








点击关注,桓峰基因
桓峰基因的教程不但教您怎么使用,还会定期分析一些相关的文章,学会教程只是基础,但是如果把分析结果整合到文章里面才是目的,觉得我们这些教程还不错,并且您按照我们的教程分析出来不错的结果发了文章记得告知我们,并在文章中感谢一下我们哦!
公司英文名称:Kyoho Gene Technology (Beijing) Co.,Ltd.
如果您觉得这些确实没基础,需要专业的生信人员帮助分析,直接加微信nihaoooo123,我们24小时在线!!
这期介绍一下GEO数据库中的甲基化芯片,方便大家进行数据集的选择和下载,进一步增加使用效率!
GEO甲基化数据下载
关于GEO数据介绍我们在RNA系列教程有介绍过,有需求的老师可以在看一次,这里就介绍甲基化数据,官网下载方式是相同的,通过GEOquery下载也可以,但是由于网络的问题总是下载失败,接下来就说说数据下载的不同方式,包括网页下载和GEOquery下载。
1. 网页下载方式
GEO主页链接如下:
https://www.ncbi.nlm.nih.gov/geo/
GEO主页进入之后页面右上方输入需要的数据集 “Keyword or GEO Accession” ,这里我们选择 数据集 GSE68379, 如下:
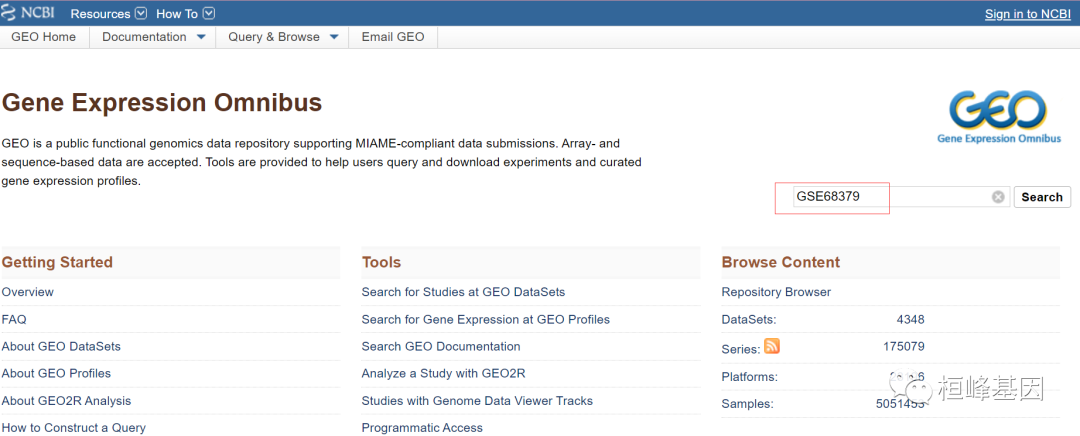
进入到对应数据集 GSE68379 网页中,可以看到数据集的相关信息,有Status,Title, Organism, Experiment type, Summary, Overall design等相关信息,在Summary我们可以清晰的看到样本信息,这里11215 tumors ,29个组织,1001癌症的细胞系,数据量还是很大的这篇文章发表在Cell上,无论是数据量还是工作量都非常大。
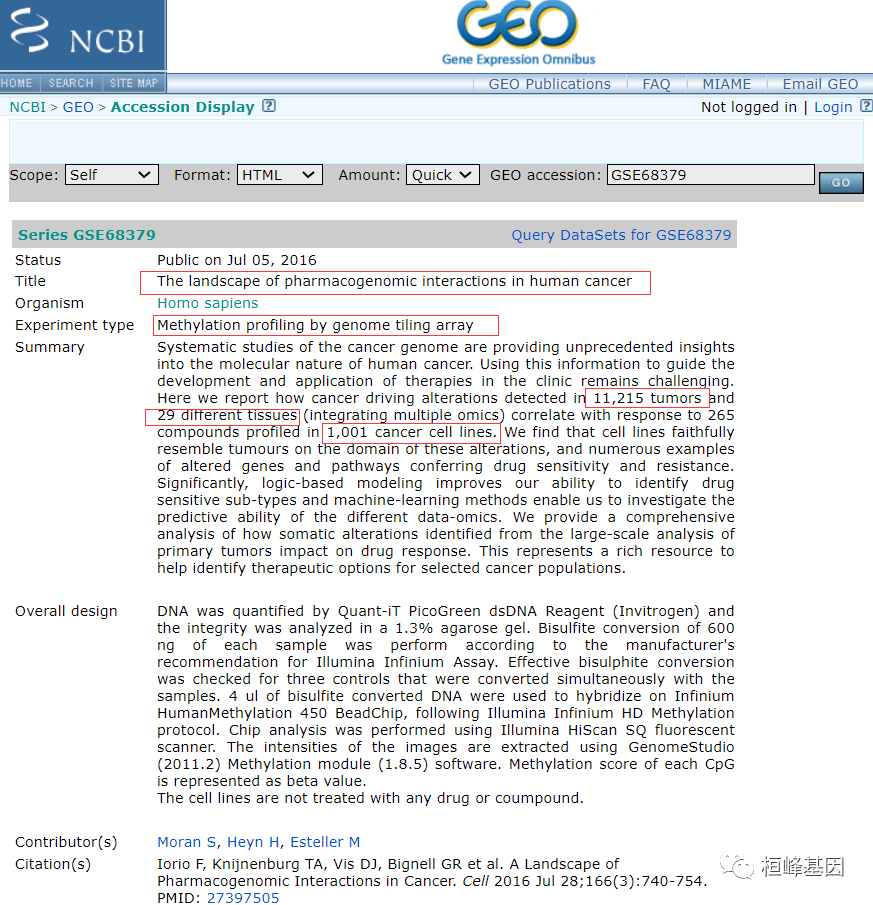
在看数据集的甲基化检测平台(Platforms)为甲基化芯片的450K,样本(Samples)为1028个,我们下载时需要根据自己的需求下载数据,由于芯片的原始数据一般都是非常大的,大概都是几个G以上的数据量,在我们自己下载的时候往往经常出现中断的情况,这样我们需要更好的办法来处理这个问题,比如翻个墙啥的,或者借助国内的一些公司都有整理这些数据,在他们的网页上下载也是可以的。
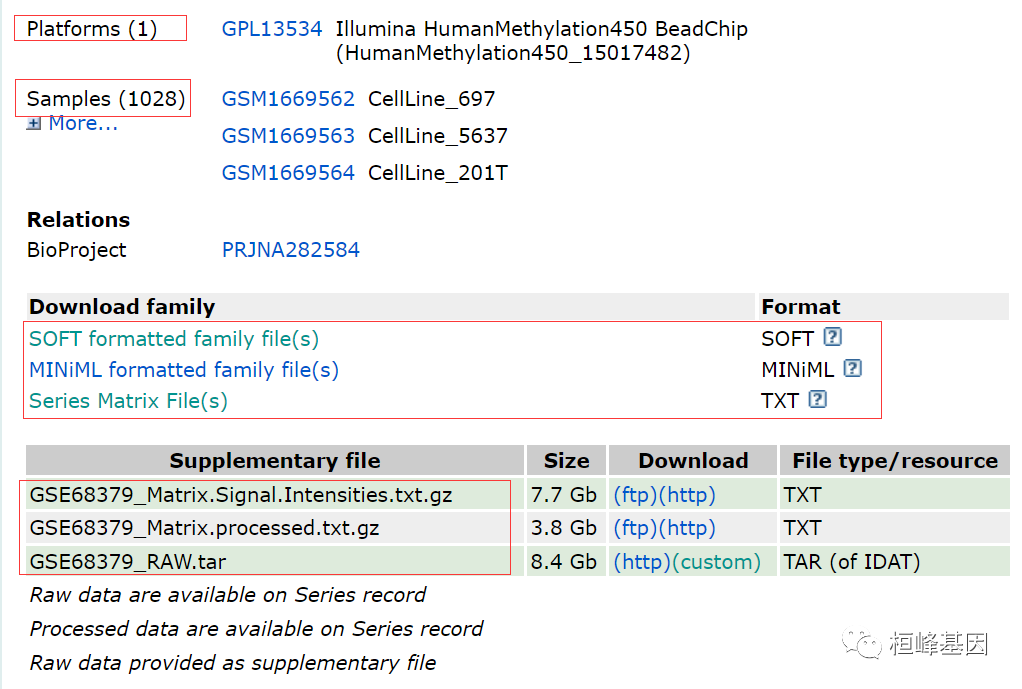
若我们并不需要全部的样本,可以考虑单个样本下载,在Samples里面找到自己想要研究的样本名比如 GSM1669567,点击该样本GSM1669567。
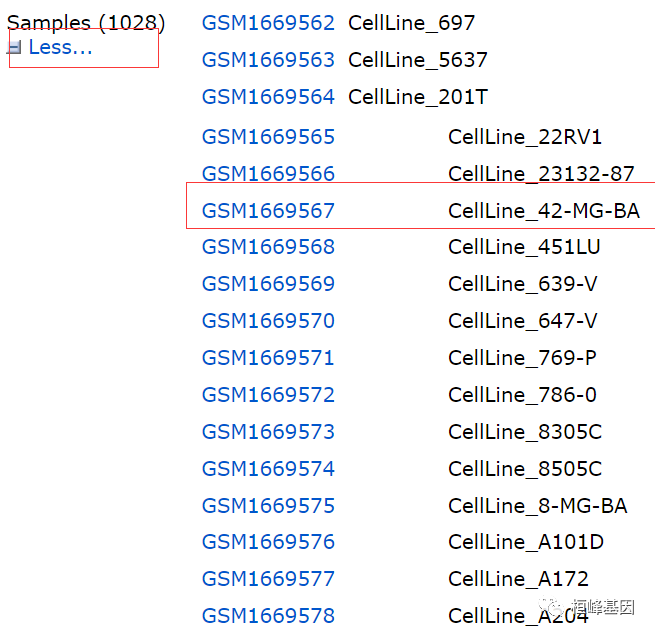
进入这个样本GSM1669567的页面,该页面有详细的样本信息介绍,比如我们选择的是细胞系 42-MG-BA,原发胃癌甲基化检测450K,如下:
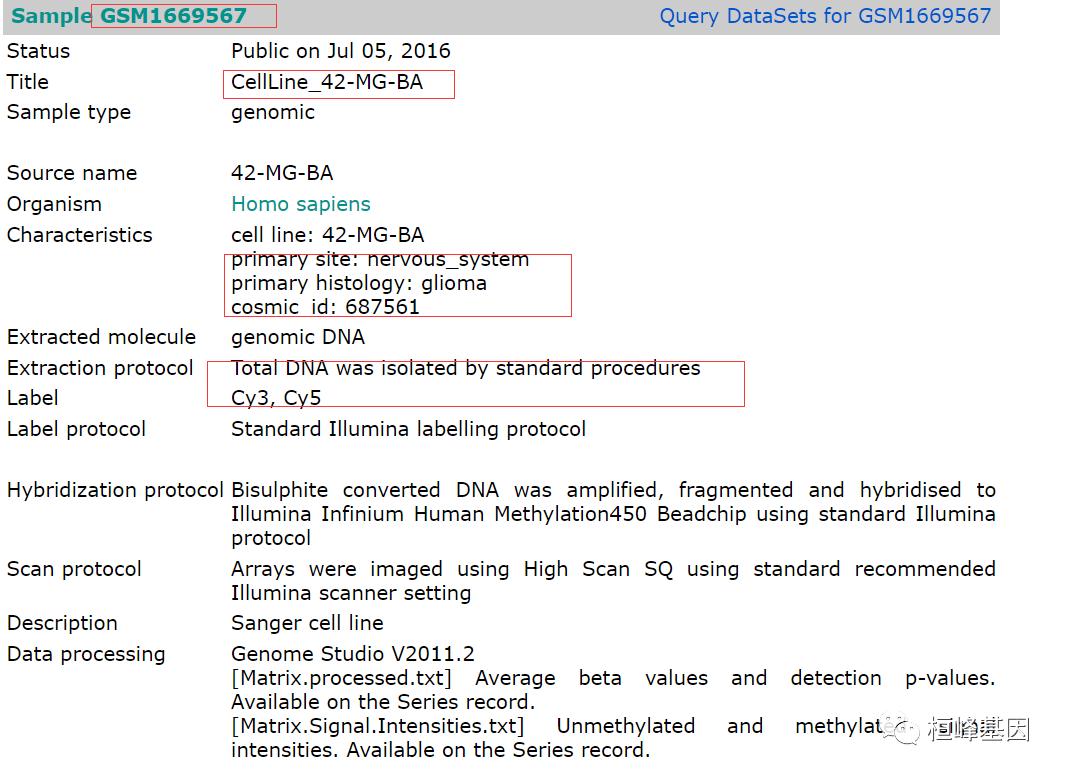
单个样本的下载数据量还算小些,这样直接下载就可以了,这里需要说一下IDAT这种文件类型。
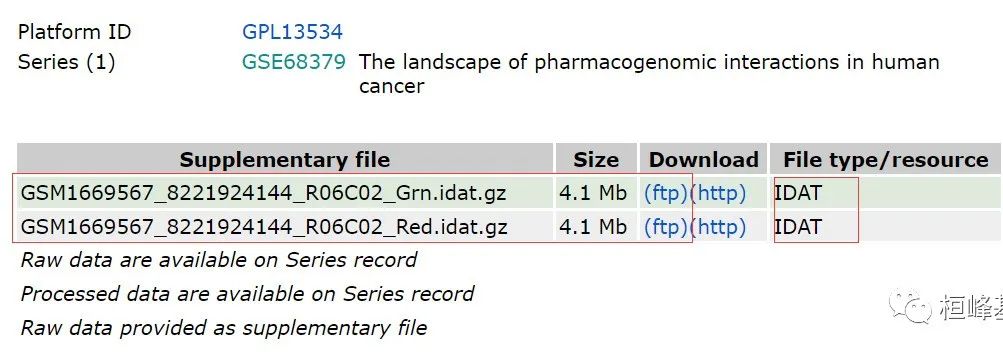
点击ftp下载即可,如下:
上期我们有简单介绍过甲基化芯片检测的原理,这期我们在详细介绍其甲基化水平定量的方法。

1、芯片:一张芯片包括12个array(如图显示),也就是一张芯片可以做12个sample,一台机子一次可以跑8张芯片,也就是一共96个sample,每个样本可以测到超过450,000个CpG位点的甲基化信息(大概人所有的1%,但是覆盖了多数CpG岛和启动子区),芯片本身包含一些控制探针可以做质控。
2、原理:简而言之,基于亚硫酸盐处理后的DNA序列杂交的信号探测。亚硫酸盐是甲基化探测的“金标准”,不管是芯片或者甲基化测序,都要先对DNA样品进行亚硫酸盐处理,使非甲基化的C变成U,而甲基化的C保持不变,从而在后续的测序或者杂交后区分出来。450K采用了两种探针对甲基化进行测定,Infinium I采用了两种bead(甲基化M和非甲基化U,如图显示),而II只有一种bead(即甲基化和非甲基化在一起),这也导致了它们在后续荧光探测的不同,450K采用了两种荧光探测信号(红光和绿光)。
二、分析需要考虑的问题
1、背景校正
2、红光和绿光的校正
3、控制芯片的使用(illumina450K本身有一些控制芯片,可以用来做质控,如亚硫酸盐处理效率)
4、探针类型(I型和II型)的校正(不同探针类型产生的数据不同)
最终我们选择BMIQ的方法(基于ebayes的原理将II型探针的甲基化水平拉伸到I型水平)来做矫正。
5、位置的校正(芯片上的不同位置产生的数据可能会有偏差)
6、批次的校正(不同的批次做的数据会有偏差)
7、探针序列本身是否可靠(有些探针本身位于repeat区或者包含snp等就会影响杂交及最后的结果,应该去除,附上一篇参考文献,里边有list可以用来去除不好的探针)
http://www.biotrainee.com/thread-237-1-1.html
http://www.bioinfo-scrounger.com/archives/430
平均β=信号B /(信号A +信号B + 100)
通过计算甲基化(信号A)和未甲基化(信号B)等位基因之间的强度比来确定DNA甲基化水平(β值)。
具体地,β值是由甲基化(M对应于信号A)和未甲基化(U对应于信号B)等位基因的强度计算的,荧光信号的比率β= Max(M,0)/ [Max( M,0)+ Max(U,0)+ 100]。
因此,β值的范围从0(完全未甲基化)到1(完全甲基化)
具体的β值的意义是:
- 任何等于或大于0.6的β值都被认为是完全甲基化的;
任何等于或小于0.2的β值被认为是完全未甲基化的;
β值在0.2和0.6之间被认为是部分甲基化的。
References:
- Iorio F, Knijnenburg TA, Vis DJ, Bignell GR et al. A Landscape of Pharmacogenomic Interactions in Cancer. Cell 2016 Jul 28;166(3):740-754. PMID: 27397505















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









