










今天,我们将学习如何部署由阿里巴巴最新Qwen 3驱动的Agentic RAG。
这里是我们的工具栈:
-
CrewAI用于代理编排。
-
Firecrawl用于网络搜索。
-
LightningAI的LitServe用于部署。
顶部的视频展示了这一过程。
图表显示了我们的Agentic RAG流程:
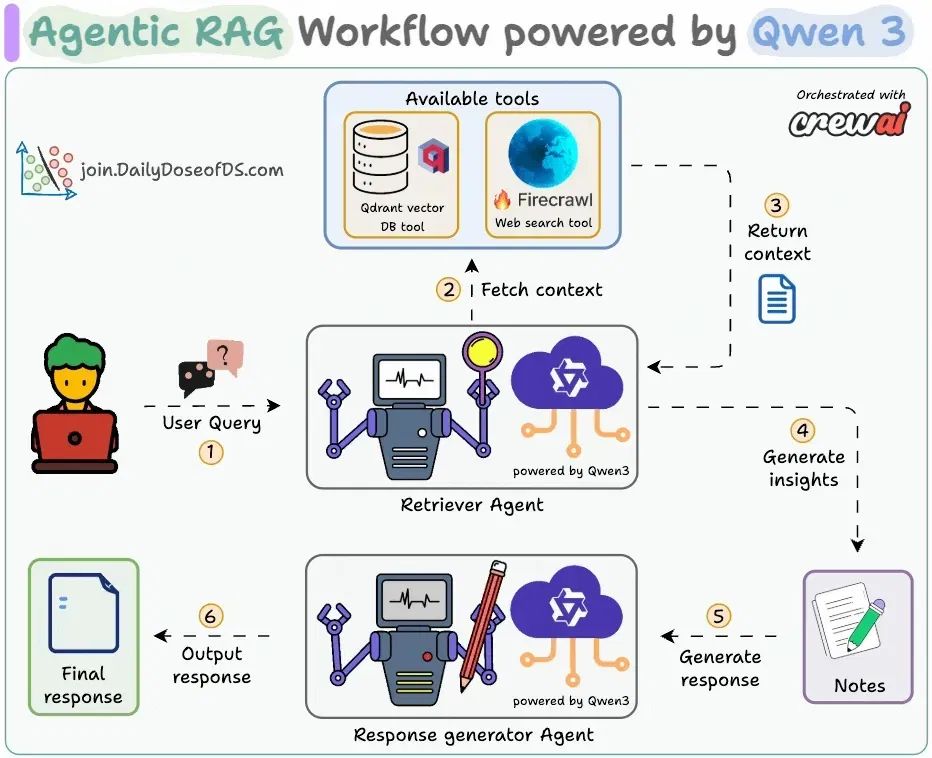
-
检索代理接受用户查询。
-
它调用相关工具(Firecrawl网络搜索或向量DB工具)以获取上下文并生成见解。
-
写作代理生成响应。
接下来,让我们实现并部署它!
代码稍后在问题中链接。
这里是为我们的Agentic RAG服务的完整代码。
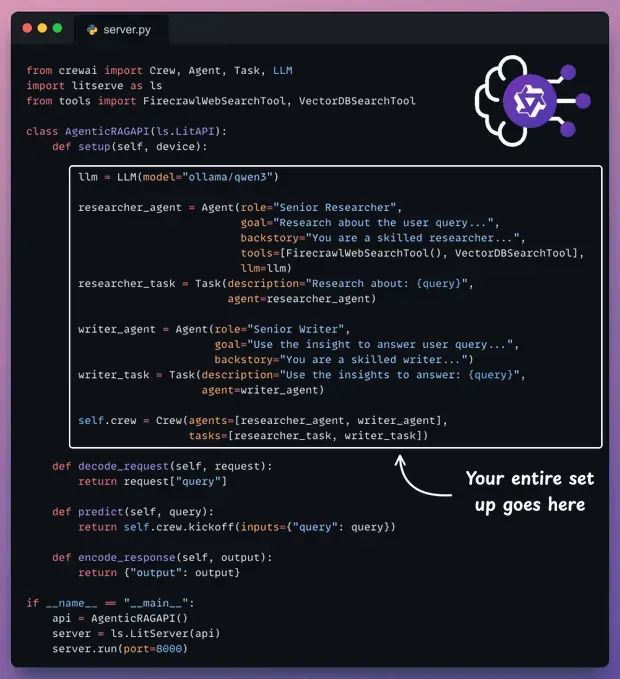
-
setup方法编排代理。 -
decode_request方法准备输入。 -
predict方法调用Crew。 -
encode_response方法发送响应回来。
让我们下面一步一步理解它
Set up LLM
CrewAI与所有流行的LLMs和提供商无缝集成。
这里是通过Ollama设置本地Qwen 3的方式。
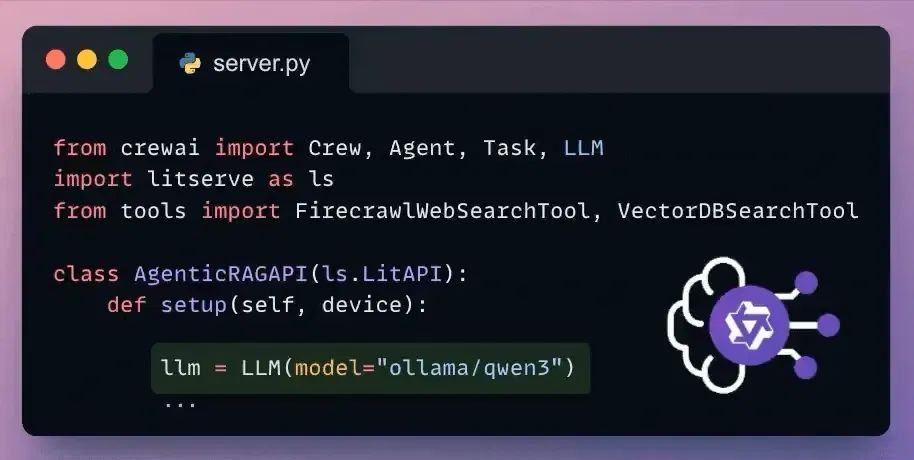
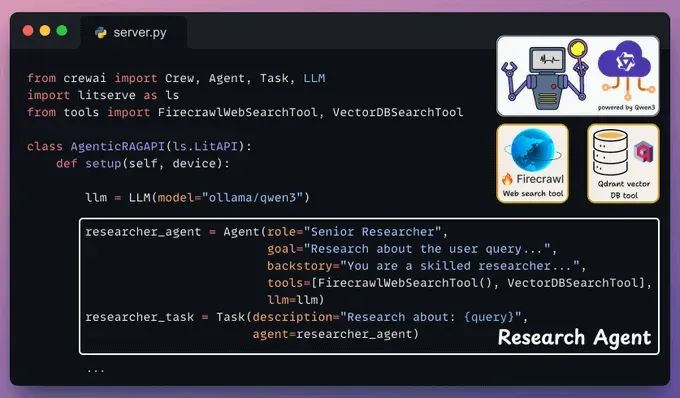
Define Research Agent and Task
这个代理接受用户查询,并使用向量DB工具和由Firecrawl驱动的网络搜索工具检索相关上下文。
再次,在LitServe的setup()方法中放入这个:
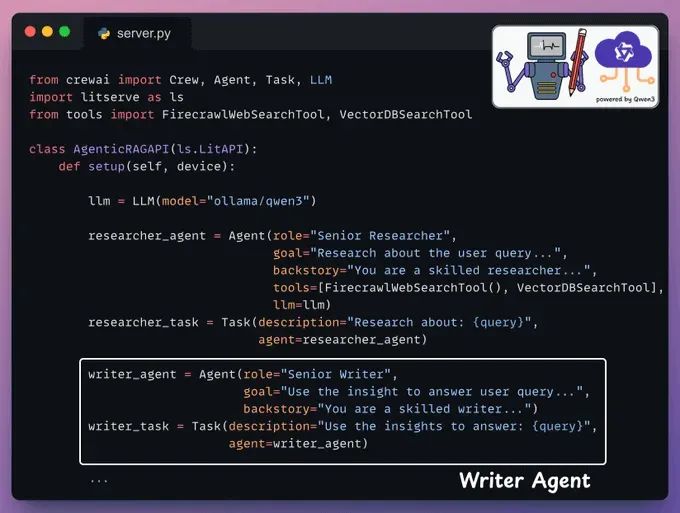
Define Writer Agent and Task
接下来,写作代理接受研究者代理的见解以生成响应。
我们再次在LitServe的setup方法中添加这个:
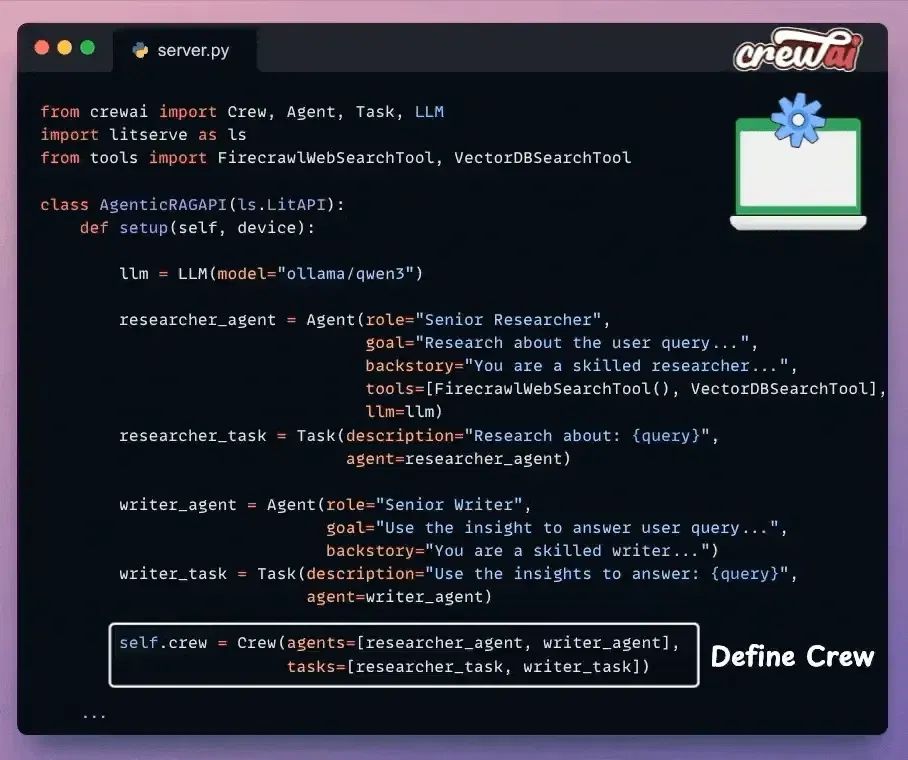
Set up the Crew
一旦我们定义了代理及其任务,我们使用CrewAI将它们编排成一个团队,并将其放入一个设置方法中。
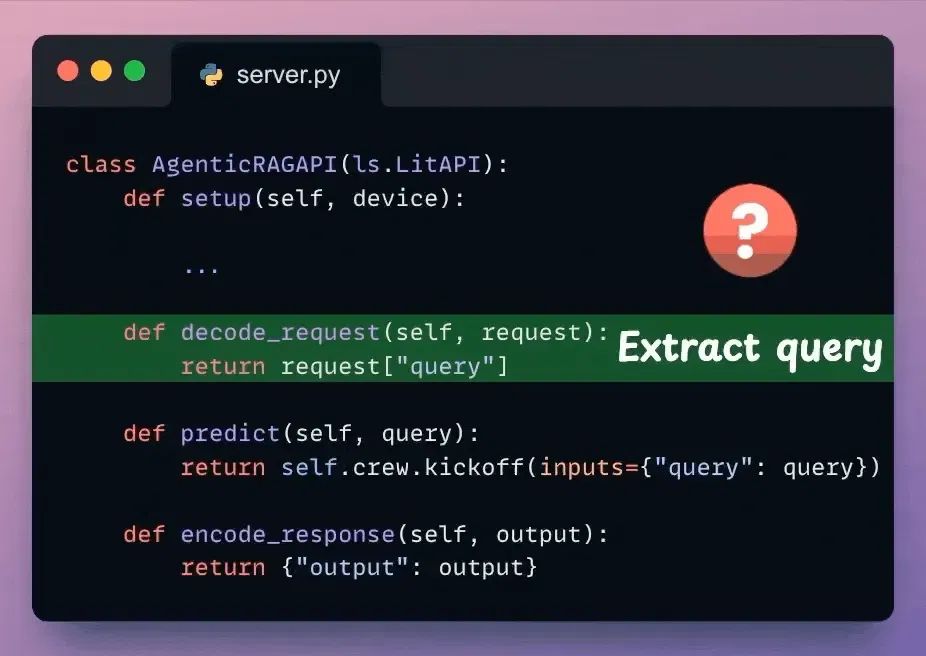
Decode request
我们已经编排了Agentic RAG工作流程,该工作流程将在收到请求时执行。
接下来,从收到的请求体中提取用户查询。
检查下面突出显示的代码:
Predict
我们使用解码的用户查询,并将其传递给之前定义的Crew,以从模型生成响应。
检查下面突出显示的代码:
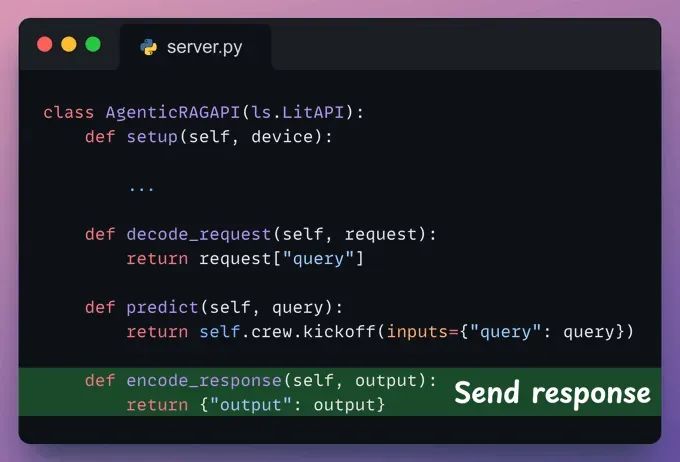
Encode response
这里,我们可以对响应进行后处理并将其发送回客户端。
注意:LitServe内部按顺序调用这些方法:decode_request → predict → encode_request。
检查下面突出显示的代码:
我们完成了服务器代码。
接下来,我们有基本的客户端代码来调用我们使用requests Python库创建的API:
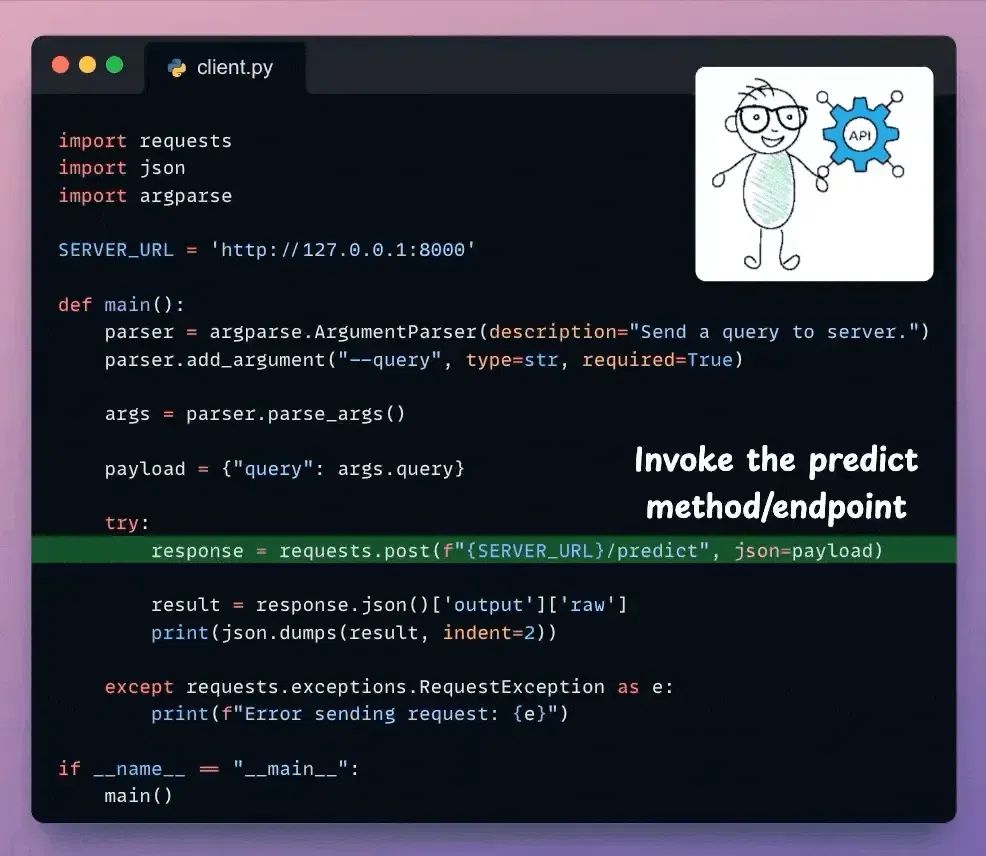
完成!
我们已经使用LitServe部署了完全私有的Qwen 3 Agentic RAG。这里是部署的Qwen3 Agentic RAG的回顾。
原文地址:https://blog.dailydoseofds.com/p/deploy-a-qwen-3-agentic-rag






















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









