




2021
Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
code: https://paperswithcode.com/paper/joint-multi-object-detection-and-tracking
摘要:采用相机-激光雷达融合的多目标跟踪(MOT)需要准确的目标检测、亲和性计算和数据关联的实时结果。本文提出了一种有效的多模态MOT框架,具有在线联合检测和跟踪方案和鲁棒数据关联。这项工作的新颖之处包括: (1)开发一个端到端深度神经网络,用于联合目标的二维检测和相关;(2)开发一个鲁棒的亲和计算模块来计算三维空间的遮挡感知外观和运动亲和度;(3)开发一个综合数据关联模块,用于检测置信度、亲和力和起止概率之间的联合优化。在KITTI跟踪基准上的实验结果表明,该方法在跟踪精度和处理速度方面都具有优越的性能。

论文的贡献:
- 开发一个端到端网络,可以同时从摄像机和激光雷达测量中生成3D边界框和关联评分,用于实时联合检测和跟踪。
- 开发一个鲁棒的亲和度计算模块,结合多模态特征和三维运动预测与鲁棒的亲和度量。
- 开发一个综合的数据关联模块,同时考虑检测不确定性和对象相关置信度。
- 在KITTI跟踪基准[1]上进行实验。我们的方法在跟踪精度和处理速度方面都优于基线。

2022
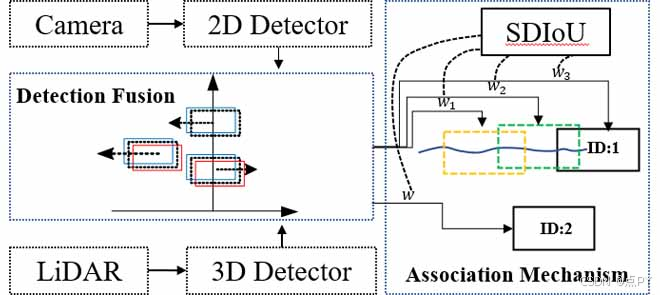
StrongFusionMOT: A Multi-Object Tracking Method Based on LiDAR-Camera Fusion
摘要: 本文提出了一种名为 StrongFusionMOT 的多目标跟踪(MOT)方法,该方法融合了光检测和测距(LiDAR)和相机传感器的信息。所提出的 StrongFusionMOT 的主要贡献体现在三个方面。首先,在检测融合阶段,将通过绝对差(AD)普查提取的深度信息补充到2D检测中,以促进2D和3D检测的融合。这种检测融合模式增强了融合鲁棒性并提供了准确的融合性能。其次,提出了一种名为形状距离交并(SDIoU)的新成本函数设计,不仅考虑了两个边界框之间的交集,还考虑了它们的形状和相对距离。这种代价函数消除了现有 IoU 设计的缺点,大大提高了关联精度。第三,针对重新出现的轨迹,提出了一种涉及过去帧中的轨迹的多帧匹配机制,该机制有效地抑制了连续帧轨迹预测带来的累积误差,并大大增强了关联鲁棒性。通过使用 KITTI 数据集和 nuScenes 数据集与最先进的 MOT 解决方案进行比较实验,评估了所提出的 StrongFusionMOT 的有效性。定量和定性结果都证明了所提出的方法在各种性能指标方面的优越性。
DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion with Deep Association
code: https://paperswithcode.com/paper/deepfusionmot-a-3d-multi-object-tracking#code
摘要:在最近的文献中,一方面,许多三维多目标跟踪(MOT)的工作都集中在跟踪精度和忽略计算速度上,通常是通过设计相当复杂的代价函数和特征提取器。另一方面,一些方法过于关注计算速度,而牺牲了跟踪精度。针对这些问题,本文提出了一种鲁棒的、快速的基于摄像机-激光雷达融合的MOT方法,该方法在精度和速度之间实现了良好的权衡。基于照相机和激光雷达传感器的特点,设计了一种有效的深度关联机制,并嵌入到所提出的MOT方法中。这种关联机制实现跟踪的对象在二维域当对象很遥远,只有发现相机,和更新的2D轨迹与三维信息获得当对象出现在激光雷达视场实现平滑融合的2D和3D轨迹。基于典型数据集的大量实验表明,我们提出的方法在跟踪精度和处理速度方面都比目前最先进的MOT方法具有明显的优势。
论文贡献
- 提出了一种基于摄像机-激光雷达融合的三维实时跟踪框架,在典型的跟踪数据集上实现了优越的MOT性能。
- 提出了一种充分利用摄像机和激光雷达特性的新的深度关联机制。这种机制不涉及任何复杂的成本函数或特征提取网络,同时有效地融合了二维和三维轨迹。
- 所提出的跟踪框架具有快速的计算速度,并易于实时实现。
- 所提出的跟踪框架可以与任意的二维和三维检测器结合使用,这使得它广泛适用于各种场景,无需额外的训练。

2024
Tightly Coupled Integration of LiDAR and Vision for 3D Multiobject Tracking
摘要:三维(3D)多目标跟踪(MOT)在新兴的智能交通系统(ITS)应用中发挥着关键作用,为周围物体提供准确可靠的运动信息,用于安全导航和运动规划。然而,基于视觉的方法容易受到遮挡的影响,而基于激光雷达的方法由于缺乏纹理信息而在目标识别方面遇到了困难,这给目标跟踪带来了挑战。为了克服这些传感器本身固有的局限性,我们提出了一种基于融合的3D MOT系统,该系统将激光雷达和视觉测量紧密结合。具体来说,我们首先设计一个聚合关联度量,融合来自激光雷达和图像域的检测和几何特征,以有效地跟踪对象。在此基础上,将所有相关的多模态测量值进一步集成到一个统一的因子图优化框架中,以细化所跟踪的二维和三维轨迹。在公共数据集上进行的大量实验表明,我们的系统在目标定位精度和MOT性能方面都显著优于最先进的基于融合的MOT方法。
论文的贡献:
- 我们开发了一种新的聚合关联度量,它融合了多模态检测和几何特征,以有效地关联检测与轨道。
- 提出了一种在统一因子图优化框架内的多模态对象束调整(BA),通过紧密集成激光雷达和视觉测量值来优化跟踪轨迹。
- 提出了一种激光雷达-视觉的三维多目标跟踪系统,并在公共数据集上进行了广泛的验证,实现了最先进的MOT性能。


Multi-Object Tracking with Camera-LiDAR Fusion for Autonomous Driving
摘要: 本文提出了一种结合照相机和激光雷达数据的自动驾驶汽车多模态多目标跟踪(MOT)算法。相机帧使用最先进的三维物体探测器进行处理,而经典的聚类技术被用于处理激光雷达的观测结果。所提出的MOT算法包括一个三步进关联过程、一个用于估计每个被检测到的动态障碍的运动的扩展卡尔曼滤波器和一个轨迹管理阶段。EKF运动模型需要当前测量的被观测物体的相对位置和方向,以及自我车辆的纵向和角速度作为输入。与大多数最先进的多模态MOT方法不同,所提出的算法不依赖于地图或自我全局姿态的知识。此外,它使用了一个专门用于相机的3D探测器,并且不知道所使用的激光雷达传感器的类型。本文提出了一种结合照相机和激光雷达数据的自动驾驶汽车多模态多目标跟踪(MOT)算法。相机帧使用最先进的三维物体探测器进行处理,而经典的聚类技术被用于处理激光雷达的观测结果。所提出的MOT算法包括一个三步进关联过程、一个用于估计每个被检测到的动态障碍的运动的扩展卡尔曼滤波器和一个轨迹管理阶段。EKF运动模型需要当前测量的被观测物体的相对位置和方向,以及自我车辆的纵向和角速度作为输入。与大多数最先进的多模态MOT方法不同,所提出的算法不依赖于地图或自我全局姿态的知识。此外,它使用了一个专门用于相机的3D探测器,并且不知道所使用的激光雷达传感器的类型。

论文的贡献:
- 我们的方法使用了一个EKF来跟踪每个物体和一个新的运动模型来估计一个物体的绝对纵向和角速度。EKF运动模型只需要被观测物体的当前测量的相对位置和方向以及自我载体的纵向和角速度作为输入,而不依赖于地图或自我全局姿态的知识。
- 扩展的卡尔曼滤波器接受一个可以具有不同维数的测量向量。具体来说,激光雷达提供的测量值被处理并用于校正位置(x,y),而方向(ψ)则通过利用相机提供的测量值进行校正。根据在每个时刻可用的测量值,EKF可以校正所有三个值(x、y、ψ)或它们的一个子集。
- 提出的方法使用3D探测器[12]专门用于相机,不像文献中大多数多模态方法,后者使用3D探测器用于激光雷达和相机测量。激光雷达质心的计算采用了欧氏聚类算法,该算法加速了整个算法管道的执行,并确保了快速执行。此外,基于激光雷达的探测器往往强烈依赖于点云的结构,点云的结构根据所使用的激光雷达的类型而有显著差异。相反,所提出的方法是不知道所使用的激光雷达传感器的类型。

融合相机与激光雷达的目标检测、跟踪与预测
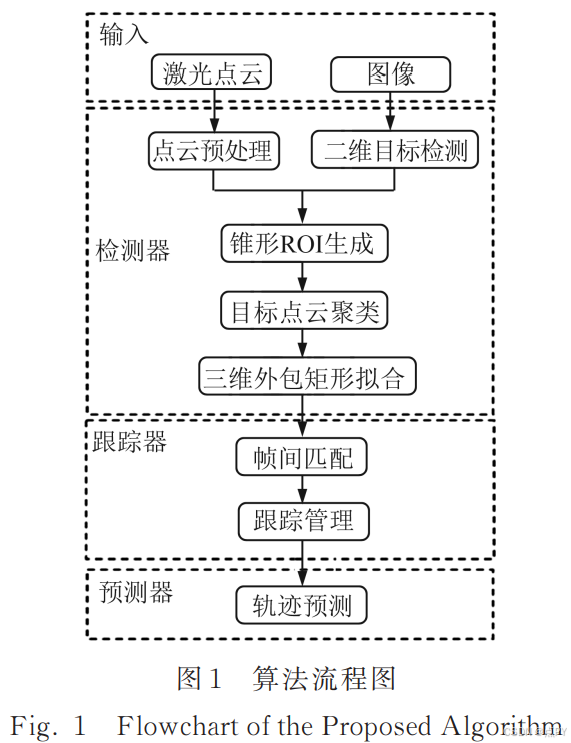
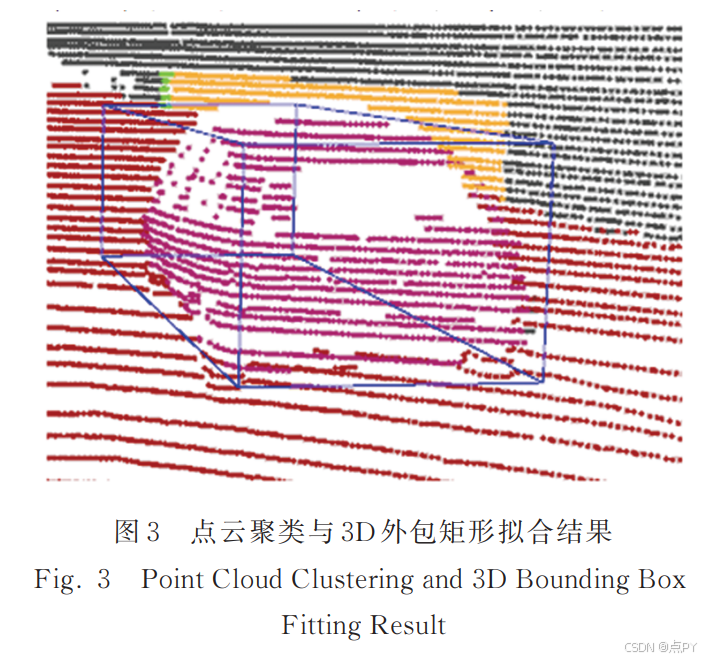
摘要:实时、鲁棒的三维动态目标感知系统是自动驾驶技术的关键。提出了一种融合单目相机和激光雷达的三维目标检测流程,首先,在图像上使用卷积神经网络进行二维目标检测,根据几何投影关系生成锥形感兴趣区域(region of interest,ROI),在 ROI 内对点云进行聚类,并拟合三维外包矩形;然后,基于外观特征和匈牙利算法对三维目标进行帧间匹配,并提出了一种基于四元有限状态机的跟踪器管理模型;最后,设计了一种利用车道信息的轨迹预测模型,对车辆轨迹进行预测。实验结果表明,在目标检测阶段,所提算法的准确率和召回率分别达到了 92.5% 和 86.7%。在仿真数据集上对轨迹预测算法进行测试,与现有算法相比,所提算法在直线、弧线和缓和曲线 3 种类型的车道上均有较小的均方根误差,且算法平均耗时约为 25 ms,满足实时性要求。所提算法鲁棒、有效,在不同车道模型下均有较好的结果。


















 6368
6368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











