







.py文件的python代码如下
#coding=utf-8
#作用:可以用来批处理图片进行分类
import os
import caffe
import numpy as np
root='D:/caffe-master/' #根目录
deploy=root+'zzfl/deploy.prototxt' #deploy文件的路径
caffe_model=root+'zzfl/fenlei__iter_40000.caffemodel.h5' #caffe_model的路径
mean_file=root+'zzfl/mean.npy' #mean_file的路径--注意,在python中要将mean.binaryproto转换为mean.npy格式
labels_filename=root+'zzfl/labels.txt' #sysset_words.txt的路径
#预读待分类的图片
import os
dir=root+'zzfl/val/'
filelist=[]
filenames=os.listdir(dir) #返回指定目录下的所有文件和目录名
for fn in filenames:
fullfilename=os.path.join(dir,fn) #os.path.join--拼接路径
filelist.append(fullfilename) #filelist里存储每个图片的路径
net=caffe.Net(deploy,caffe_model,caffe.TEST) #加载model和network
#图片预处理设置
transformer=caffe.io.Transformer({'data':net.blobs['data'].data.shape}) #设定图片的格式(1,3,28,28)
transformer.set_transpose('data',(2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
transformer.set_mean('data',np.load(mean_file).mean(1).mean(1)) #减去均值
transformer.set_raw_scale('data',255) #缩放到[0,255]之间
transformer.set_channel_swap('data',(2,1,0)) #交换通道,将图片由RGB变成BGR
#加载图片
for i in range(0,len(filelist)):
img=filelist[i] #获取当前图片的路径
print filenames[i] #打印当前图片的名称
im=caffe.io.load_image(img) #加载图片
net.blobs['data'].data[...]=transformer.preprocess('data',im) #执行上面的预处理操作,并将图片载入到blob中
#执行测试
out=net.forward()
labels=np.loadtxt(labels_filename,str,delimiter='/t') #读取类别名称文件
prob=net.blobs['prob'].data[0].flatten() #取出最后一层(prob)属于某个类标的概率值,'prob'为最后一层的名称
#print prob
index1=prob.argsort()[-1] #获取最大概率值对应的index
index2=prob.argsort()[-2] #获取第二大概率值对应的index
index3=prob.argsort()[-3] #获取第三大概率值对应的index
index4=prob.argsort()[-4] #获取第四大概率值对应的index
print labels[index1],'--',prob[index1] #输出label--prob
print labels[index2],'--',prob[index2]
print labels[index3],'--',prob[index3]
print labels[index4],'--',prob[index4]
-
运行结果
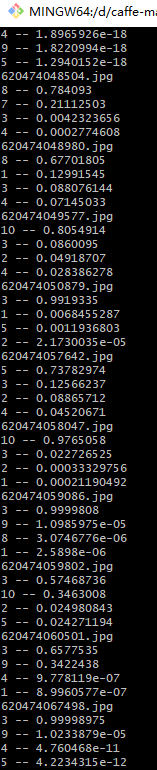
-
同时运行中有可能会爆出警告,如下图:

具体原因也在找,如果有大神遇到过类似问题已经解决,欢迎留言探讨!















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









