






摘要
我们的工作重新审视了规范的
ResNet
,并研究了这三个方面,试图将其理清。也许我们发现训练和扩展策略可能比架构更改更重要,此外,由此产生的ResNet
与最近最先进的模型相匹配。
我们证明了性能最好的缩放策略取决于训练方案,并提供了两种新的缩放策略
:
(
1
)在可能发生过拟合的方案中的缩放模型深度(否则最好是宽度缩放)
(
2
)提高图像分辨率的速度比之前建议的要慢。
使用改进的训练和缩放策略,我们设计了一系列
ResNet
架构,即
ResNet RS
,其在
TPU
上比
EfficientNets
快
介绍
不从改变
ResNet
的结构出发,而是
从训练和缩放策略的改变出发
。我们调查了当今广泛使用的现代训练和正则化技术,并将其应用于
ResNet
。在这个过程中,我们会遇到训练方法的相互作用,并显示出与其他正则化技术协同使用时降低权重衰减值的好处。表
1
对训练方法的
加性研究揭示了这些策略的显著影响;仅通过改进训练方法
。我们为扩展视觉架构提供了新的视角和实用的建议。虽然先前的工作从小模型或从少量时期的训练推断出缩放规则,但我们通过在整个训练持续时间内(例如
350
个
epoch
而不是
10
个
epoch
)在各种尺度上
详尽的训练模型来设计缩放策略。
在这样做的过程中,我们
发现了性能最佳的扩展策略和训练机制之间
的强烈依赖性(例如
epochs
大小、模型大小、数据集大小)
。这些依赖关系在任何一个较小的方案中都会被遗漏,从而导致次优的缩放决策。我们的分析得出了新的缩放策略
。总结为
(1)
当可能发生过拟合时缩放模型深度(否则最好缩放宽度)
(
2
)
比先前的工作更慢地缩放图像分辨率使用改进的训练和缩放策略,我们设计了重新缩放的ResNets
,
ResNet-RS
,它们在广泛的模型大小范围内进行训练。ResNet-RS
模型在训练过程中使用较少的内存,在速度精度
Pareto
曲线上,在
TPU
上比流行的Efficient
快。
最后,我们通过一系列实验来测试改进的训练和缩放策略的通用性。我们首先
使用我们的缩放策略
EfficientNet
设计了一个更快版本的
Efficient-RS
。它在精度
-
速度
Pareto
曲线上比原来的有所改进
。
贡献
1
、
正则化技术及其相互作用的实证研究,这导致了一种正则化策略,该策略在不改变模型架构的情况下
实现了强大的性能。
2
、
一种简单的缩放策略
:(
1
)当
可能发生过拟合时缩放深度(否则缩放宽度可能更可取)
,以及
(2)
比
以前的工作更慢地缩放图像分辨率
。这种缩放策略提高了
ResNet
和
EfficientNets
的速度精度
Pareto
曲线。
3
、
ResNet-RS
:通过应用训练和扩展策略,
ResNet
架构的
Pareto
曲线比
TPU
上的
EfficientNets
快
1,7x- 2,7x
总结
在整个训练持续时间内,通过设计缩放策略,发现了性能最佳的缩放策略和训练机制之间的强烈依赖性(例如epochs
大小、模型大小、数据集大小)。随后设计了一个自己的缩放策略。
贡献正则化技术及其相互作用的实证研究,这导致了一种正则化策略,该策略在不改变模型架构的情况下实现强大的性能。
一种简单的缩放策略
2、ImageNet的特征化改进
这些改进大致出现在四个正交轴上:架构、训练
/
正则化方法、缩放策略和使用额外的训练数据。
Architecture
:
近年来有很多架构被开发出来
Training and Regularization Metthods
:I
mageNet
的进步得益于训练和正则化方法的创新
。当训 练更多epoch
模型时,正则化方法,如
Dropout
、
label smoothing
、
stochastic depth
、
dropblock
和 数据扩充显著提高了泛化能力。改进的学习率计划进一步提高了最终的准确性。虽然在短期的非正规训练设置中对体系结构进行基准测试有助于与之前的工作进行公平的比较,但尚不清楚体系结构的改进是否能在更大范围内持续并改进训练设置。例如,RegNet架构在短时间的非正则化训练设置中显示出比基线更强的加速,但没有在最先进的ImageNet
设置中进行测试。
Scaling Stratefies
:增加模型尺寸(例如宽度、深度和分辨率)是提高质量的另一个成功轴。
sheer scale被详尽地证明了可以提高神经语言模型的性能,这推动了
GPT-3
和
Switch Transformer
在内的更大模型的设计。通常,ResNet
架构是通过增加层(深度)来扩大的,以层的数量为后缀的
ResNets
已经从ResNet-18发展到
ResNet-200
Wide ResNets
和
MobileNets
改为缩放宽度
。提高图像分辨率也是进步的可靠来源。因此,随着训练预算的增长,图像分辨率也在增长:EfficientNet
使用
600
个图像分辨率,
ResNetSt
和
TRsNet
的最大模型都使用448
个图像分辨率。为了使这些启发式方法系统化,
EfficientNet
提出了复合缩放规则,该规则建 议平衡网络的深度、宽度和图像分辨率。然而,第7.2
节显示,这种缩放策略不仅对
ResNet
是次优的, 而且对EfficientNets
也是次优的。
额外的训练数据
。另一种进一步提高准确性的流行方法是对额外的数据源(标记的、弱标记的或未标记的)进行训练。在大规模数据集上进行训练,大大推动了最先进的技术。
3、关于改进ResNets的相关工作
改进的训练方法与对
ResNet
的架构更改相结合,通常会产生有竞争力的
ImageNet
性能。
He
等人通过修改stem
和下采样块,同时使用标签平滑和混合,实现了
79.2%
的准确率。
Lee
等人
(
2020
)进一步改进了
ResNet-50
模型,对其进行了额外的架构修改,如挤压和激励(
Hu et al
,
2018
)、选择性内核(
Li et al
,
2019
)和抗混叠下采样(
Zhang
,
2019
),同时还使用了标签平滑 混合和丢弃块,实现了81.4%
的准确率。
Ridnik
等人(
2020
)对
ResNet
架构进行了几次架构修改,并
改进了训练方法,
以在速度
-
精度
Pareto
曲线上优于
EfficientNet-B1
至
EfficientNet-B5
模型 然而,大多数工作很少强调确定强有力的扩展策略。相比之下,我们只考虑自2018
年以来常规使用的轻量级架构更改,而专注于训练和缩放策略,以构建模型的Pareto
曲线。我们改进的训练和扩展方法使ResNets在
TPU
上比
EfficientNets
快
1.7
倍
-2.7
倍。我们的缩放改进与上述方法正交,我们希望它们是相加的。
4、方法
我们描述了
ResNet
的基本架构和本文中使用的训练方法。
4.1
架构
我们的工作研究了
ResNet
体系结构,包括两种广泛使用的体系结构变化,即
ResNet-D
修改了所有
neck
块中的挤压和激励(
SE
)
。这些体系结构更改用于许多已使用的体系结构,包括
TResNet
、
ResNetSt
和EfficientNets。
ResNet-D
。(
He et al ,2018)
结合了以下四个对原始
ResNet
架构的调整。首先,
茎中的
7x7
卷积被三个
较小的
3x3
卷积取代
,如
InceptionV3
首次提出的。其次,
对于下采样块的残差路径中的前两个卷积,切
换步长
。第三,
下采样块的跳跃连接路径中的
stride-2 1x1
卷积被
stride-2 2x2
平均池化和非
stride 1x1
卷积所取代
。第四,
去除了
stride-2 3x3
最大池化层,并在下一个瓶颈块中的第一个
3x3
卷积中进行下
采样
。在图
6
中描绘了这些修改。

Squeeze-and-Excitation
:通过对整个特征图中的信号进行平均汇集,通过跨通道相互作用重新加权通道。对于所有实验,我们在初步实验的基础上使用0.25
的挤压和激发比。在我们的实验中,我们有时使用没有SE
的原始
ResNet
实现(称为
ResNet)
来比较不同的训练方法。
4.2训练方法
我们研究了在最先进的分类模型和半
/
自监督学习中经常使用的正则化和数据扩充方法。
匹配
EfficientNet
设置,我们的训练方法与
EfficientNet
的训练方法非常匹配,在
EfficientNet
中我们训练 了350
个
epoch
,但有一些小的差异。
(
1
)为了简单起见,我们
使用余弦学习率计划(
Loshchilov&Hutter
,
2016
)而不是指数衰减(没有
额外的超参数)
(
2
)我们
在所有模型中使用
RandAugment
(
Cubuk
等人,
2019
),而
EfficientNets
最初是用
AutoAugment
(
Cubuk et al,2018
)训练的。我们用
RandAugment
重新运行了
EfficientNetsB0-B4
,发现它没有提供性能改进并用Cubuk
等人。
(3)
为了简单起见,
我们使用
momentem optimizer
而不是
RMSProp
。
Regularization(
正则化
)
。我们
将权重衰减、标签平滑、丢弃和随机深度(
weight decay, label
smoothing,
dropout and stochastic depth
)应用于正则化
。
Dropout
是计算机视觉中使用的一种常见技术,我们将其应用于最终层中发生全局平均池化后的输出。随机深度以作为层深度函数的特定概率丢弃网络中的每一层(其周围有剩余连接)。
数据增强
:我们
使用
RandAugment
数据扩充作为额外的正则化子
。
RandAugment
在训练期间对每个 图像独立地应用一系列随机图像变换(例如平移、剪切、颜色失真)。如前所述,最初EfficientNets
使用AutoAugment
,这是一种习得的增强程序,稍逊于
RandAugment
。
超参数调整
。为了选择各种正则化和训练方法的参数,我们使用了一个保留的验证集,该验证集包括 ImageNet训练集的
2%
。这种称为最小值集,原始
ImageNet
验证集被称为验证集。所有
ResNetRS
模型的超参数如附录B
中的表
8
所示。
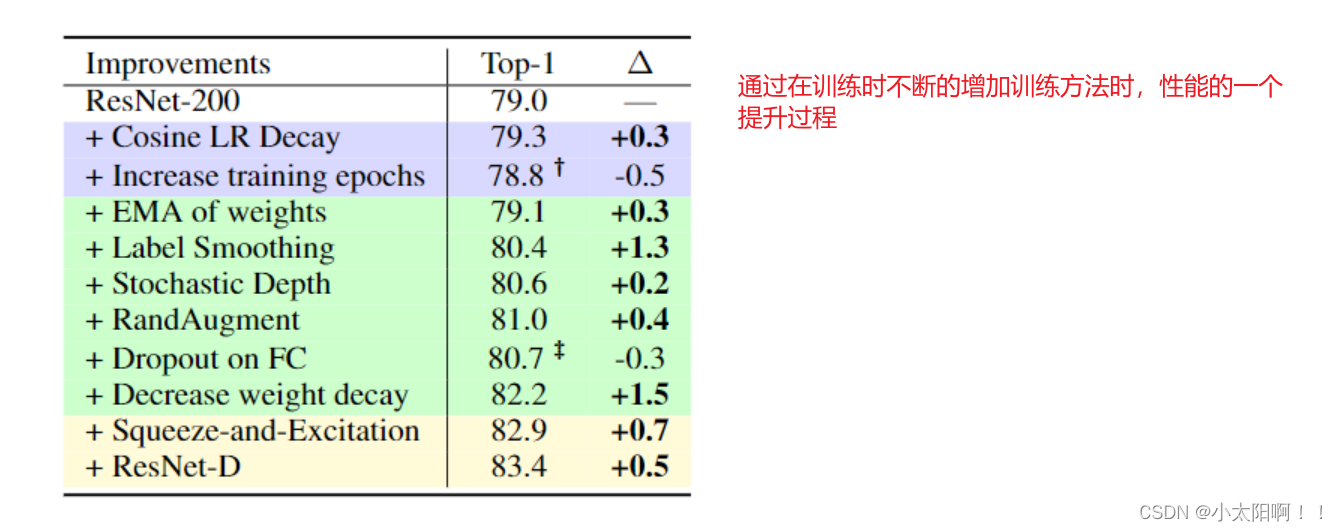
5、改进的训练方法
5.1
改进的加性研究
在表
1
中介绍了训练、正则化方法和架构更改的附加研究。基线
ResNet-200
的前
1
级准确率为
79.0%
。我们仅通过改进训练方法就将其性能提高到82.2%
,而没有任何架构更改。当添加两个常见且简单的体系结构更改(挤压和激励以及ResNet-D
)时,我们将其性能进一步提高到
83.4%
。仅训练方法就导致了总改进的3/4
。这表明了它们对
ImageNet
性能的关键影响。
5.2
组合正则化方法时减少权重衰减的重要性
表
2
强调了
将正则化方法结合在一起时改变权重衰减的重要性
。
应用
RandAugment
和标签平滑时,无
需更改
1e-4
的默认权重衰减
。但是,当我们进一步增加丢弃或随机深度时,性能可能会下降,除非我们进一步减少权重衰减。直觉是,由于权重衰减充当正则化子,因此在结合许多技术时,必须降低其值,以免过度正则化模型。此外,Zoph
等人提出的证据表明,数据扩充的增加缩小了权重的
L2
范数,这使得权重衰减的一些影响变得多余。其他工作使用较小的权重衰减值,但没有指出使用更多正则化时效果的重要性(Tan
等人,
2019
,
Tan&Le,2019
)。
总结
应用
RandAugment
和标签平滑时,无需更改
1e-4
的默认权重衰减。 但是,当进一步增加丢弃或随机深度时,性能可能会下降,除非进一步减少权重衰减。
6、改进的扩展策略
上一节展示了培训方法的重大影响,现在我们展示了扩展策略的重要性。为了建立缩放趋势,我们在 ImageNet上进行了广泛的搜索,宽度乘数为
[0.25,0.5,1.0,1.5,2.0]
,深度为
[26,50
,
101
,
200
,
300
, 350、
400]
,分辨率为
[128
,
160
,
224
,
320
,
448]
。我们模拟最先进的
ImageNet
模型的训练设置,对这些架构进行了350
个
epoch
的训练。我们随着模型大小的增加而增加正则化,以限制过拟合。正则化和模型超参数见附录E
。
FLOP
不能准确地预测有界函数体系中的性能
。先前关于缩放定律的工作观察到,在无界数据体系中,误差和FLOP
之间存在幂律。为了测试这是否也适用于我们的场景,我们在图
2
中描绘了所有缩放配置的ImageNet误差和
FLOP
的关系图。关于较小的模型,我们观察到误差和
FLOP
之间的总体幂律趋势,对缩放配置的依赖性较小(即深度与宽度与图像分辨率的关系)。然而,这种趋势打破了更大的模型寸。此外,我们观察到,对于固定量的FLOP
,
ImageNet
性能有很大变化,特别是在较高的
FLOP
方案中。因此,精确的缩放配置(即深度、宽度和图片分辨率)即使在控制相同数量的FLOP
时,也会对性能产生很大影响。
性能最佳的扩展策略取决于训练制度
。接下来,我们直接查看感兴趣的硬件上的延迟,以确定提高速度 精度Pareto
曲线的缩放策略。图
3
显示了在四种图像分辨率和三种不同训练模式(
10
、
100
和
350
个 epoch)下,以宽度或深度缩放的模型的准确性和延迟。我们观察到,性能最好的缩放策略,特别是是否缩放深度或宽度,在很大程度上取决于训练制度。
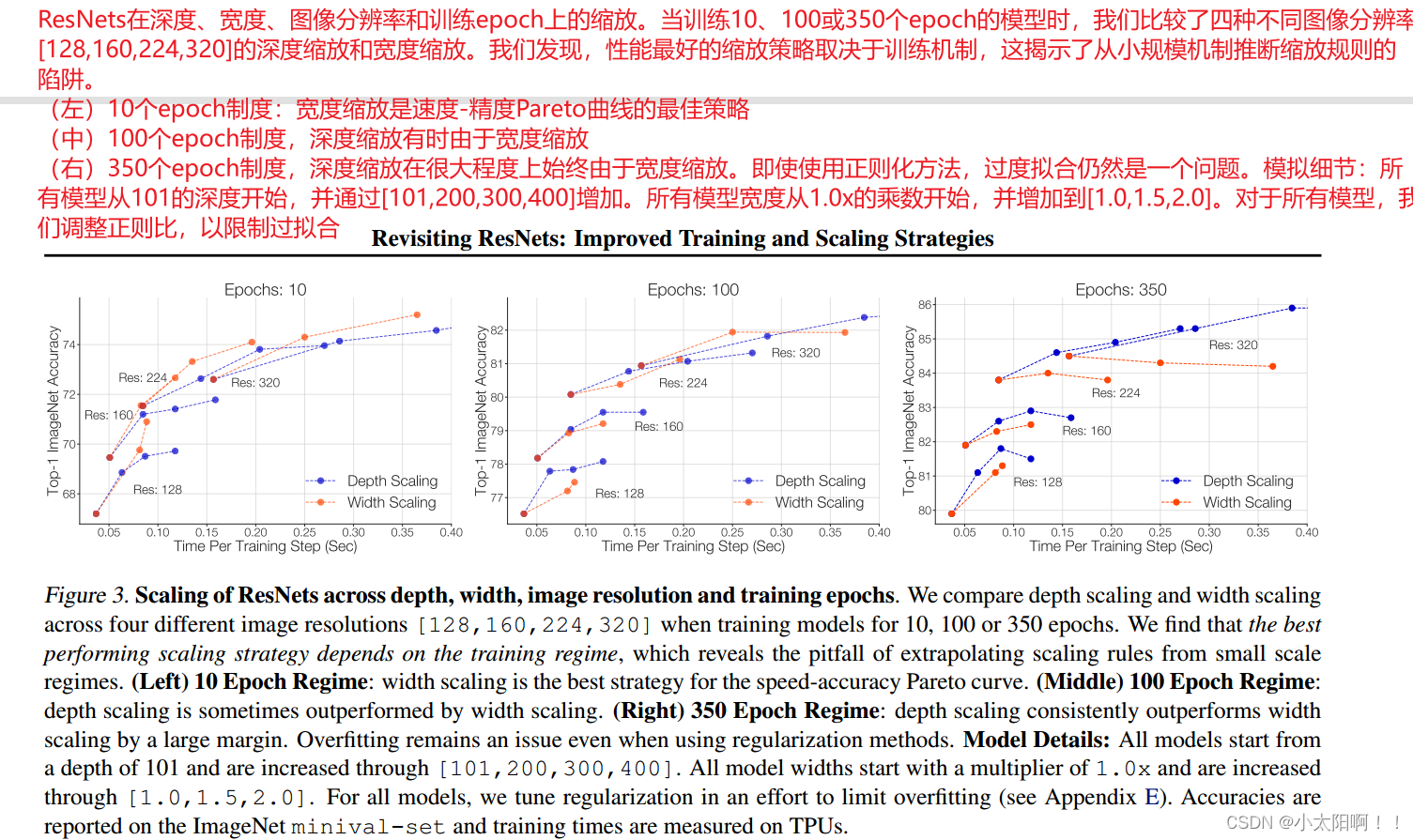
6.1 策略#1-可能发生过度拟合的情况下的深度缩放
对于较长的
epoch
状态,深度缩放优于宽度缩放
。缩放宽度会受到过拟合的影响,有时甚至在增加正则化的情况下也会影响性能。我们假设这是由于在缩放宽度时参数增加较大所致。ResNet
架构在所有块中保持恒定的FLOP
,并将参数的数量乘以每个块的
4
倍。因此,
与缩放宽度相比,缩放深度,尤其是在早
期层中,引入的参数更少。
对于较短的
epoch
状态,宽度缩放优于深度缩放。
相比之下,当只训练
10
个
epoch
时,宽度缩放的效果
更好(图
3
,左图
)。对于
100
个
epoch
(图
3
,中间)根据图像分辨率不同,最佳缩放策略在深度缩放和宽度缩放之间有所不同。缩放策略对训练机制的依赖性揭示了外推缩放规则的陷阱。我们指出,先前的工作在选择在大规模数据集上为少量epoch
训练时缩放宽度(例如,
300M
图像上的
~40
个
eoich)
这与我们实验发现一致,即在较短的epoch
状态下缩放宽度更可取。特别是,
Kolesnikov
等人使用
4
倍滤波器乘法器训练ResNet-152
,而
Brock
等人使用
~1.5
倍滤波器乘法缩放宽度。
6.2策略#2-慢速图像分辨率缩放
在图
2
中,我们还观察到,
较大的图像分辨率会产生递减的回报。因此,我们建议比以前的工作更逐步地
提高图像分辨率
。这与
EfficientNet
提出的复合缩放规则形成对比,该规则导致非常大的图像(例如 EfficientNet-B7为
600
,
EfficientNet-L2
为
800
)。其他工作,如
ResNetSx
和
TResNet
将图像分辨率缩放至448
。我们的实验表明,
较慢的图像缩放不仅提高了
ResNet
架构,而且在速度精度的基础上提高了
EfficientNets
。
6.3 伸缩策略设计中的两个常见陷阱
我们的缩放分析揭示了先前关于缩放策略的研究中的两个常见陷阱:
(
1
)
从小规模制度中推断扩展策略
。在小规模制度中发现的缩放策略(例如,在小模型上或很少的训练epoch)可能无法推广到更大的模型或更长的训练迭代。先前的工作忽略了性能最佳的缩放策略和训练机制之间的相关性,这些工作从小模型或较短的训练epoch
推断缩放规则。因此,我们不建议只在小规模制度中生成缩放规则,因为这些规则可能会崩溃。
(
2
)
从单个且可能次优的初始架构中推断扩展策略
。从次优初始体系结构开始可能会使缩放结果发生偏差。例如,复合缩放规则源自围绕EfficientNet-B0
的小网格搜索,该搜索是通过使用固定
FLOP
预算与特定图像分辨率的架构搜索获得的。然而,由于该图像分辨率对FLOP
预算来说可能是次优的,因此产生的缩放策略可能是次最优的。相比之下,我们的工作通过在各种宽度、深度和图像分辨率上训练模型来设计缩放策略。
总结
首先不建议只在小规模制度中生成缩放规则。
6.4改进的扩展策略概率
对于一项新任务,我们建议在不同的尺度上运行一小部分模型,用于完整的训练
epoch
,以获得在模型尺度上哪些维度最有用的直觉。虽然,这种方法可能看起来成本更高,但我们指出,不搜索架构会抵消成本。
对于图像分类,缩放策略概括为
(
1
)在可能发生过拟合的情况下缩放深度(否则最好缩放宽度)
(
2
)慢速图像分辨率缩放。实验表明,将这些缩放策略应用于
ResNets(ResNetRS
)和
EfficientNets
(
EfficientNet RS
)会显著提高效率。我们注意到,在最近的工作中也采用了类似的缩放策略,这些策略在LambdaResNets
和
NFNets
等高效网络上获得了较大的加速。
总结
缩放策略概括为
1
、在可能发生过拟合的情况下缩放深度(否则最好是缩放宽度)
2
、慢速图像分辨率缩放。
7、改进训练和扩展策略的实验
7.1 基于速度精度的ResNet-RS
使用改进的训练和缩放策略,我们设计了
ResNet-RS
,
这是一个在广泛的模型尺度上重新缩放的
ResNet家族(有关实验和架构的详细信息,请参见附录B
和
D
)。图
4
在速度精度
Pareto
曲线上比较了EfficientNets与
ResNet RS
。我们发现
ResNet RS
与
EfficientNet
的性能相匹配,而在
TPU
上的速度是前者的1.7
倍
-2.7
倍。这种对
EfficientNet
的大幅加速可能不是直观的,因为与
ResNets
相比,
EfficientNets
显著地减少了参数技术和
FLOP
。接下来,我们将讨论为什么一个参数较少、
FLOP
较少的模型(EfficientNet
)在训练过程中速度较慢、内存更密集。
FLOP
与
Latency
。虽然
FLOP
为评估计算需求提供了一种硬件诊断指标,但它们可能不能指示训和推 理的实际延迟时间Howard
等人,
2017
;
2019
;
Radosavovic
等人,
2020
)。在定制硬件架构(例如,TPU和
GPU
)中,
FLOP
是一个特别糟糕的代理,因为操作通常受存储器访问成本的限制,并且在现代矩阵乘法单元上具有不同级别的优化。EfficientNets
中使用的反向
bottlenecks
使用了具有大激活的深度卷积,并且与较小激活上使用密集卷积的ResNet
瓶颈块相比,具有较小的计算与内存比。这使得EfficientNets在现代加速器上的效率低于
ResNets
。表
3
说明了这一点:与
EfficientNet-B6
相比,
FLOP多1.8
倍的
ResNet RS
模型在
TPU3
硬件加速器上的速度快
2.7
倍。
参数和内存
:参数计数不一定决定训练期间的内存消耗,因为内存通常由
activation
的尺寸定义。
EfficientNets
中使用的大激活也会导致很大的内存消耗,与我们重新缩放的
ResNet
相比,使用大图像分辨率会加剧内存消耗。对于类似的ImageNet
精度,参数比
EfficienNet-B6
多
3.8
倍的
ResNet RS
模型消耗的内存少2.3
倍(表
3
)。我们强调,由于编辑器优化,如操作布局分配和内存填充,内存消耗与延迟都与软件和硬件堆栈(TPU3
)上的
TensorFlow)
紧密耦合。
7.2提高高效网络的效率
第
6
节的缩放分析表明,缩放图像分辨率会导致收益递减。这表明,
EfficientNets
中提倡的与模型规模无关的增加模型深度、宽度和分辨率的缩放规则是次优的。我们将慢速图像分辨率缩放策略(策略#2
)应用于EffIcientNets
,并在不改变宽度或深度的情况下训练几个图像分辨率降低的成本。
RandAugment
幅度对于图像分辨率224
或更小设置为
10
,对于图像分辨率大于
320
设置为
20
,否则设置为
15
。所有其他超参数保持与原始EfficientNets
相同,图
5
显示了与原始
EfficientNets
相比,重新缩放的EfficientNet(
EfficientNet RS)
在速度
-
精度
Pareto
曲线上的显著改进。
8、讨论
为什么区分训练方法与架构的改进很重要
?训练方法可以比体系结构更具体地针对任务(例如,数据扩充在小型数据集上更有帮助)因此,来自训练方法的改进不一定像架构改进那样概括。将新提出的体系结构与训练改进打包在一起会使体系结构之间的准确比较变得困难。来自训练策略的巨大改进,如果不加以控制,可能会掩盖架构差异。
应该如何比较不同的体系结构
?
由于训练方法和规模通常会提高性能,因此在比较不同架构时,控制这两个方面至关重要。规模控制可以通过不同的指标来实现。虽然许多工作报告了参数和FLOP
,但我们认为延迟和内存消耗通常更相关。我们的实验结果再次强调,FLOP
和参数不能代表延迟或内存消耗。
改进后的训练策略是否跨任务转移
?答案取决于可用的域或数据集大小。这里研究的许多训练和正则化方法没有用于大规模预训练。数据扩充对于小数据集或训练许多epoch
时是有效的,但扩充方法的细节可能取决于任务(例如,表6
中的尺度抖动而不是
RandAugment
)。
扩展策略是否跨任务转移?
如第
6
节所述,性能最佳的缩放策略取决于训练制度以及过拟合是否是一个问题。当在
ImageNet
上训练350个
epoch
时,我们发现缩放深度可以很好地工作,而当训练几个
epoch
(例如
10
个时)缩放宽度更可 取。这与在大规模数据集上训练几个epoch
时期时采用宽度缩放的工作一致,我们不定我们的缩放策 略如何应用于需要更大图像分辨率的任务(例如检测和分割),并将其留给未来的工作。
架构更改有用吗
?
是的,但是训练方法和扩展策略可能会产生更大的影响。简单性往往获胜,特别是考虑到定制硬件上出 现的不寻常的性能问题。降低速度和增加复杂性的架构变化可能会被在可用硬件上优化的更快、更简单 的架构所超越。我们设想,未来成功的架构将通过与硬件的共同设计而出现,特别是在资源紧张的情况 下,如手机。
应该如何分配计算预算来生成最佳视觉模型
?
我们建议从一个可用硬件上高效的简单架构开始(例如
GPU
、
TPU
上的
ResNets
),并训练几个模型,以收敛,使用不同的图像分辨率。宽度和深度来构建Pareto
曲线,请注意,该策略不同于
Tan&Le
,后者将计算预算的很大一部分用于确定最佳初始架构以进行扩展。然后,它们进行小网格搜索,以找到在所 有模型尺度上使用的复合缩放系数。RegNet
在只训练了
10
个
epoch
的情况下进行了大部分研究。















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









