







前言:
最先使用这个功能的初衷是因为利用Python的OCR库-tesseract,把图片转换后得到的数据不好处理,故为了减少不好处理部分的数据,减少转化图片的范围,所以先通过截图,再进行OCR。
正文:
1.程序部分:
import pytesseract
from PIL import Image
img = Image.open(r"1.7.bmp")
print(img.size)#图片尺寸
img_size = img.size
h = img_size[1] # 图片高度
w = img_size[0] # 图片宽度
x = 0.35 * w
y = 0.87 * h
w = 0.14 * w
h = 0.07 * h
cropped = img.crop((x, y, x+w, y+h)) # (x1, y1, x2, y2)
cropped.save(r"C:\Users\SSYP\Desktop\cut_img.png")
#
images=Image.open('C:\\Users\SSYP\Desktop\cut_img.png')#①
# images=Image.open('1.2.JPG')
print(images.size)
text=pytesseract.image_to_string(images)
print(text)
图片暂时不能贴出来,这是人家的项目,等他们做完寻求一下人家的意见,抱歉。
但是可以举例子说明
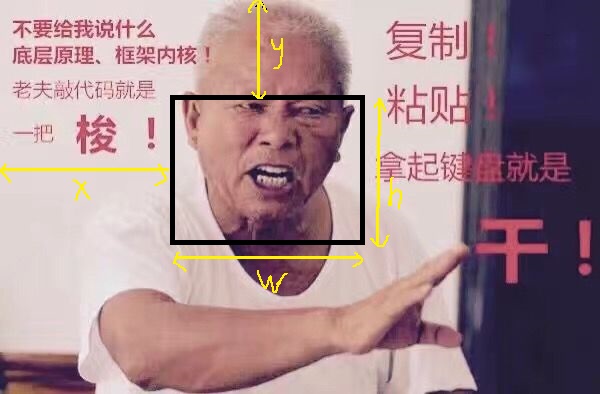
# 导入相关的库
from PIL import Image
# 打开一张图
img = Image.open('test.jpg')
# 图片尺寸
img_size = img.size
h = img_size[1] # 图片高度
w = img_size[0] # 图片宽度
x = 0.25 * w
y = 0.16 * h
w = 0.5 * w
h = 0.2 * h
# 开始截取
region = img.crop((x, y, x + w, y + h))
# 保存图片
region.save("test.jpg")
2.结果:















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









