









近年来,深度强化学习相关的成果在顶会顶刊上接受度普遍较高,经常上榜ICLR、Nature、Science等。比如ICLR 2025上的一篇Spotlight,由清华团队提出,介绍了一种SmODE网路,让深度强化学习的控制更加丝滑!
另外还有复旦、同济等联合提出的全新社区布局生成方法,也是基于深度强化学习...从这些成果来看,目前关于深度强化学习的研究多围绕应用、算法自身改进,以及与其他技术结合,尤其是结合注意力机制、GNN等,因为可以明显提升算法性能,已经成了顶会的大热选题。
如果想深入挖掘,除了以上这些角度,也可以考虑伦理与安全研究,比如公平性、隐私保护,更贴合社会需求。如果需要参考,可直接拿我整理的11篇深度强化学习新论文,代码基本有,无偿分享。
全部论文+开源代码需要的同学看文末
ODE-based Smoothing Neural Network for Reinforcement Learning Tasks
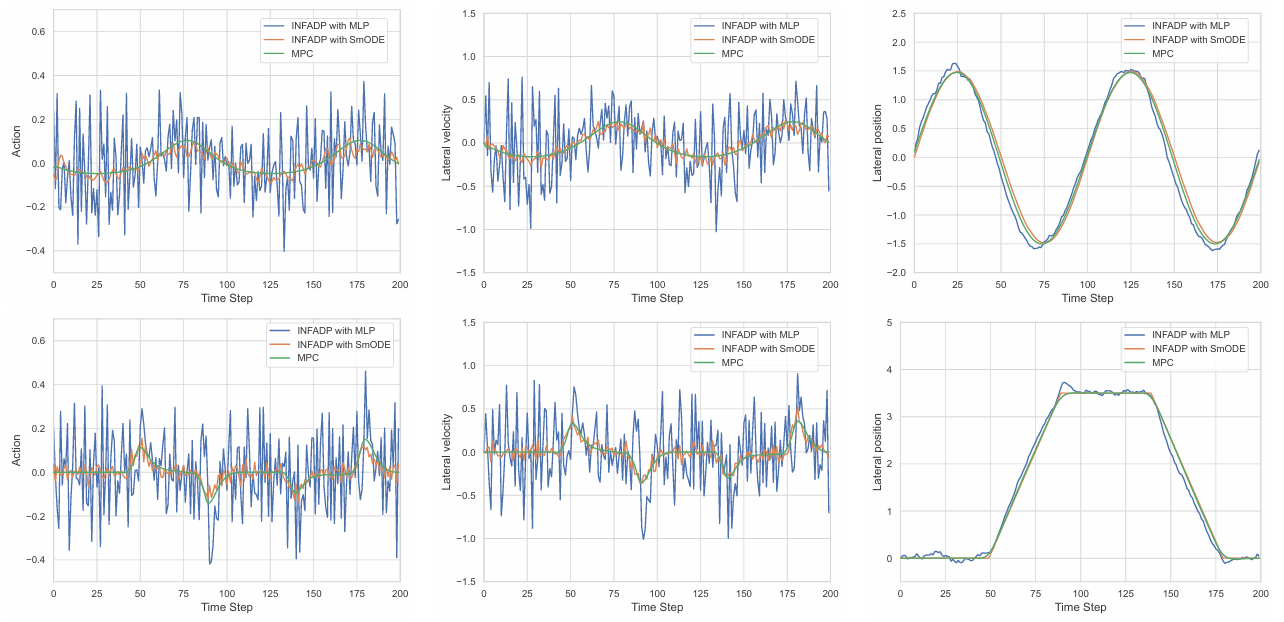
方法:论文提出了一种基于ODE的平滑神经网络(SmODE),用于深度强化学习任务,以解决控制动作不平滑的问题。SmODE通过低通滤波结构和可学习的状态依赖函数来抑制动作波动,并兼容多种强化学习算法。实验证明其在抗干扰和动作平滑性方面优于传统网络架构。
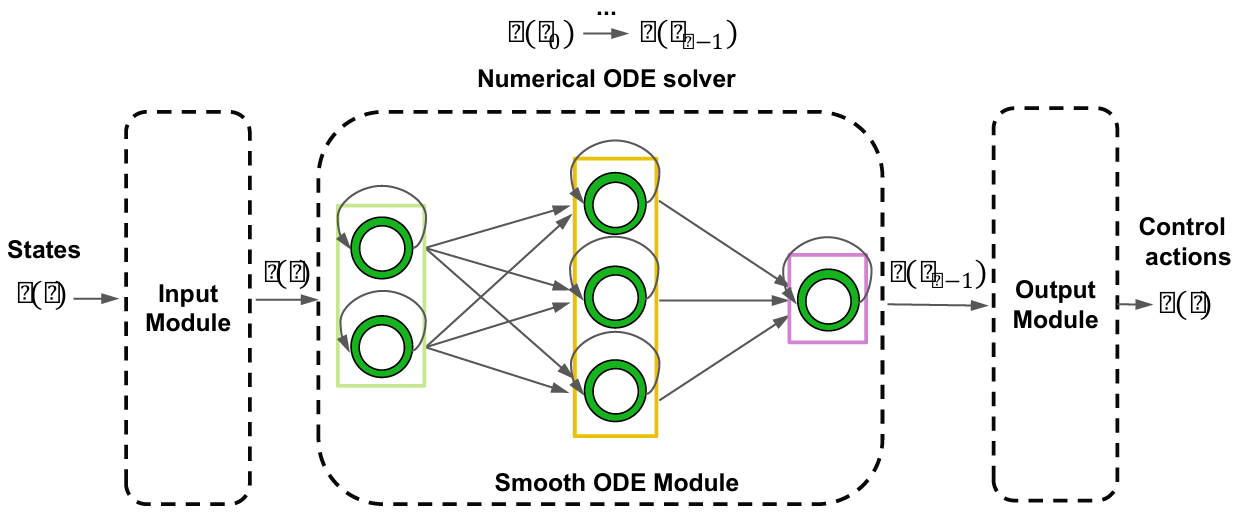
创新点:
-
提出了一种基于常微分方程的平滑神经元,能够动态过滤高频噪声并控制神经元的Lipschitz常数。
-
构建了SmODE网络,该网络包含输入模块、平滑ODE模块和输出模块,适用于多种强化学习算法。
-
在车辆轨迹跟踪、线性二次调节器和Mujoco机器人控制任务中验证了SmODE网络的优越性能。
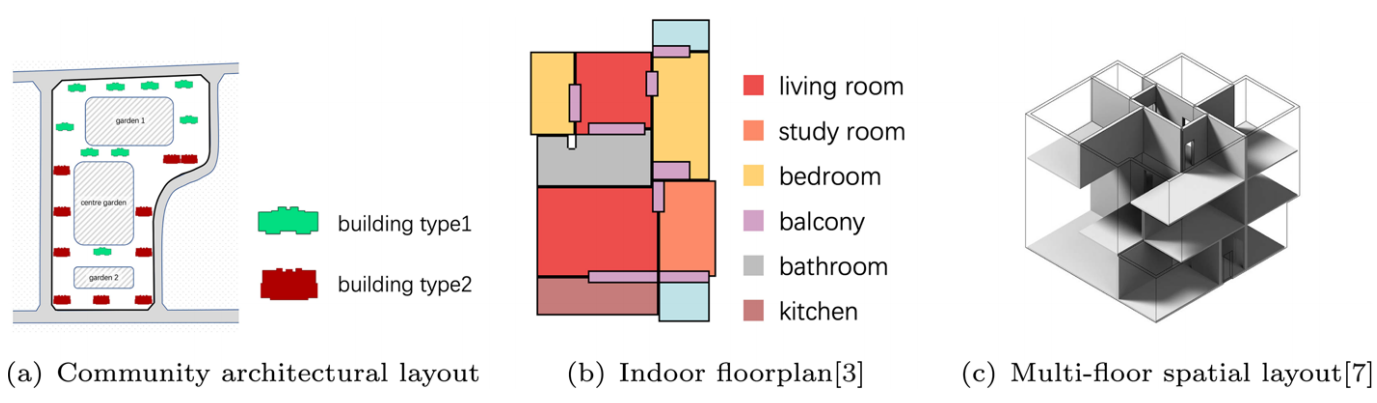
Deep reinforcement learning for community architectural layout generation
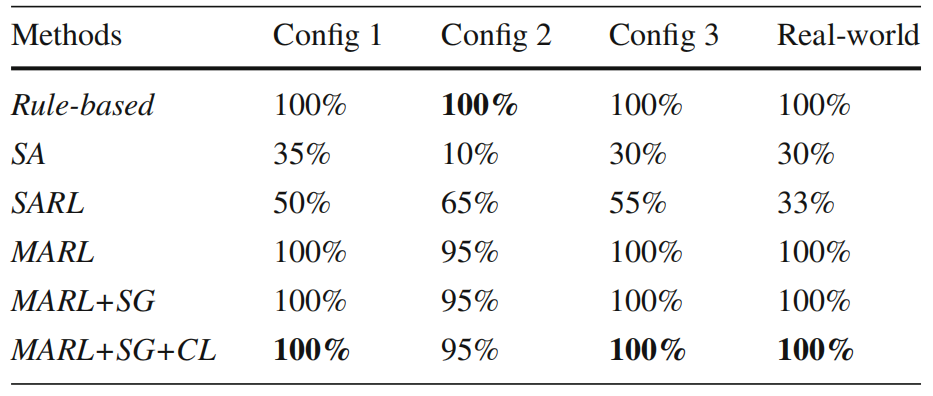
方法:论文提出了一种基于深度强化学习的方法,通过多智能体协作和课程学习策略,优化社区建筑布局的生成。该方法利用智能体动态调整建筑位置,并通过奖励函数引导布局的美观性和合理性,显著优于传统方法和其他基线方法。
创新点:
-
提出了一种基于深度强化学习的多智能体方法,用于社区建筑布局生成,能够动态调整建筑位置以优化整体布局。
-
引入课程学习策略,分阶段引导智能体训练,帮助平衡多个设计目标,提升模型性能。
-
设计了一个智能体序列生成器,优化智能体的动作顺序,提高在大规模复杂环境中的探索效率。
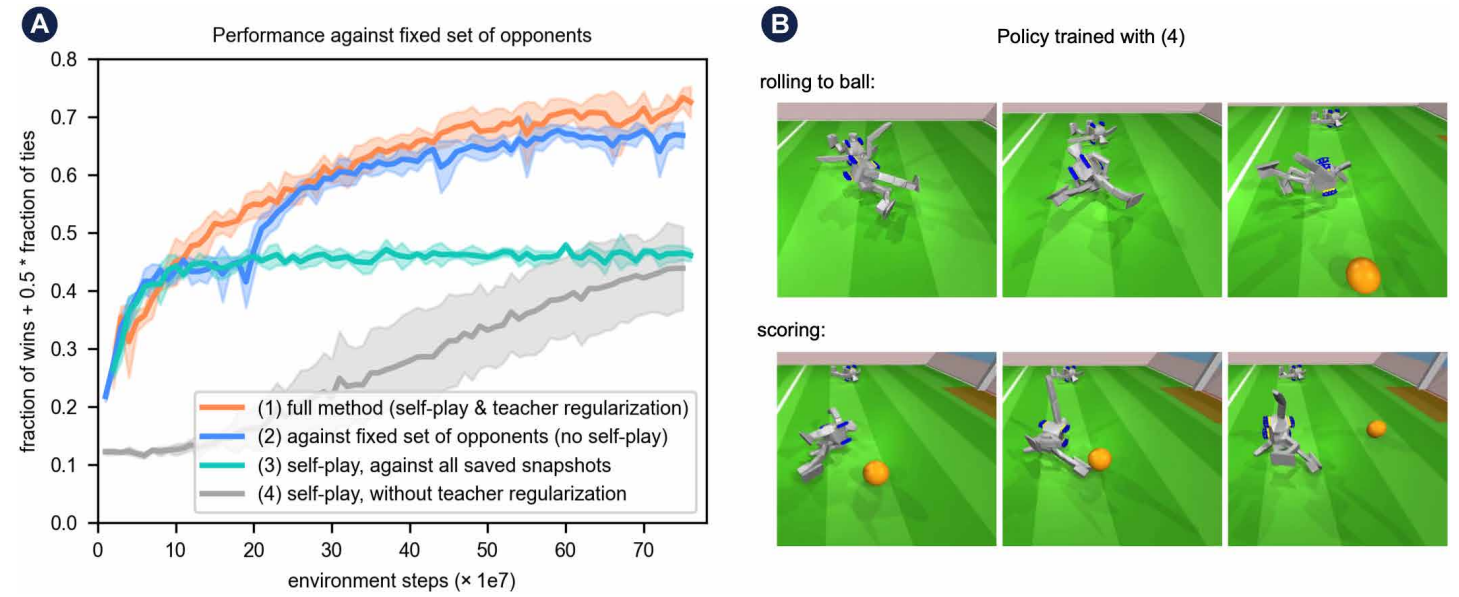
Learning agile soccer skills for a bipedal robot with deep reinforcement learning
science子刊(一区)
方法:论文使用深度强化学习训练微型仿人机器人踢足球,通过两阶段训练(先分别学习基础技能,再整合到一起),并结合模拟训练和零样本迁移,让机器人在现实环境中展现出优于传统控制器的敏捷运动技能。
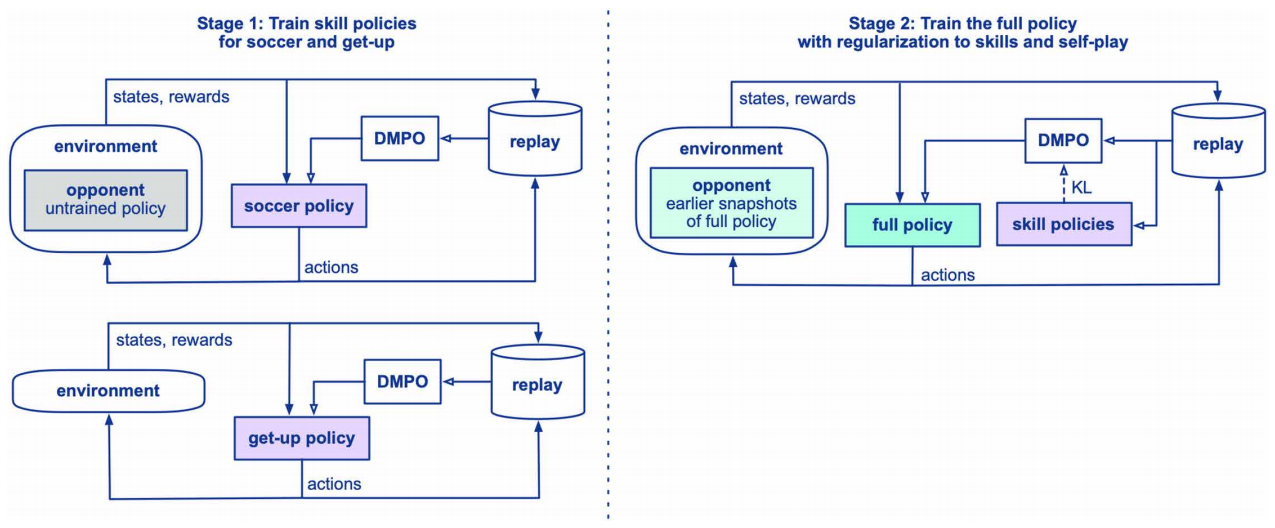
创新点:
-
采用两阶段训练,先分别学习起身和进球技能,再通过自我对弈整合技能。
-
实现了从模拟到现实机器人的零样本迁移,让机器人在现实环境中表现良好。
-
机器人在关键行为上优于传统基线控制器,展现出更高的运动效率和适应性。
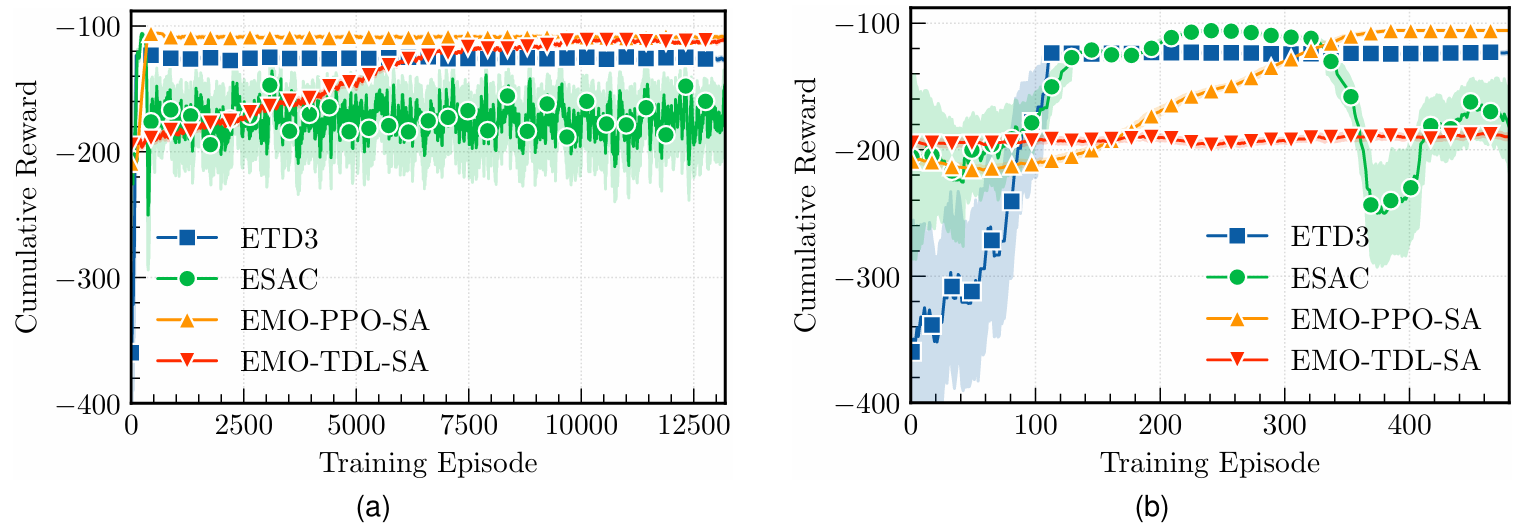
Task Delay and Energy Consumption Minimization for Low-altitude MEC via Evolutionary Multi-objective Deep Reinforcement Learning
方法:本文提出了一种基于进化多目标深度强化学习的方法,用于优化低空无人机辅助移动边缘计算系统中的任务延迟和能耗。通过将问题建模为多目标马尔可夫决策过程,并结合模拟退火算法简化任务调度,再利用进化多目标DRL框架和目标分布学习算法,动态调整权重并优化策略,最终实现了稳定的Pareto最优解。
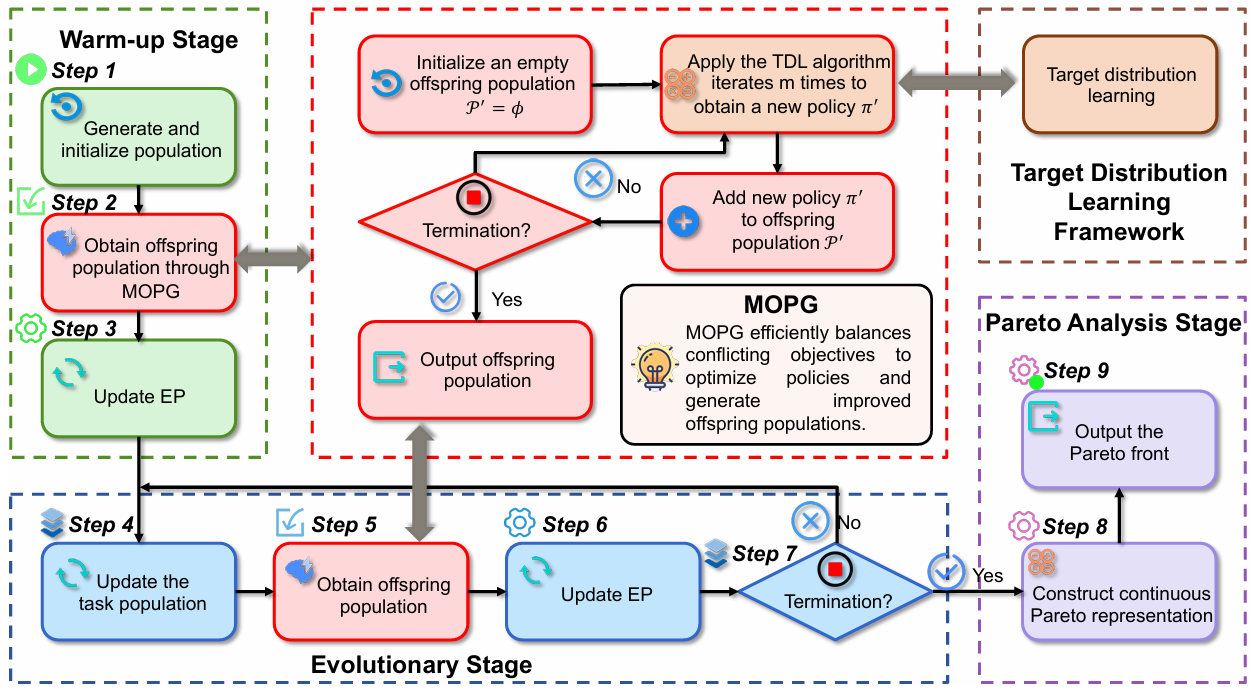
创新点:
-
提出进化多目标深度强化学习框架,解决无人机辅助MEC中的任务延迟和能耗问题。
-
使用模拟退火算法简化任务调度,将其转化为有效的MOMDP,降低问题复杂度。
-
结合目标分布学习优化策略更新,提高算法的稳定性和收敛性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









