









在CV任务中,图像中的目标往往以不同的尺寸和形态出现,传统的单尺度处理方法难以同时捕捉这些目标的细节信息。
为解决这个问题,研究者们提出了即插即用多尺度融合模块:通过提取并融合不同尺度的特征,在保持高性能的同时,加强了模型对复杂场景的理解和处理能力。
另外,这种模块因为内部的优化设计,能无缝集成到现有深度学习模型中,无需修改原始模型,非常适合我们快速验证和应用,改善我们的模型性能。
为方便各位理解和使用,加速论文进度,我这次挑选了10个即插即用多尺度融合模块,基本都是最新的,已经开源的代码也附上了。
论文原文+开源代码需要的同学看文末
Semantic-aligned matching for enhanced detr convergence and multi-scale feature fusion
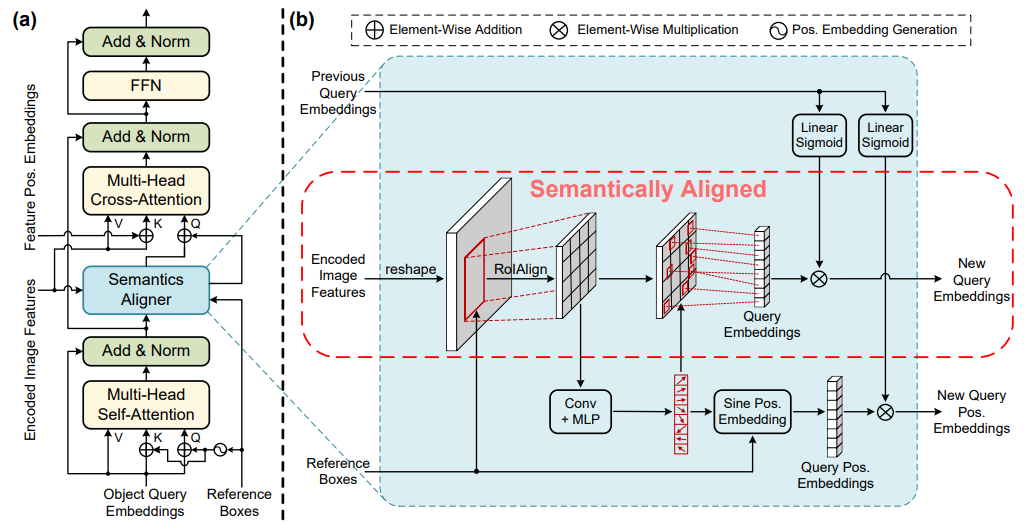
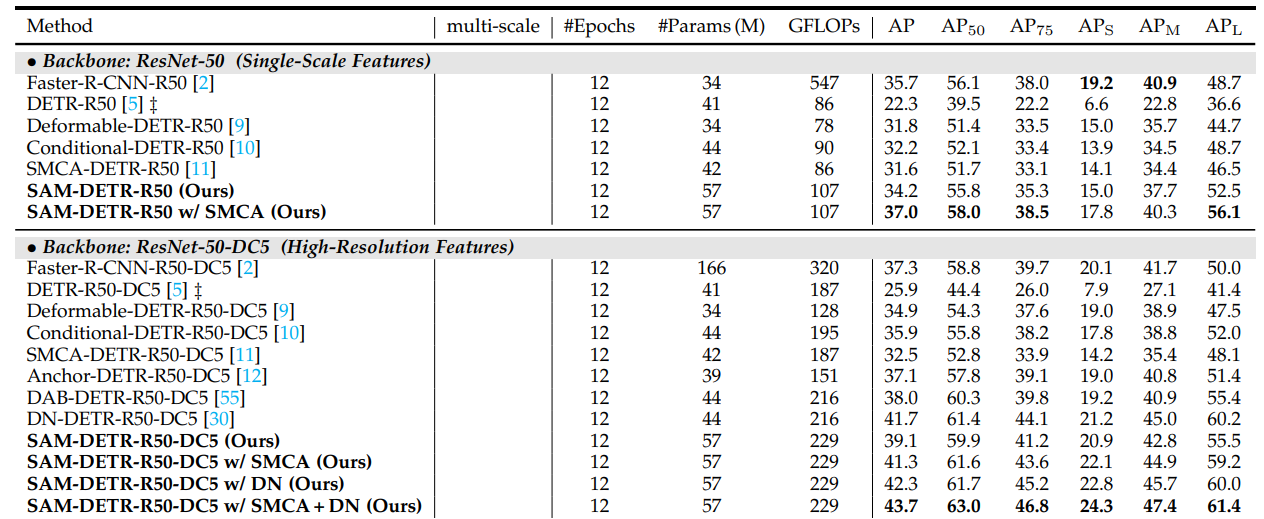
方法:本文提出了SAM-DETR++来加速DETR的收敛速度。SAM-DETR++模型实现了一种即插即用的多尺度特征融合方法。这种方法通过在DETR的框架内引入一个额外的模块来实现,该模块能够将不同尺度的特征有效地结合起来,以提高对象检测的性能。
创新点:
-
提出了SAM-DETR++,通过一个即插即用的模块加速了DETR的收敛,实现了目标查询和编码图像特征之间的语义对齐匹配。
-
提出了显式搜索目标代表性关键点并利用它们的特征进行语义对齐匹配的方法,进一步增强了引入的语义对齐匹配机制的表示能力。
-
将语义对齐匹配机制扩展到多尺度特征融合中,以粗到精的方式自适应地表示不同尺度的目标,从而实现更快的收敛速度和更优的检测性能。
Centralized Feature Pyramid for Object Detection
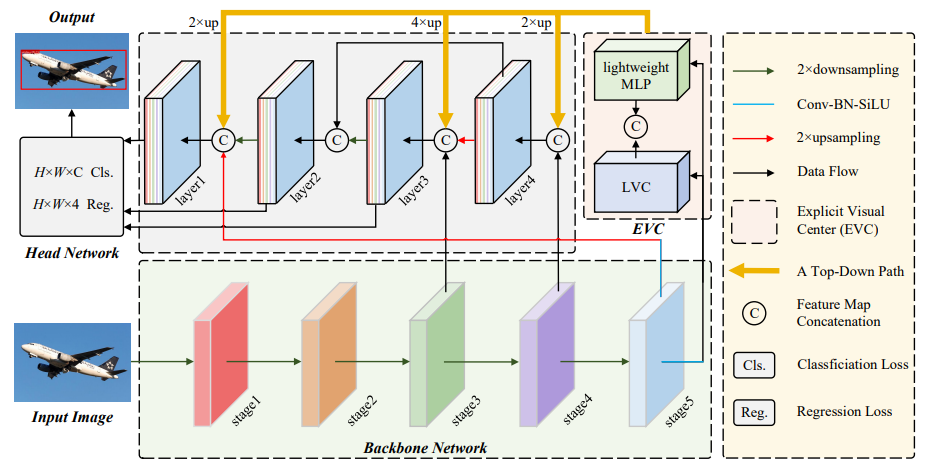
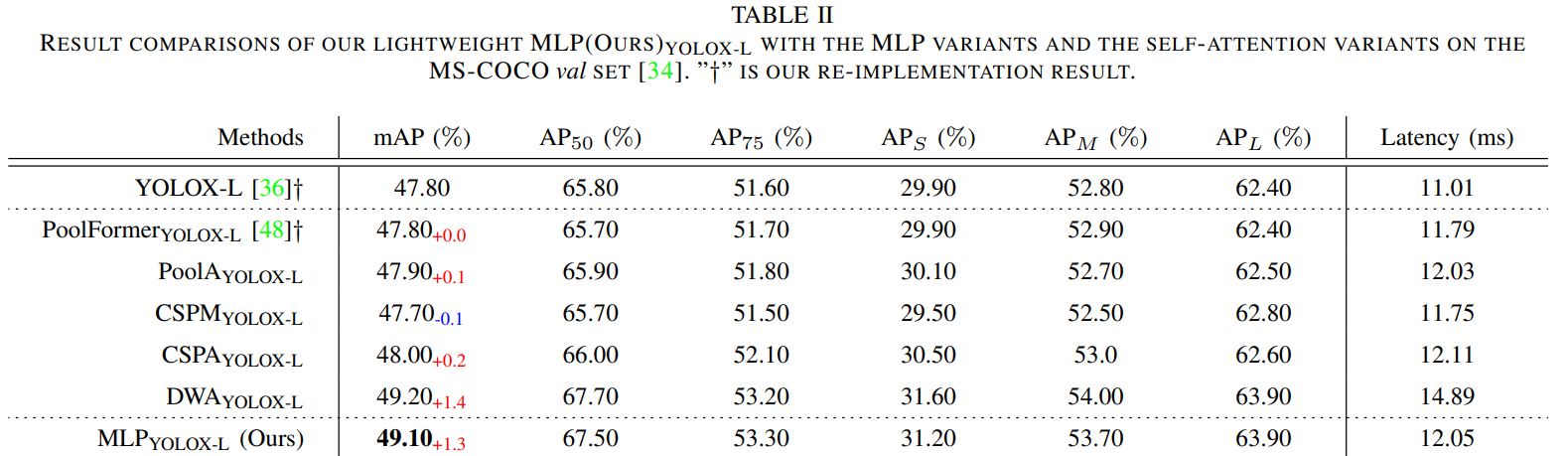
方法:论文介绍了目标检测中的一个新方法,称为CFP。该方法基于全局显式的中心特征调节,通过引入轻量级的多层感知机(MLP)来捕捉全局的长程依赖关系,并使用可学习的视觉中心来捕捉输入图像的局部角落区域。与现有方法相比,CFP不仅能够捕捉全局长距离依赖关系,还能够高效地获取全面而有区分性的特征表示。
创新点:
-
提出了一种基于全局显式中心化特征调节的CFP目标检测方法,该方法能够捕捉全局长距离依赖关系,并有效地获取全面而有区分性的特征表示。
-
提出了一种空间显式的视觉中心方案,利用轻量级MLP捕捉全局长距离依赖关系,并使用可并行学习的视觉中心来捕捉输入图像的局部角区域。
-
提出了一种自顶向下的特征金字塔的GCR方法,利用从最深层内部特征获得的显式视觉中心信息来调节所有前端浅层特征。
Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETR
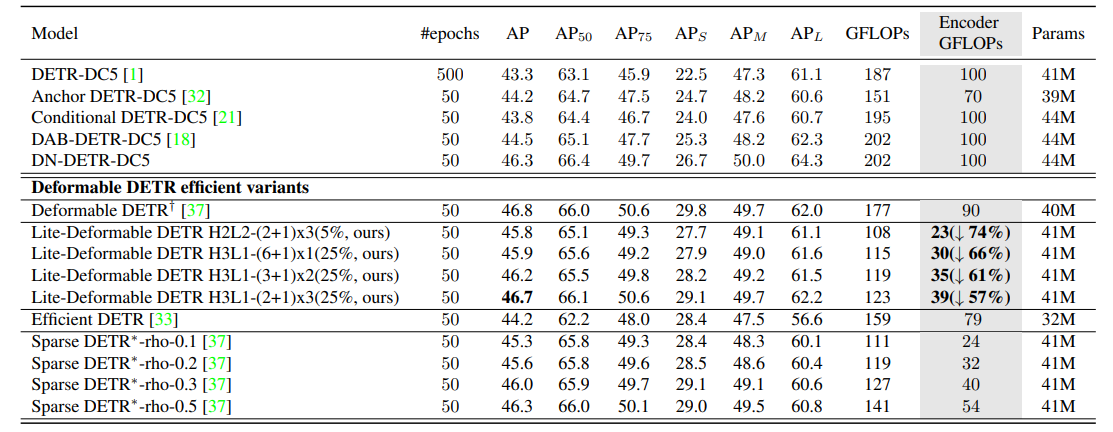
方法:主要讨论了一种高效的多尺度特征融合方法,用于改进基于Transformer的对象检测模型(如DETR)。作者将特征分为高级和低级特征,并通过交叉尺度融合的方式以不同频率更新特征,以实现性能和效率的平衡。此外,还引入了关键词感知的可变形注意力机制,提高了对小目标的检测性能。
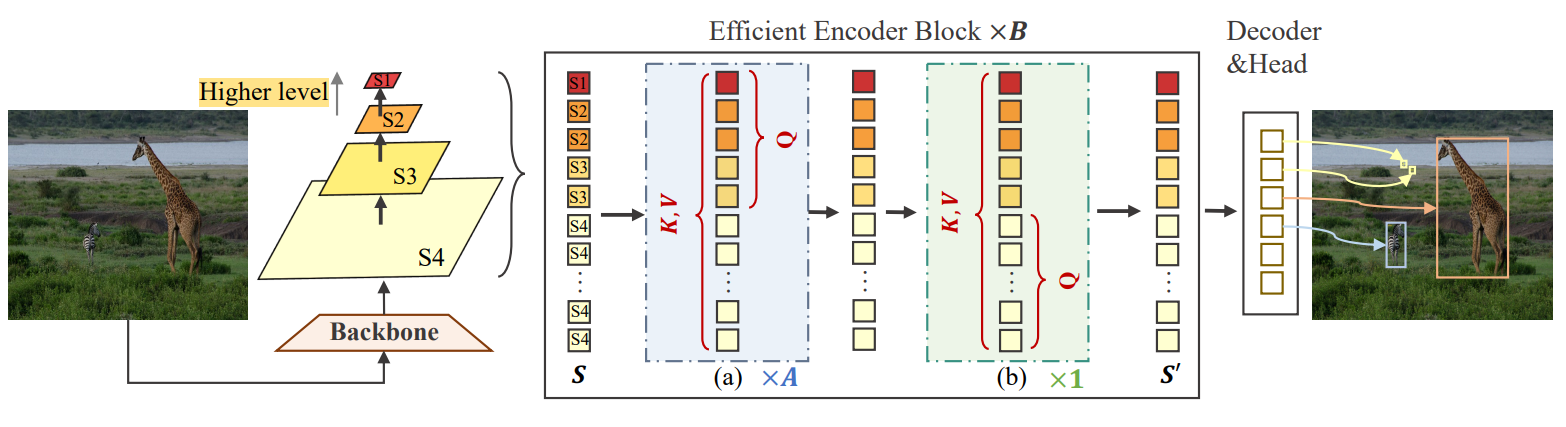
创新点:
-
Lite DETR:一种高效的DETR框架,通过交错更新多尺度特征并减少查询令牌,大幅降低计算成本同时保持高性能。
-
KDA(键感知可变形注意力):优化特征更新过程,通过缩放点积注意力提高多尺度特征融合的可靠性,增强小物体检测能力。
-
Lite DETR显著提升效率:计算成本降低60%,性能几乎无损(保持99%),易于集成到其他检测模型中。
MSF-Net: A Lightweight Multi-Scale Feature Fusion Network for Skin Lesion Segmentation
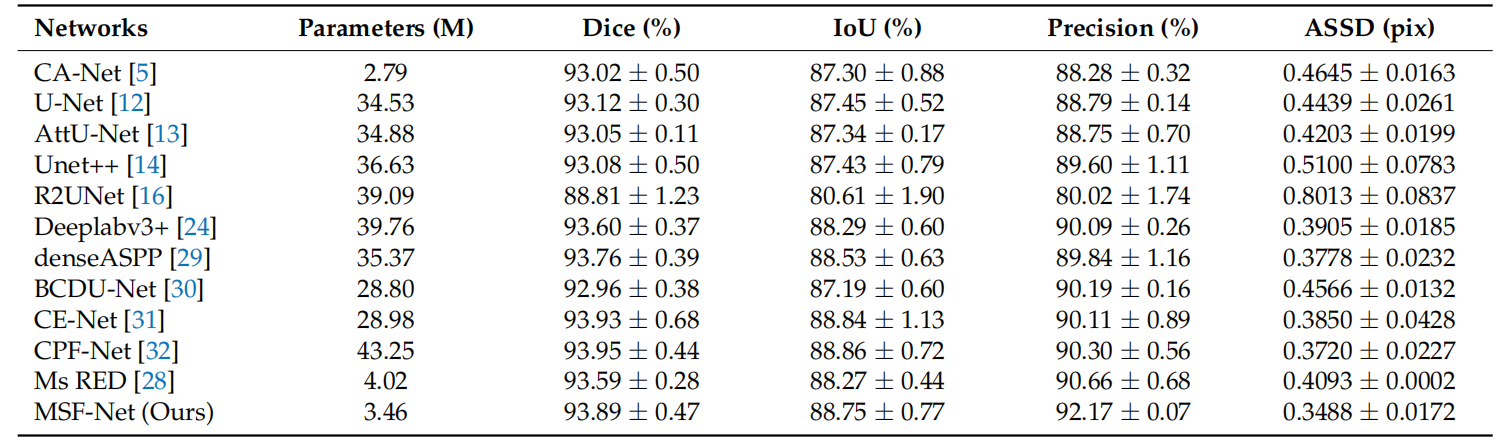
方法:论文提出了一个用于皮肤病变分割的轻量级多尺度特征融合网络(MSF-Net)。这个网络基于综合注意力卷积神经网络(CA-Net),并通过引入三个核心模块——S-Conv块、多尺度扩张卷积模块(MDC)和多尺度特征融合模块(MFF)——来实现即插即用(plug-and-play)的多尺度特征融合。
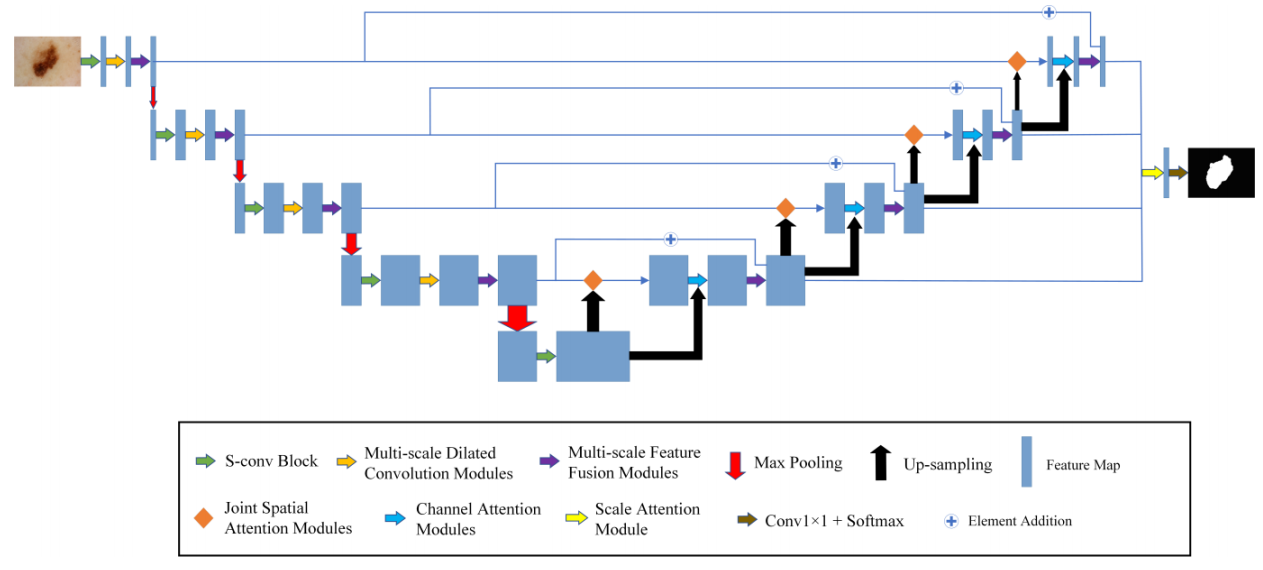
创新点:
-
MSF-Net引入了空间注意机制来调整图像像素的权重,专注于关键信息并抑制无关信息。
-
MDC模块通过并行的四个不同尺度的扩张卷积提取不同尺度的相关信息,并根据不同尺度的输入信息自适应调整特征图的感知域大小。
-
MFF模块用于融合不同尺度的相关信息,通过1×1卷积降低通道数,进一步提取特征。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“即插多尺度”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 3189
3189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









