







灾难性遗忘 (catastrophic forgetting) 现象是在连续学习多个任务的过程中,学习新知识的过程会迅速破坏之前获得的信息,而导致模型性能在旧任务中急剧下降,持续学习的过程如下图a 所示。灾难遗忘问题多年来一 直被人们所认识并被广泛报道,尤其是在计算机视觉领域,现在微调大语言模型也面临灾难性遗忘的问题,这个问题也出现在LLM微调和训练中。
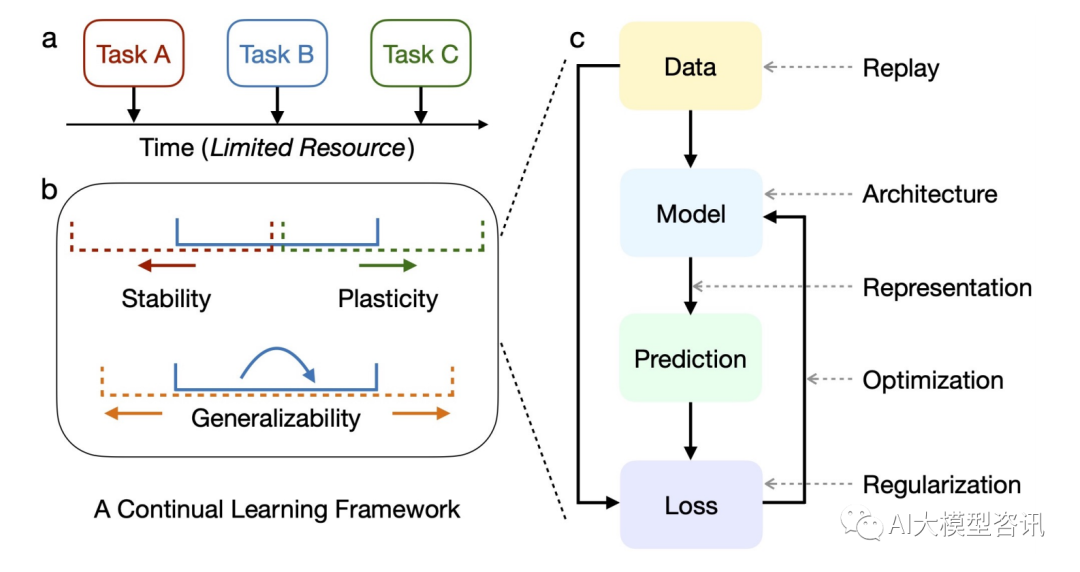
持续学习的概念框架示意图
造成灾难性遗忘的一个主要原因是, 传统模型假设数据分布是固定或平稳的, 训练样本是独立同分布的, 所 以模型可以一遍又一遍地看到所有任务相同的数据, 但当数据变为连续的数据流时, 训练数据的分布就是非平稳的, 模型从非平稳的数据分布中持续不断地获取知识时, 新知识会干扰旧知识, 从而导致模型性能的快速下 降, 甚至完全覆盖或遗忘以前学习到的旧知识。为了克服灾难性遗忘, 我们希望模型一方面必须表现出从新数 据中整合新知识和提炼已有知识的能力 (可塑性),另一方面又必须防止新输入对已有知识的显著干扰 (稳定性)。 这两个互相冲突的需求构成了所谓的稳定性-可塑性困境 (stability-plasticity dilemma)。如上图b 所示, 理想的解 决方案应确保稳定性(红色箭头) 和可塑性(绿色箭头) 之间的适当平衡, 以及对任务内(蓝色箭头) 和任务间 (橙色箭头)分布差异的泛化性。
持续学习是一种能够缓解深度学习模型灾难性遗忘的机器学习方法, 包括正则化方法、记忆回放方法和参 数孤立等方法, 为了扩展模型的适应能力, 让模型能够在不同时刻学习不同任务的知识, 即模型学习到的数据 分布, 持续学习算法必须在保留旧知识与学习新知识之间取得平衡, 上图c 中展示了模型在学习过程中各个部 分的代表性策略。
解决灾难性遗忘最简单粗暴的方案就是使用所有已知的数据重新训练网络参数, 以适应数据分布随时间的 变化。尽管从头训练模型的确完全解决了灾难性遗忘问题, 但这种方法效率非常低, 极大地阻碍了模型实时地 学习新数据。而增量学习的主要目标就是在计算和存储资源有限的条件下,在稳定性-可塑性困境中寻找效用最 大的平衡点。
对于 LLM 中的灾难性遗忘, 往往会过拟合小型微调数据集, 导致在其他任务上表现不佳。有学者提出了各 种方法来缓解 LLM 微调中的灾难性遗忘问题, 包括预训练的权重衰减, 学习率衰减、对抗性微调和参数高效微 调。然而, 这种灾难性的遗忘现象尚未得到彻底研究, 需要我们持续关注。下图中列出了一些代表性的持续学习方法。
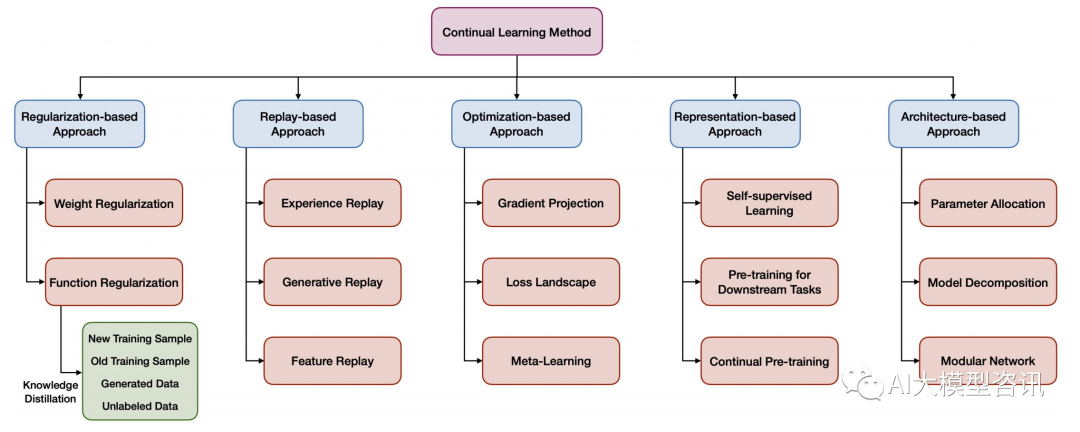
代表性持续学习方法的分类示意图
ps:欢迎扫码关注公众号^_^.


















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









