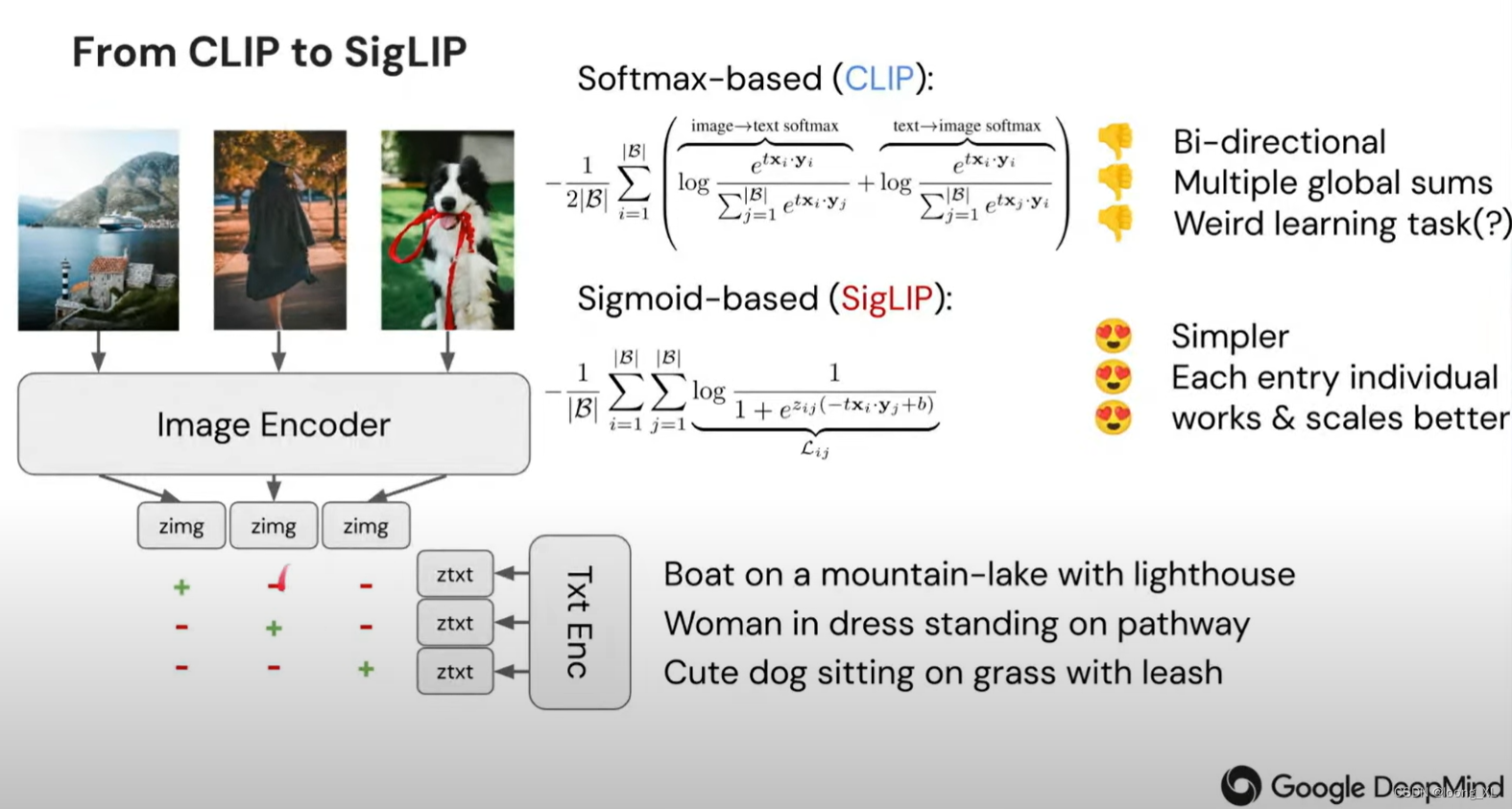
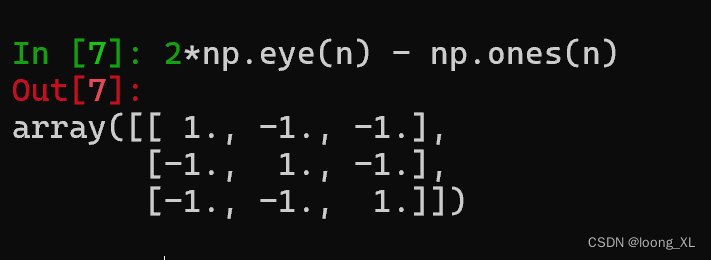
参考: https://github.com/openai/CLIP 简单理解两者区别 CLIP:batch内的图文对做多分类softmax;比如下图第一行表示第一个文本与batch内哪个图片匹配(多分类);除了行还计算列,比如第一列表示第一个图片与batch内哪个文本匹配 SigLIP:batch内的图文对做二分类sigmod;比如下图第一行表示 第一个文本分别与batch内每个图片做二分类 计算损失-代码实现 CLIP SigLIP 2*np.eye(n) - np.ones(n) 构建了label的矩阵,-1或者1的二分类;例如下列n=3









 超级会员免费看
超级会员免费看

 本文介绍了CLIP和SigLIP两种文本图像配对算法的区别。CLIP通过图文对进行多分类softmax计算,而SigLIP则采用二分类sigmoid策略。此外,文章还提供了计算损失的代码实现。
本文介绍了CLIP和SigLIP两种文本图像配对算法的区别。CLIP通过图文对进行多分类softmax计算,而SigLIP则采用二分类sigmoid策略。此外,文章还提供了计算损失的代码实现。




















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








