







文章提出了一种新颖的对齐方法,旨在改善视频大型多模态模型(VLMMs)的视频与文本之间的对齐。该方法利用人工智能反馈的强化学习(RLAIF)来有效对齐视频和文本模态,减少对人类注释的依赖。文章通过引入上下文感知的奖励建模,专注于提高视频内容的清晰度和理解力,同时扩展监督微调(SFT)模型的训练数据,并应用简单的课程学习策略,增强了模型的训练效果。实验结果表明,所提出的VLM-RLAIF模型框架在多项视频理解基准测试中显著优于现有方法,展现了良好的泛化能力。
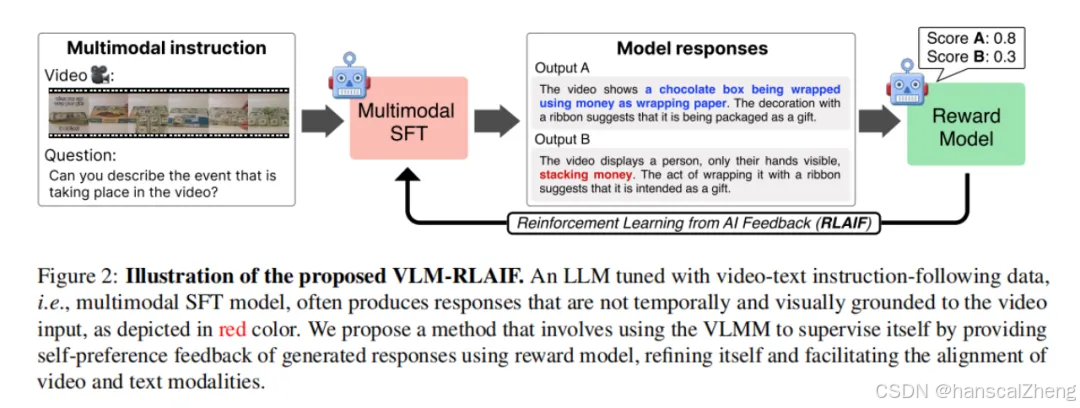
1 VLM-RLAIF框架
VLM-RLAIF框架主要包括四个模块:监督微调,基于人工智能反馈的奖励建模,从人工智能反馈中强化学习以及上下文感知的奖励建模。
1. 监督微调 (Supervised Fine-Tuning):
·首先对大型语言模型(LLM)进行监督微调,使用合成生成的视频-文本指令调优数据,以提升模型遵循指令的能力。
·结合视觉编码器和可学习参数,增强模型处理视觉内容的能力。
2. 基于人工智能反馈的奖励建模 (Reward Modeling with AI Feedback):
·利用预训练的AI模型生成相似于人类的偏好反馈,评估不同响应的优劣。
·通过评估生成的响应,训练奖励模型,以便为更优的响应分配更高的奖励分值,从而引导模型改进。
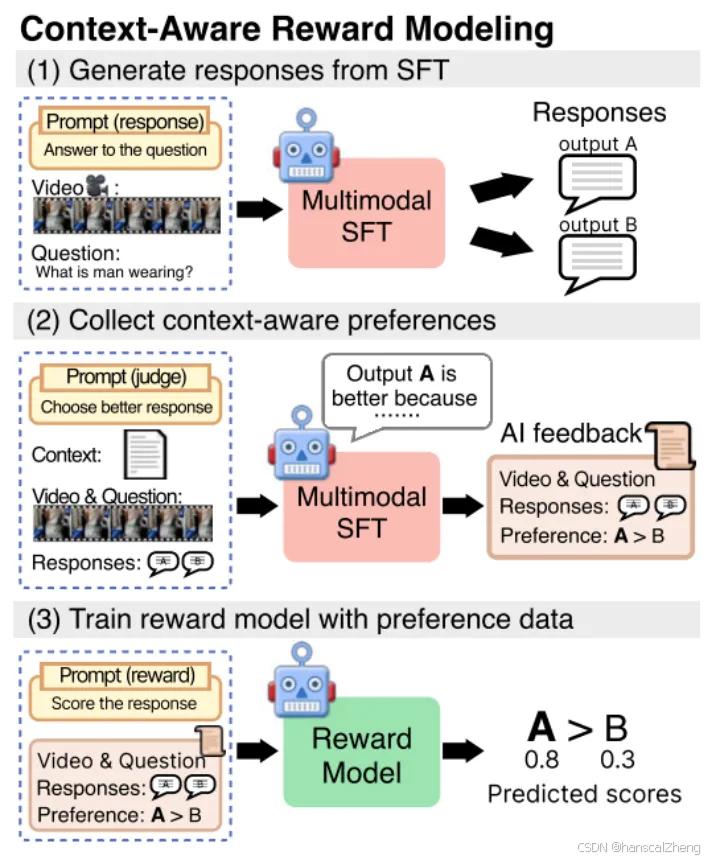
3. 从人工智能反馈中强化学习 (Reinforcement Learning from AI Feedback):
·在训练过程中,利用奖励模型对监督微调模型进行进一步优化,提升模型在生成视频相关响应时的表现。
·采用强化学习算法(如近端策略优化算法PPO),使得模型能够在自我反馈中进行调整和改进。
4. 上下文感知的奖励建模 (Context-Aware Reward Modeling):
·在奖励建模中引入详细的视频描述作为上下文,增强模型对视频内容的理解。
·通过将视频分段并生成详细的描述,改善模型在选择偏好时的上下文相关性,使得选择更具针对性和准确性。
· 两阶段课程监督微调 (Two-Stage Curriculum SFT):
·通过将数据集分为“简单”和“困难”两类,逐步提升模型的学习难度,先从简单任务入手,逐步过渡到复杂任务。
·这种课程学习策略旨在优化模型的指令跟随能力,帮助模型更有效地掌握复杂的视频-文本关系。
2 结语
文章提出了一种利用人工智能反馈强化学习(RLAIF)来优化视频大型多模态模型(VLMMs)的视频与文本对齐的方法,显著提升了模型在视频理解任务中的表现。
论文题目: Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
论文链接: https://arxiv.org/abs/2402.03746
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









