\hat \boldsymbol{W}}
W^˙中,在Lyapunov函数中取
1
2
s
2
β
(
x
)
\frac{1}{2} \frac{s^2}{\beta (\boldsymbol{x})}
21β(x)s2替代
1
2
s
2
\frac{1}{2} s^2
21s2 (这里用到了
β
(
x
)
>
0
\beta (\boldsymbol{x}) >0
β(x)>0)的条件,则Lyapunov函数设计为:
V
=
1
2
(
s
2
β
(
x
)
+
W
~
T
Γ
−
1
W
~
)
(22)
V = \frac{1}{2} \left(\frac{s^2}{\beta (\boldsymbol{x})} + \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \tilde \boldsymbol{W} \right) \tag{22}
V=21(β(x)s2+W~TΓ−1W~)(22)
对上式求导 (这里也用了控制律是个慢变量的条件,是不是理解错了??是的!!) 并将式
(
18
)
(18)
(18)和
(
21
)
(21)
(21)代入,可得,可得:
V
˙
=
s
s
˙
β
(
x
)
−
β
˙
(
x
)
s
2
β
2
(
x
)
+
W
~
T
Γ
−
1
W
^
˙
=
s
β
(
x
)
(
β
(
x
)
(
W
~
T
h
(
z
)
−
μ
l
)
−
(
1
ε
+
1
ε
β
(
x
)
−
β
˙
(
x
)
2
β
(
x
)
)
s
)
−
β
˙
(
x
)
s
2
β
2
(
x
)
+
W
~
T
Γ
−
1
(
−
Γ
(
h
(
z
)
s
+
σ
W
^
)
)
=
−
(
1
ε
β
(
x
)
+
1
ε
β
2
(
x
)
)
s
2
−
μ
l
s
−
σ
W
~
T
W
^
(23)
\begin{aligned} \dot{V} &= \frac{s \dot{s}}{\beta (\boldsymbol{x})} - \frac{\dot{\beta}(\boldsymbol{x}) s^2}{\beta^2 (\boldsymbol{x})} + \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \dot{\hat \boldsymbol{W}} \\ &= \frac{s}{\beta (\boldsymbol{x})} \left( \beta(\boldsymbol{x}) \left( \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{h} (\boldsymbol{z}) - \mu_l \right) - \left( \frac{1}{\varepsilon} + \frac{1}{\varepsilon \beta(\boldsymbol{x})} - \frac{\dot{\beta}(\boldsymbol{x})}{2 \beta(\boldsymbol{x})} \right) s \right) \\ & \quad - \frac{\dot{\beta}(\boldsymbol{x}) s^2}{\beta^2 (\boldsymbol{x})} + \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \left( - \boldsymbol{\Gamma} (\boldsymbol{h}(\boldsymbol{z}) s + \sigma \hat \boldsymbol{W}) \right) \\ &= - \left( \frac{1}{\varepsilon \beta (\boldsymbol{x})} + \frac{1}{\varepsilon \beta^2 (\boldsymbol{x})} \right) s^2 - \mu_l s - \sigma \tilde \boldsymbol{W}^{\text{T}} \hat \boldsymbol{W} \end{aligned} \tag{23}
V˙=β(x)ss˙−β2(x)β˙(x)s2+W~TΓ−1W^˙=β(x)s(β(x)(W~Th(z)−μl)−(ε1+εβ(x)1−2β(x)β˙(x))s)−β2(x)β˙(x)s2+W~TΓ−1(−Γ(h(z)s+σW^))=−(εβ(x)1+εβ2(x)1)s2−μls−σW~TW^(23)
由于:
2
W
~
T
W
^
=
W
~
T
(
W
~
+
W
∗
)
+
(
W
^
−
W
∗
)
T
W
^
=
W
~
T
W
~
+
(
W
^
−
W
∗
)
T
W
^
∗
+
W
^
T
W
^
−
W
∗
T
W
^
=
∣
∣
W
~
∣
∣
2
+
∣
∣
W
^
∣
∣
2
−
∣
∣
W
∗
∣
∣
2
≥
∣
∣
W
~
∣
∣
2
−
∣
∣
W
∗
∣
∣
2
(24)
\begin{aligned} 2 \tilde \boldsymbol{W}^{\text{T}} \hat \boldsymbol{W} &= \tilde \boldsymbol{W}^{\text{T}} \left( \tilde \boldsymbol{W} + \boldsymbol{W}^* \right) + \left( \hat \boldsymbol{W} - \boldsymbol{W}^* \right)^{\text{T}} \hat \boldsymbol{W} \\ &= \tilde \boldsymbol{W}^{\text{T}} \tilde \boldsymbol{W} + \left( \hat \boldsymbol{W} - \boldsymbol{W}^* \right)^{\text{T}} \hat \boldsymbol{W}^* + \hat \boldsymbol{W}^{\text{T}} \hat \boldsymbol{W} - \boldsymbol{W}^{* \text{T}} \hat \boldsymbol{W} \\ &= ||\tilde \boldsymbol{W}||^2 + ||\hat \boldsymbol{W}||^2 - ||\boldsymbol{W}^*||^2 \\ & \geq ||\tilde \boldsymbol{W}||^2 - ||\boldsymbol{W}^*||^2 \end{aligned} \tag{24}
2W~TW^=W~T(W~+W∗)+(W^−W∗)TW^=W~TW~+(W^−W∗)TW^∗+W^TW^−W∗TW^=∣∣W~∣∣2+∣∣W^∣∣2−∣∣W∗∣∣2≥∣∣W~∣∣2−∣∣W∗∣∣2(24)
和 (
2
a
b
≤
a
2
+
b
2
2ab \leq a^2 + b^2
2ab≤a2+b2)
∣
μ
l
s
∣
≤
s
2
2
ε
β
(
x
)
+
ε
2
μ
l
2
β
(
x
)
≤
s
2
2
ε
β
(
x
)
+
ε
2
μ
l
2
β
ˉ
(25)
|\mu_l s| \leq \frac{s^2}{2 \varepsilon \beta (\boldsymbol{x})} + \frac{\varepsilon}{2} \mu_l^2 \beta (\boldsymbol{x}) \leq \frac{s^2}{2 \varepsilon \beta (\boldsymbol{x})} + \frac{\varepsilon}{2} \mu_l^2 \bar \beta \tag{25}
∣μls∣≤2εβ(x)s2+2εμl2β(x)≤2εβ(x)s2+2εμl2βˉ(25)
又由于
∣
μ
l
∣
≤
μ
0
|\mu_l| \leq \mu_0
∣μl∣≤μ0,将式
(
24
)
(24)
(24)和
(
25
)
(25)
(25)代入式
(
23
)
(23)
(23),式
(
23
)
(23)
(23)可以进一步化为:
V
˙
≤
−
s
2
2
ε
β
(
x
)
−
σ
2
∣
∣
W
~
∣
∣
2
+
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
(26)
\dot{V} \leq - \frac{s^2}{2 \varepsilon \beta (\boldsymbol{x})} - \frac{\sigma}{2} ||\tilde \boldsymbol{W}||^2 + \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \tag{26}
V˙≤−2εβ(x)s2−2σ∣∣W~∣∣2+2εμ02βˉ+2σ∣∣W∗∣∣2(26)
又由于
W
~
T
Γ
−
1
W
~
≤
γ
ˉ
∣
∣
W
~
∣
∣
2
\tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \tilde \boldsymbol{W} \leq \bar{\gamma} ||\tilde \boldsymbol{W}||^2
W~TΓ−1W~≤γˉ∣∣W~∣∣2,(
γ
ˉ
\bar \gamma
γˉ为
Γ
−
1
\boldsymbol{\Gamma}^{-1}
Γ−1的最大特征值),故上式可以进一步化为:
V
˙
≤
−
1
2
(
s
2
ε
β
(
x
)
+
σ
γ
ˉ
W
~
T
Γ
−
1
W
~
)
+
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
≤
−
1
α
0
1
2
(
s
2
β
(
x
)
+
W
~
T
Γ
−
1
W
~
)
+
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
=
−
1
α
0
V
+
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
(27)
\begin{aligned} \dot{V} &\leq - \frac{1}{2} \left( \frac{s^2}{\varepsilon \beta (\boldsymbol{x})} + \frac{\sigma}{\bar \gamma} \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \tilde \boldsymbol{W} \right) + \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \\ &\leq - \frac{1}{\alpha_0} \frac{1}{2} \left( \frac{s^2}{\beta (\boldsymbol{x})} + \tilde \boldsymbol{W}^{\text{T}} \boldsymbol{\Gamma}^{-1} \tilde \boldsymbol{W} \right)+ \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \\ &= - \frac{1}{\alpha_0} V+ \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \end{aligned} \tag{27}
V˙≤−21(εβ(x)s2+γˉσW~TΓ−1W~)+2εμ02βˉ+2σ∣∣W∗∣∣2≤−α0121(β(x)s2+W~TΓ−1W~)+2εμ02βˉ+2σ∣∣W∗∣∣2=−α01V+2εμ02βˉ+2σ∣∣W∗∣∣2(27)
其中, α 0 = max { ε , γ ˉ / σ } \alpha_0 = \max\{ \varepsilon, \bar \gamma /\sigma \} α0=max{ε,γˉ/σ}。
这里,需要通过选择适当的参数 α 0 \alpha_0 α0、 β ˉ \bar \beta βˉ、 σ \sigma σ和 μ 0 \mu_0 μ0,来确保 1 α 0 V > ε 2 μ l 2 β ˉ + σ 2 ∣ ∣ W ∗ ∣ ∣ 2 \frac{1}{\alpha_0} V > \frac{\varepsilon}{2} \mu_l^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 α01V>2εμl2βˉ+2σ∣∣W∗∣∣2, W ∗ \boldsymbol{W}^* W∗未知,也无法保证哇!!
根据引理1,求解不等式
(
27
)
(27)
(27),取
t
(
0
)
=
0
t(0) = 0
t(0)=0,可得:
V
(
t
)
≤
e
−
t
α
0
V
(
0
)
+
(
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
)
∫
0
t
e
−
t
−
τ
α
0
d
τ
≤
e
−
t
α
0
V
(
0
)
+
α
0
(
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
)
,
∀
t
≥
0
(28)
\begin{aligned} V(t) &\leq e^{- \frac{t}{\alpha_0}} V(0) + \left( \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \right) \int_0^t e^{- \frac{t - \tau}{\alpha_0}} \text{d} \tau \\ & \leq e^{- \frac{t}{\alpha_0}} V(0) + \alpha_0 \left( \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \right) , \forall t \geq 0 \end{aligned} \tag{28}
V(t)≤e−α0tV(0)+(2εμ02βˉ+2σ∣∣W∗∣∣2)∫0te−α0t−τdτ≤e−α0tV(0)+α0(2εμ02βˉ+2σ∣∣W∗∣∣2),∀t≥0(28)
由于
V
(
0
)
V(0)
V(0)有界,则式
(
28
)
(28)
(28)表明,
V
(
t
)
V(t)
V(t)是有界的,因此
s
s
s和
W
^
(
t
)
\hat \boldsymbol{W}(t)
W^(t)有界。也就只能证明到这一步了。
lim
t
→
∞
V
(
t
)
≤
α
0
(
ε
2
μ
0
2
β
ˉ
+
σ
2
∣
∣
W
∗
∣
∣
2
)
能说明什么问题呢?
\lim_{t \rightarrow \infin} V(t) \leq \alpha_0 \left( \frac{\varepsilon}{2} \mu_0^2 \bar \beta + \frac{\sigma}{2} ||\boldsymbol{W}^*||^2 \right) \quad \color{red} \text{能说明什么问题呢?}
t→∞limV(t)≤α0(2εμ02βˉ+2σ∣∣W∗∣∣2)能说明什么问题呢?
问题:
- 由于 W ∗ \boldsymbol{W}^* W∗未知,无法由式 ( 27 ) (27) (27)来证明控制器 ( 17 ) (17) (17)的收敛性哇!!收敛速度也无法保证!
- 在式 ( 28 ) (28) (28)中,如何证明 ∫ 0 t e − t − τ α 0 d τ ≤ α 0 \int_0^t e^{- \frac{t - \tau}{\alpha_0}} \text{d} \tau \leq \alpha_0 ∫0te−α0t−τdτ≤α0? (简单,已解决)
- 参数太多,如何选择参数?
- 这么复杂,可能还不如简单的PID效果好,路跑偏了吧!
引理1: 针对
V
:
[
0
,
∞
)
∈
R
V: [0, \infin) \in \mathbb{R}
V:[0,∞)∈R,不等式方程
V
˙
≤
−
α
V
+
f
,
∀
t
≥
t
0
≥
0
\dot{V} \leq - \alpha V + f, \forall t \geq t_0 \geq 0
V˙≤−αV+f,∀t≥t0≥0的解为:
V
(
t
)
≤
e
−
α
(
t
−
t
0
)
V
(
t
0
)
+
∫
t
0
t
e
−
α
(
t
−
τ
)
f
(
τ
)
d
τ
V(t) \leq e^{- \alpha (t - t_0)} V(t_0) + \int_{t_0}^t e^{- \alpha (t - \tau)} f(\tau) \text{d} \tau
V(t)≤e−α(t−t0)V(t0)+∫t0te−α(t−τ)f(τ)dτ
其中, α \alpha α为任意常数。
当
f
=
0
f = 0
f=0,则
V
˙
≤
−
α
V
\dot{V} \leq - \alpha V
V˙≤−αV的解为:
V
(
t
)
≤
e
−
α
(
t
−
t
0
)
V
(
t
0
)
V(t) \leq e^{- \alpha (t - t_0)} V(t_0)
V(t)≤e−α(t−t0)V(t0)
如果 α \alpha α为正实数,则 V ( t ) V(t) V(t)以指数形式收敛于0。
2. 仿真分析
详细过程见参考文献[1]第九章9.4节。
参考文献
- 刘金琨. 滑模变结构控制MATLAB仿真:基本理论与设计方法[M]. 清华大学出版社, 2015.
- RBF(径向基函数)神经网络
- 刘金琨. RBF神经网络自适应控制matlab仿真[M]. 清华大学出版社, 2014.


















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











