







小白学Pytorch系列–Torch.nn API Normalization Layers(7)

| 方法 | 注释 |
|---|---|
| nn.BatchNorm1d | 在2D或3D输入上应用批归一化,如论文批归一化:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 。 |
| nn.BatchNorm2d | 如本文所述,对4D输入(具有额外通道维度的2D输入的小批量)应用批量归一化Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift |
| nn.BatchNorm3d | 如本文所述,对5D输入(具有额外通道维度的3D输入的小批量)应用批归一化Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift |
| nn.LazyBatchNorm1d | torch.nn.BatchNorm1d模块,对从input.size(1)推断出的BatchNorm1d的num_features参数进行延迟初始化。 |
| nn.LazyBatchNorm2d | torch.nn.BatchNorm2d模块,对从input.size(1)推断出的1BatchNorm2d的num_features参数进行延迟初始化。 |
| nn.LazyBatchNorm3d | torch.nn.BatchNorm3d模块,对从input.size(1)推断出的BatchNorm3d的num_features参数进行延迟初始化。 |
| nn.GroupNorm | 如论文“Group归一化”所述,对小批输入应用Group归一化 |
| nn.SyncBatchNorm | 对n维输入(带有额外通道维度的[N-2]D输入的小批量)应用批归一化,如本文所述Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift . |
| nn.InstanceNorm1d | 如本文所述,在2D(非批处理)或3D(批处理)输入上应用实例规范化 Instance Normalization: The Missing Ingredient for Fast Stylization. |
| nn.InstanceNorm2d | 在4D输入上应用实例归一化(具有额外通道维度的2D输入的小批量),如论文所述Instance Normalization: The Missing Ingredient for Fast Stylization. |
| nn.InstanceNorm3d | 如文中所述,对5D输入(带有额外通道维度的小批量3D输入)应用实例规范化Instance Normalization: The Missing Ingredient for Fast Stylization. |
| nn.LazyInstanceNorm1d | torch.nn.InstanceNorm1d模块,对从input.size(1)推断出的InstanceNorm1d的num_features参数进行延迟初始化。 |
| nn.LazyInstanceNorm2d | torch.nn.InstanceNorm2d模块,对从input.size(1)推断的InstanceNorm2d的num_features参数进行延迟初始化。 |
| nn.LazyInstanceNorm3d | torch.nn.InstanceNorm3d模块,对从input.size(1)推断出的InstanceNorm3d的num_features参数进行延迟初始化。 |
| nn.LayerNorm | 在小批量输入上应用Layer Normalization,如论文层归一化所述 |
| nn.LocalResponseNorm | 在由多个输入平面组成的输入信号上应用局部响应归一化,其中通道占据了第二个维度。 |
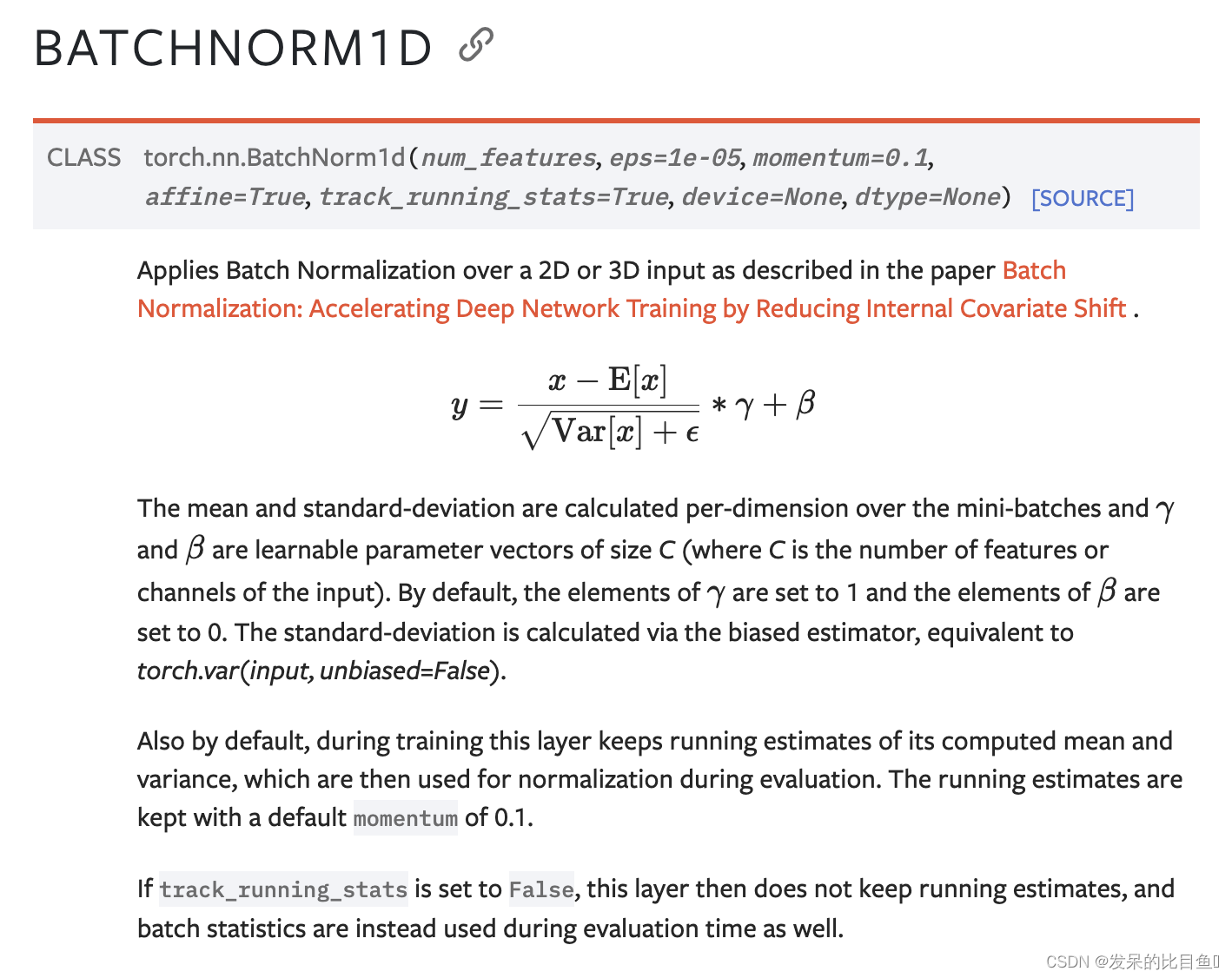
nn.BatchNorm1d
如本文所述,对2D或3D输入应用批处理归一化Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift .


>>> # With Learnable Parameters
>>> m = nn.BatchNorm1d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm1d(100, affine=False)
>>> input = torch.randn(20, 100)
>>> output = m(input)
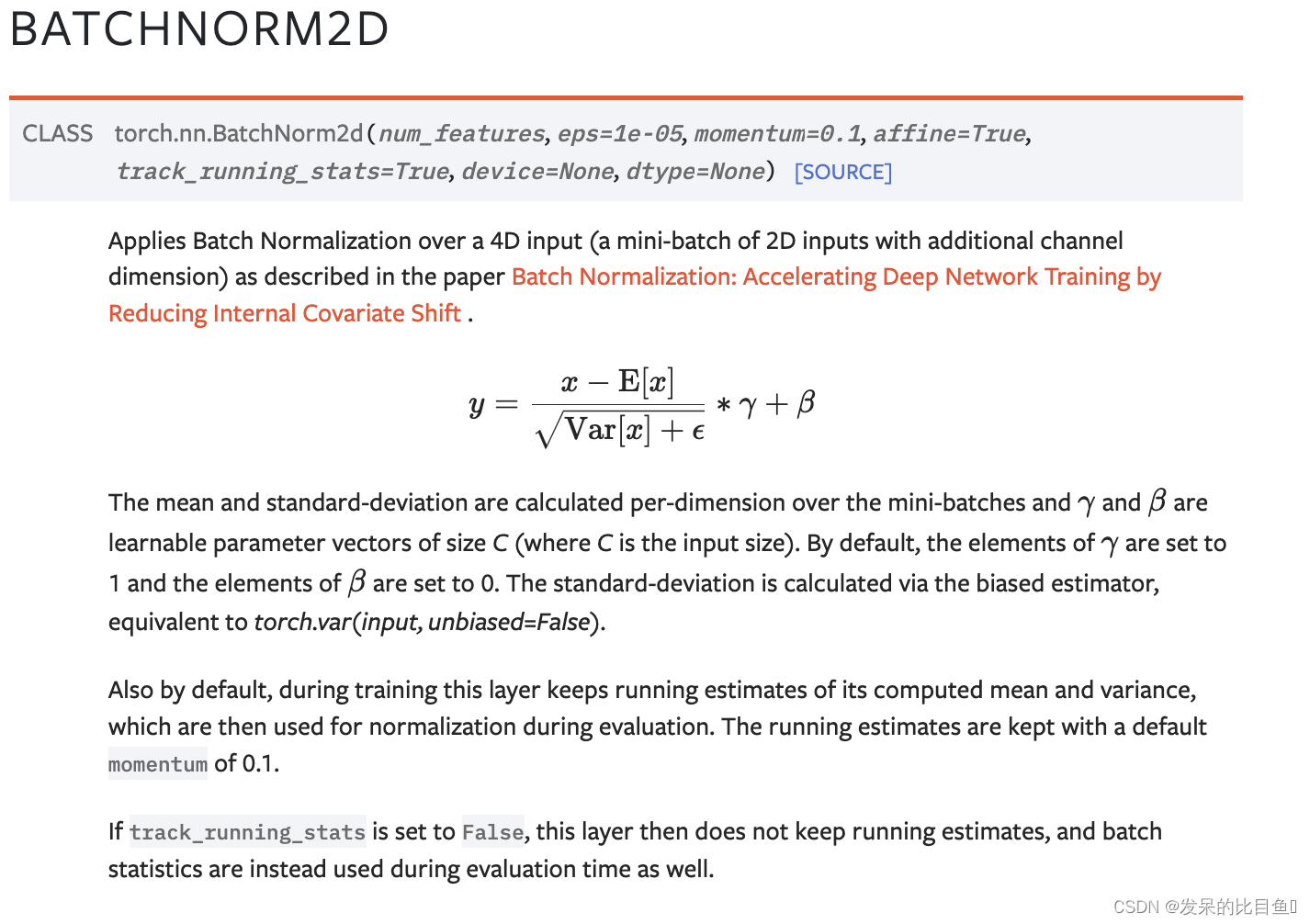
nn.BatchNorm2d


>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45)
>>> output = m(input)
nn.BatchNorm3d
如本文所述,对5D输入(具有额外通道维度的3D输入的小批量)应用批归一化 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift .



>>> # With Learnable Parameters
>>> m = nn.BatchNorm3d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm3d(100, affine=False)
>>> input = torch.randn(20, 100, 35, 45, 10)
>>> output = m(input)
nn.LazyBatchNorm1d
一个torch.nn.BatchNorm1d模块,对从input.size(1)推断出的BatchNorm1d的num_features参数进行延迟初始化。将延迟初始化的属性有weight、bias、running_m均值和running_var。

nn.LazyBatchNorm2d
torch.nn.BatchNorm2d模块,对从input.size(1)推断出的BatchNorm2d的num_features参数进行延迟初始化。将延迟初始化的属性有weight、bias、running_m均值和running_var。
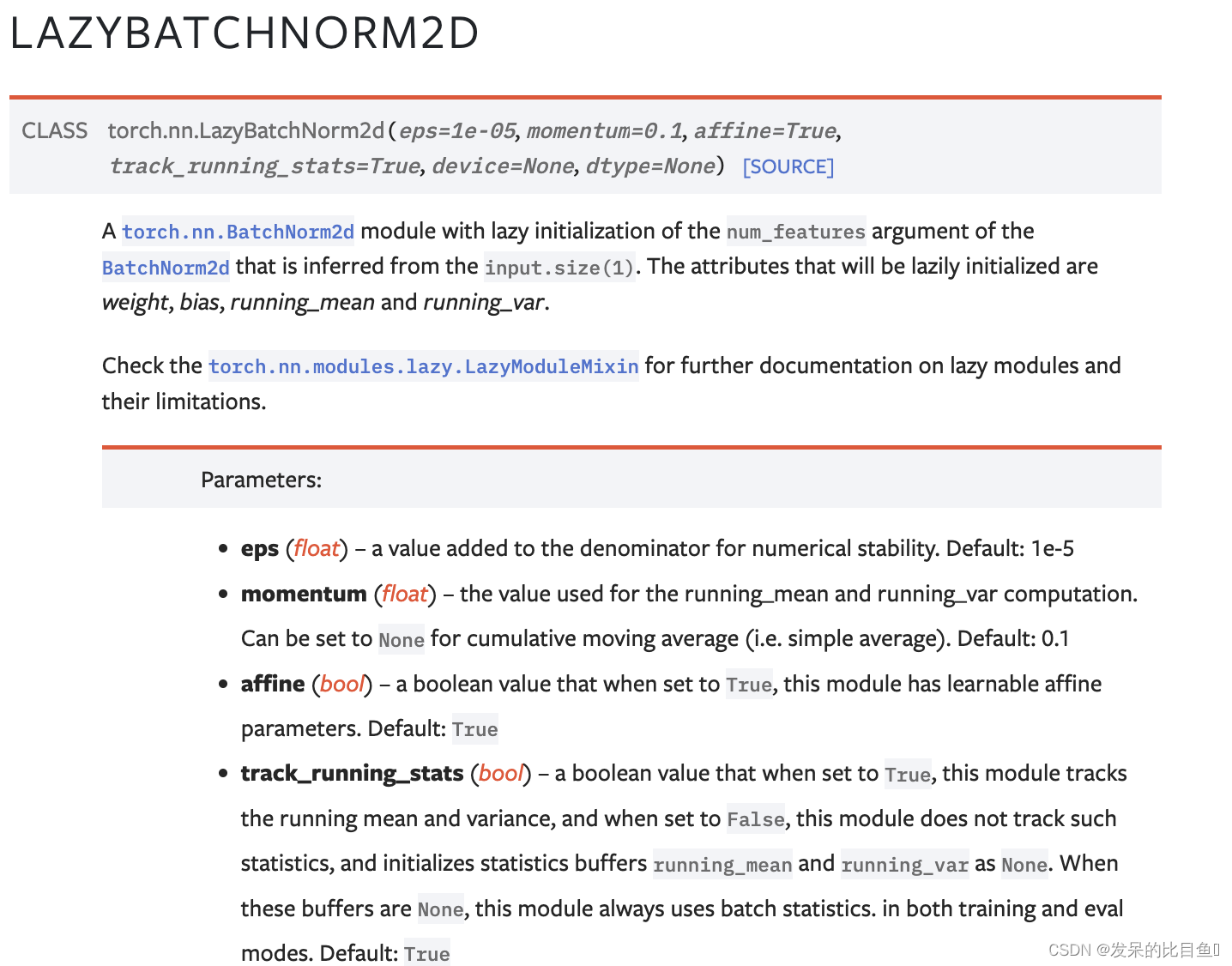
nn.LazyBatchNorm3d
torch.nn.BatchNorm3d模块,对从input.size(1)推断出的BatchNorm3d的num_features参数进行延迟初始化。将延迟初始化的属性有weight、bias、running_mean和running_var。

nn.GroupNorm
参考: https://zhuanlan.zhihu.com/p/150181052
如论文“组归一化”所述,对小批输入Group Normalization


>>> input = torch.randn(20, 6, 10, 10)
>>> # Separate 6 channels into 3 groups
>>> m = nn.GroupNorm(3, 6)
>>> # Separate 6 channels into 6 groups (equivalent with InstanceNorm)
>>> m = nn.GroupNorm(6, 6)
>>> # Put all 6 channels into a single group (equivalent with LayerNorm)
>>> m = nn.GroupNorm(1, 6)
>>> # Activating the module
>>> output = m(input)
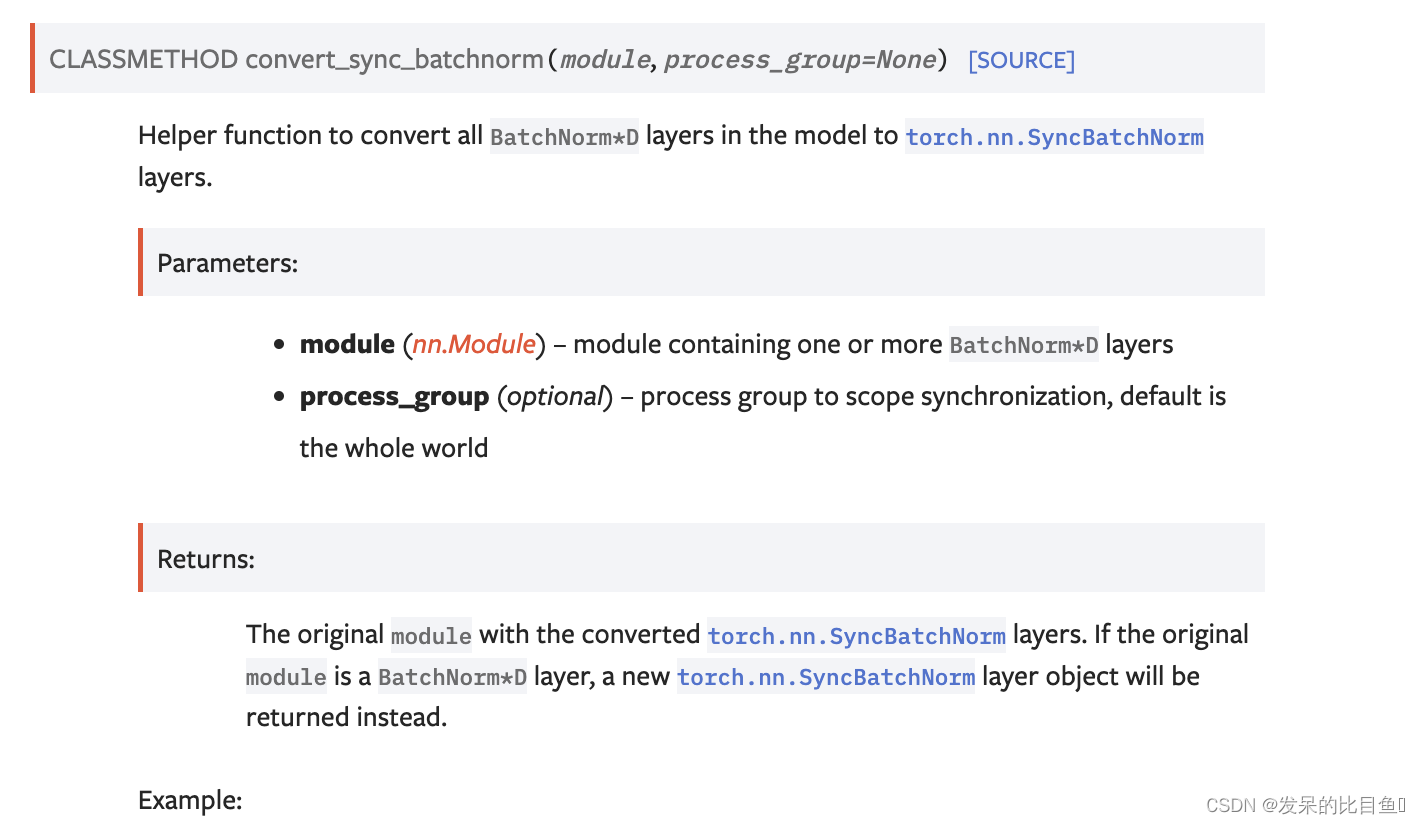
nn.SyncBatchNorm
参考: https://blog.csdn.net/flyingluohaipeng/article/details/127914647
SyncBN的原理很简单:SyncBN利用分布式通讯接口在各卡间进行通讯,从而能利用所有数据进行BN计算。为了尽可能地减少跨卡传输量,SyncBN做了一个关键的优化,即只传输各自进程的各自的 小batch mean和 小batch variance,而不是所有数据。
对n维输入(带有额外通道维度的[N-2]D输入的小批量)应用批归一化,如本文所述


>>> # With Learnable Parameters
>>> m = nn.SyncBatchNorm(100)
>>> # creating process group (optional)
>>> # ranks is a list of int identifying rank ids.
>>> ranks = list(range(8))
>>> r1, r2 = ranks[:4], ranks[4:]
>>> # Note: every rank calls into new_group for every
>>> # process group created, even if that rank is not
>>> # part of the group.
>>> process_groups = [torch.distributed.new_group(pids) for pids in [r1, r2]]
>>> process_group = process_groups[0 if dist.get_rank() <= 3 else 1]
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm3d(100, affine=False, process_group=process_group)
>>> input = torch.randn(20, 100, 35, 45, 10)
>>> output = m(input)
>>> # network is nn.BatchNorm layer
>>> sync_bn_network = nn.SyncBatchNorm.convert_sync_batchnorm(network, process_group)
>>> # only single gpu per process is currently supported
>>> ddp_sync_bn_network = torch.nn.parallel.DistributedDataParallel(
>>> sync_bn_network,
>>> device_ids=[args.local_rank],
>>>
>>> # Network with nn.BatchNorm layer
>>> module = torch.nn.Sequential(
>>> torch.nn.Linear(20, 100),
>>> torch.nn.BatchNorm1d(100),
>>> ).cuda()
>>> # creating process group (optional)
>>> # ranks is a list of int identifying rank ids.
>>> ranks = list(range(8))
>>> r1, r2 = ranks[:4], ranks[4:]
>>> # Note: every rank calls into new_group for every
>>> # process group created, even if that rank is not
>>> # part of the group.
>>> process_groups = [torch.distributed.new_group(pids) for pids in [r1, r2]]
>>> process_group = process_groups[0 if dist.get_rank() <= 3 else 1]
>>> sync_bn_module = torch.nn.SyncBatchNorm.convert_sync_batchnorm(module, process_group)
nn.InstanceNorm1d
如本文所述,在2D(非批处理)或3D(批处理)输入上应用实例规范化Instance Normalization: The Missing Ingredient for Fast Stylization


>>> # Without Learnable Parameters
>>> m = nn.InstanceNorm1d(100)
>>> # With Learnable Parameters
>>> m = nn.InstanceNorm1d(100, affine=True)
>>> input = torch.randn(20, 100, 40)
>>> output = m(input)
nn.InstanceNorm3d
如文中所述,对5D输入(带有额外通道维度的小批量3D输入)应用实例规范化


>>> # Without Learnable Parameters
>>> m = nn.InstanceNorm3d(100)
>>> # With Learnable Parameters
>>> m = nn.InstanceNorm3d(100, affine=True)
>>> input = torch.randn(20, 100, 35, 45, 10)
>>> output = m(input)
nn.LazyInstanceNorm1d
请查看torch.cn.modules.lazy.lazymodulemixin,以获得关于惰性模块及其局限性的进一步文档。


xxx
torch.nn.InstanceNorm2d模块,对从input.size(1)推断出的InstanceNorm2d的num_features参数进行延迟初始化。将延迟初始化的属性有weight、bias、running_mean和running_var。


nn.LazyInstanceNorm3d
torch.nn.InstanceNorm3d模块,对从input.size(1)推断出的InstanceNorm3d的num_features参数进行延迟初始化。将延迟初始化的属性有weight、bias、running_mean和running_var。

nn.LayerNorm
在小批量输入上应用层归一化,如论文层归一化所述


>>> # NLP Example
>>> batch, sentence_length, embedding_dim = 20, 5, 10
>>> embedding = torch.randn(batch, sentence_length, embedding_dim)
>>> layer_norm = nn.LayerNorm(embedding_dim)
>>> # Activate module
>>> layer_norm(embedding)
>>>
>>> # Image Example
>>> N, C, H, W = 20, 5, 10, 10
>>> input = torch.randn(N, C, H, W)
>>> # Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
>>> # as shown in the image below
>>> layer_norm = nn.LayerNorm([C, H, W])
>>> output = layer_norm(input)
nn.LocalResponseNorm
在由多个输入平面组成的输入信号上应用局部响应归一化,其中通道占据了第二个维度。跨通道应用归一化。

>>> lrn = nn.LocalResponseNorm(2)
>>> signal_2d = torch.randn(32, 5, 24, 24)
>>> signal_4d = torch.randn(16, 5, 7, 7, 7, 7)
>>> output_2d = lrn(signal_2d)
>>> output_4d = lrn(signal_4d)
















 6331
6331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











