







DA-TRANSUNET: INTEGRATING SPATIAL AND CHANNEL DUAL ATTENTION WITH TRANSFORMER U-NET FOR MEDICAL IMAGE SEGMENTATION
论文
代码
不足:传统的UNET和Transformer缺乏利用图像的内在位置和通道特征的能力。同时在参数效率和计算复杂性方面也存在困难。
解决:提出新的分割框架DA-TransUNet(旨在将Transformer和双重注意块(DA-Block)集成到传统的u型架构中),它包含了专门用于提取图像特定位置和通道特征的da块
优点:DA-TransUNet利用Transformers和DA-Block不仅集成了全局和局部的特征,而且还集成了特定于图像的位置和信道特征,提高了医学图像分割的性能。通过在嵌入层和每个跳跃连接层中加入da块,极大地增强了特征提取能力,提高了编解码结构的效率。
本文的贡献:
(1)我们提出了DA-TransUNet,这是一种新颖的架构,它集成了双重注意机制,将位置信息和通道信息处理到一个Transformer U-net框架中。该设计提高了编解码器结构的灵活性和功能性,从而提高了医学图像分割任务的性能。
(2)提出了一种设计良好的双注意编码机制,将其置于编码器的Transformer层之前。这样可以增强其特征提取能力,丰富编码器在U-net结构中的功能。
(3)我们通过在每一层中加入双注意块来提高跳跃连接的有效性,消融研究证实了这一改进,从而使特征更准确地传递到解码器,并提高了图像分割性能。
(4)我们提出的DA-TransUNet方法在多个医学影像数据集上取得了最先进的性能,证明了该方法的有效性和对医学影像分割的贡献。
跳跃连接可以消除编码器解码器之间的语义鸿沟,有效恢复细粒度的目标细节。
1、方法
1.1 模型
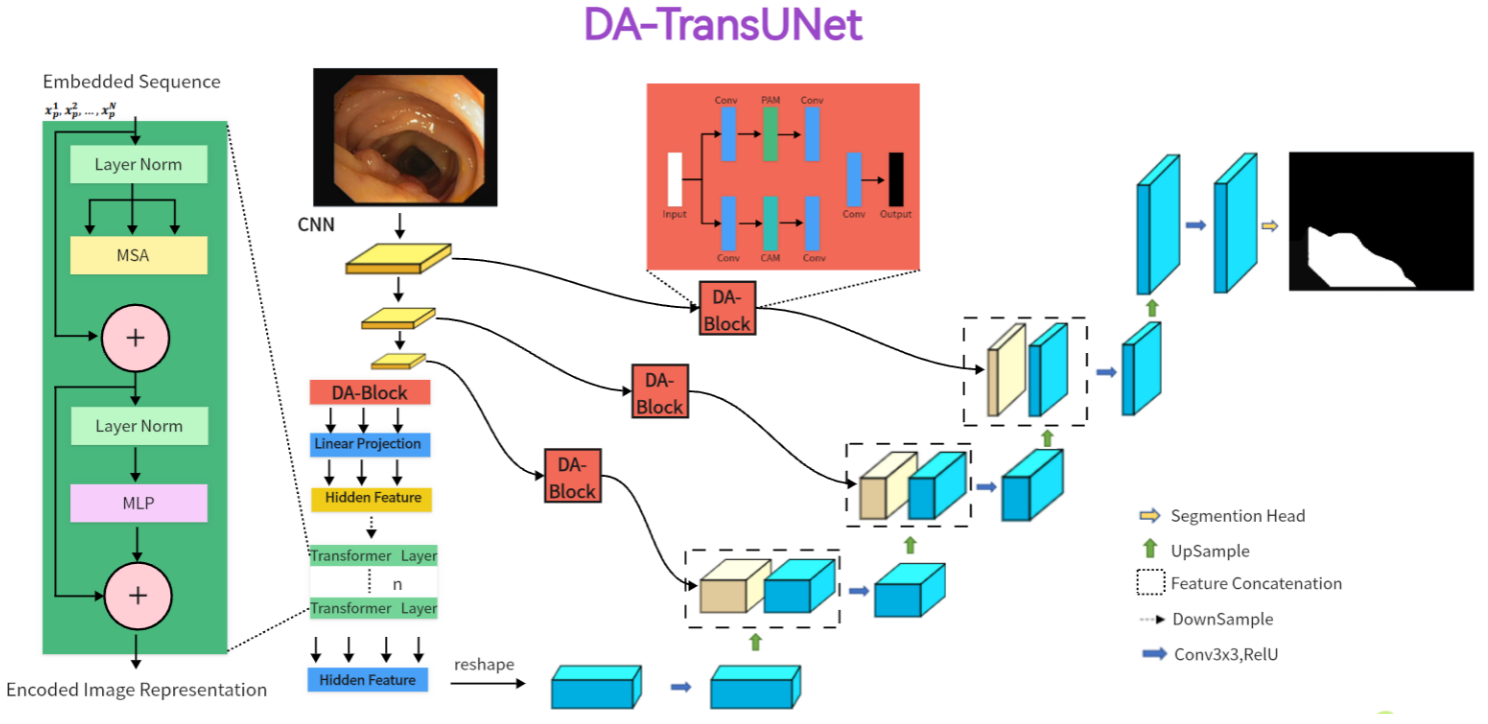
图1 对于输入的医学图像,我们将它们输入一个带有变压器和双注意块(DA-Block)的编码器。然后,用DA-Block对三个不同尺度的特征进行细化。最后,将细化后的跳跃连接与解码器融合,解码器随后进行基于cnn的上采样,将通道恢复到与输入图像相同的分辨率。这样就得到了最终的图像预测结果。
图1给出了DA-TransUNet的体系结构。该模型包括三个核心组件:编码器、解码器和跳过连接。特别是,编码器融合了传统的卷积神经网络(CNN)和Transformer层,并进一步丰富了da块,这是该模型架构中独有的。相比之下,解码器主要采用传统的卷积机制。为了优化跳过连接,da块是DA-TransUNet架构中的关键组件。da块过滤了跳过连接中的不相关信息,提高了图像重建的精度。综上所述,与传统的卷积方法和Transformers的广泛使用相比,DA-TransUNet独特地利用了da - block来提取和利用位置和信道的特定于图像的特征。这种战略合并显著地提高了模型的整体性能。
虽然Transformers擅长通过自我关注机制进行全局特征提取,但它们本质上局限于对位置属性的单向关注,从而忽略了多面特征视角。另一方面,传统的U-Net架构擅长于局部特征提取,但缺乏全面的全局上下关注能力。为了解决这些约束,我们在Transformer层之前和在编码器解码器跳过连接内部集成了da块。为了解决这些约束,我们在Transformer层之前和在编码器解码器跳过连接内部集成了da块。这实现了两个目标:首先,它细化了Transformer的特征映射输入,使全局特征提取更加细致和精确;其次,跳跃连接中的da块优化编码器发送的特征,便于解码器重构更精确的特征图。
1.2 双注意力模块(DA-Block)
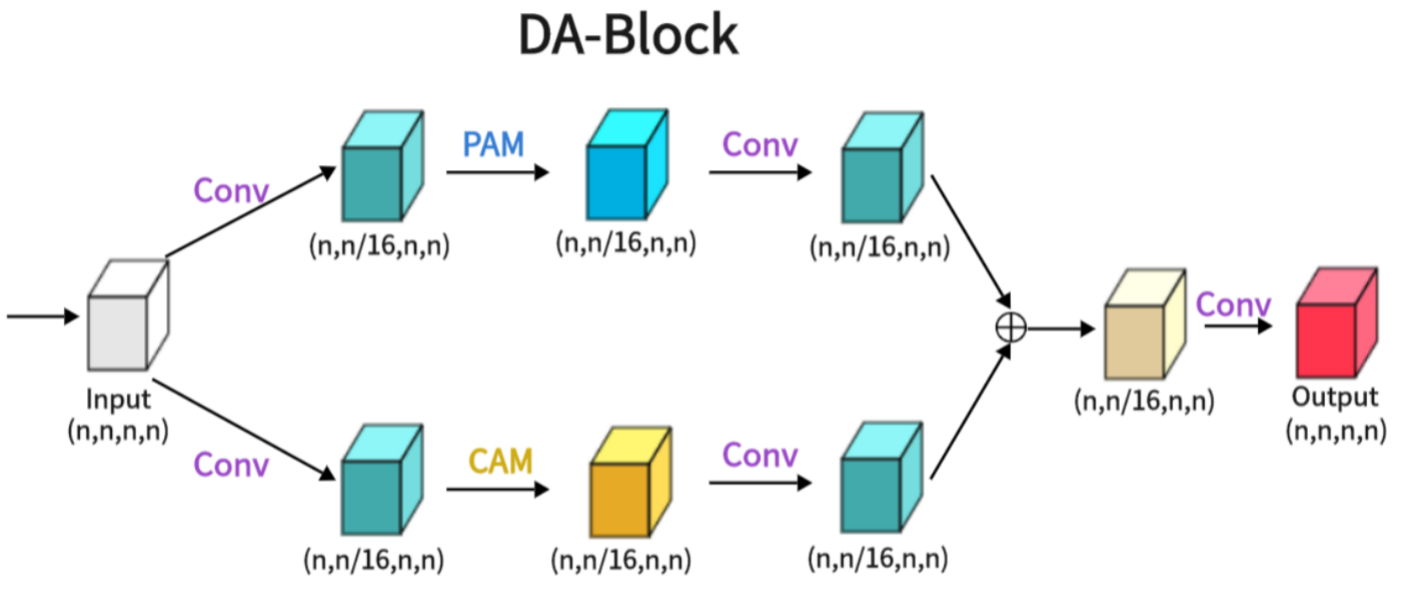
图2 相同的输入特征图被输入到两个特征提取层,一个是位置特征提取块,另一个是通道特征提取块,最后,两个不同的特征被融合,得到最终的 DA-Block 输出
如附图 2 所示,双注意力模块(DA-Block)作为一个特征提取模块,集成了位置和通道的特定图像特征。这样就能根据图像的独特属性进行特征提取。特别是在 U-Net 形架构中,DA-Block 的专业特征提取能力至关重要。虽然Transformer善于利用注意力机制提取全局特征,但它们并不是专门针对特定图像属性而设计的。相比之下,DA-Block 在基于位置和基于通道的特征提取方面表现出色,能够获得更详细、更准确的特征集。因此,我们将其纳入编码器和跳过连接,以提高模型的分割性能。DA-Block 由两个主要部分组成:一个是位置注意模块(PAM),另一个是通道注意模块(CAM),两者都借鉴了用于场景分割的双注意网络[9]。
1.2.1 PAM( 位置注意力模块)
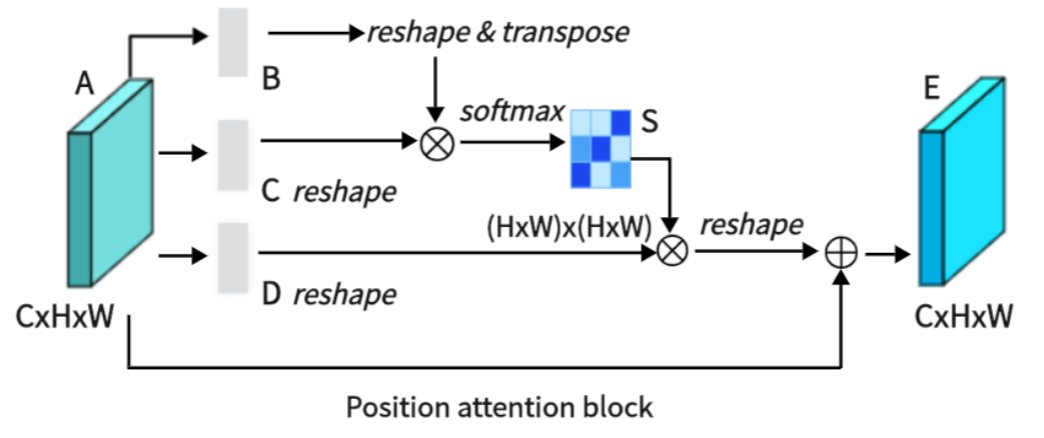
图3 PAM
如图 3 所示,PAM 可捕捉特征图中任意两个位置之间的空间依赖关系,通过所有位置特征的加权和来更新特定特征。权重由两个位置之间的特征相似性决定。因此,PAM 能有效提取有意义的空间特征。
PAM 最初获取一个局部特征,表示为 A∈ RC×H×W(C 代表通道,H 代表高度,W 代表宽度)。然后,我们将 A 输入卷积层,得到三个新的特征图,即 B、C 和 D,每个特征图的大小均为 RC×H×W。接下来,我们将 B 和 C 重塑为 RC×N,其中 N = H×W 表示像素数。我们在 C 和 B 的转置之间执行矩阵乘法,然后使用softmax计算空间注意力图 S∈RN×N。
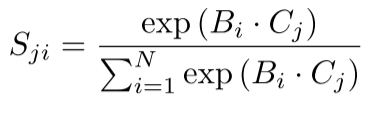
这里,Sji 表示第 i 个位置对第 j 个位置的影响。然后,我们将矩阵 D 重塑为 RC×N。在 D 和 S 的转置之间执行矩阵乘法,然后将结果重塑为 RC×H×W。最后,我们将其与参数 α 相乘,并与特征 A 进行元素求和运算,得到最终输出 E∈RC×H×W:
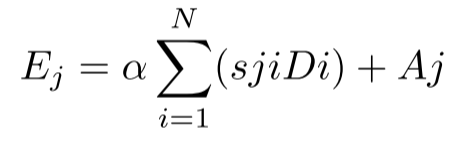
权值α初始化为0,逐步学习。PAM具有很强的空间特征提取能力。由于E是所有位置特征和原始特征的加权和,所以它具有全局上下文特征,并基于空间注意图聚合上下文。这确保了有效地提取位置特征,同时保持全局上下文信息。
1.2.2 CAM(通道注意力 )
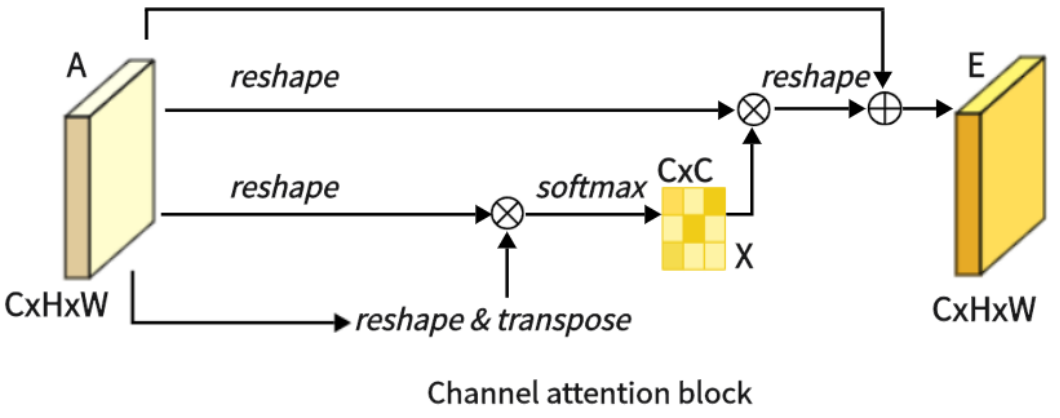
图4
如图4所示,这是CAM,它擅长提取通道特征。与PAM不同,我们直接将原始特征A∈RC×H×W重塑为RC×N,然后在A和它的转置之间进行矩阵乘法。随后,我们应用softmax层,获得通道注意图X∈RC×C:

在这里,xji测量了第i个通道对第j个通道的影响。接下来,我们在X的转置和a之间执行矩阵乘法,将结果重塑为RC×H×W。然后我们将结果乘以尺度参数β,并对a进行逐元素求和运算,得到最终输出E∈RC×H×W:
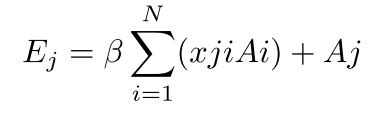
和α一样,β是通过训练来学习的。与PAM类似,在CAM中提取通道特征时,每个通道的最终特征是所有通道与原始特征的加权和,从而使CAM具有强大的通道特征提取能力。
1.2.3 DA (Dual Attention Module)
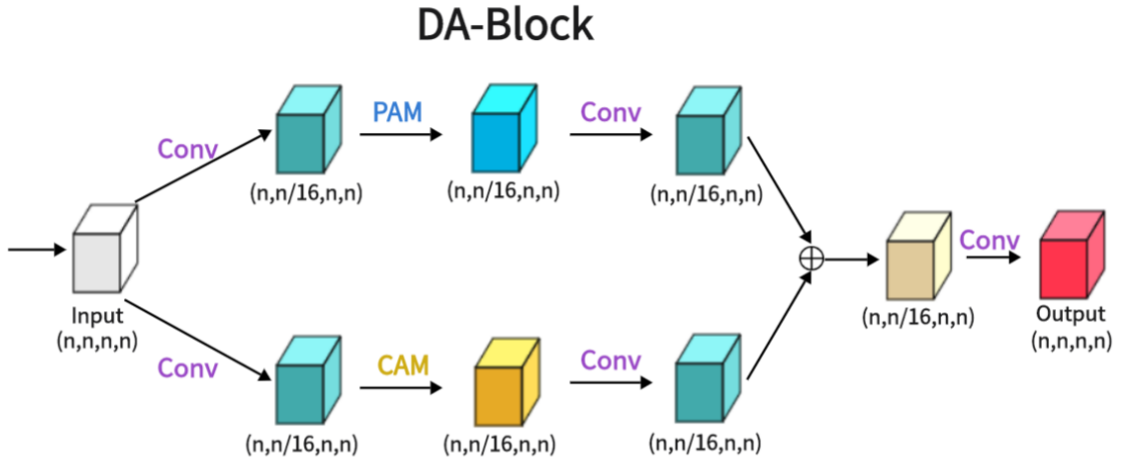
如图所示,我们展示了双注意力块(DA-Block)的架构。该体系结构融合了位置注意模块(PAM)的鲁棒位置特征提取能力和通道注意模块(CAM)的通道特征提取能力。此外,当与传统卷积方法的细微差别相结合时,DA-Block具有优越的特征提取能力。DA-Block由两部分组成,第一部分以PAM为主,第二部分以CAM为主。第一个组件采用输入特征并进行一次卷积,将通道数量缩放到1 / 16以得到α1。这简化了PAM的特征提取;通过PAM特征提取和卷积,得到αˆ1。

其他组件是相同的,唯一的区别是PAM块被替换为CAM,用下面的公式:

从两层注意中提取αˆ1和αˆ2后,通过对两层注意进行聚合和求和,在一个卷积中恢复通道数,得到输出。
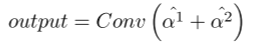
这种复杂的DA-Block架构无缝地集成了PAM和CAM的优势,以改进特征提取,使其成为增强模型整体性能的关键组件。
1.3 带Transformer和双注意的编码器
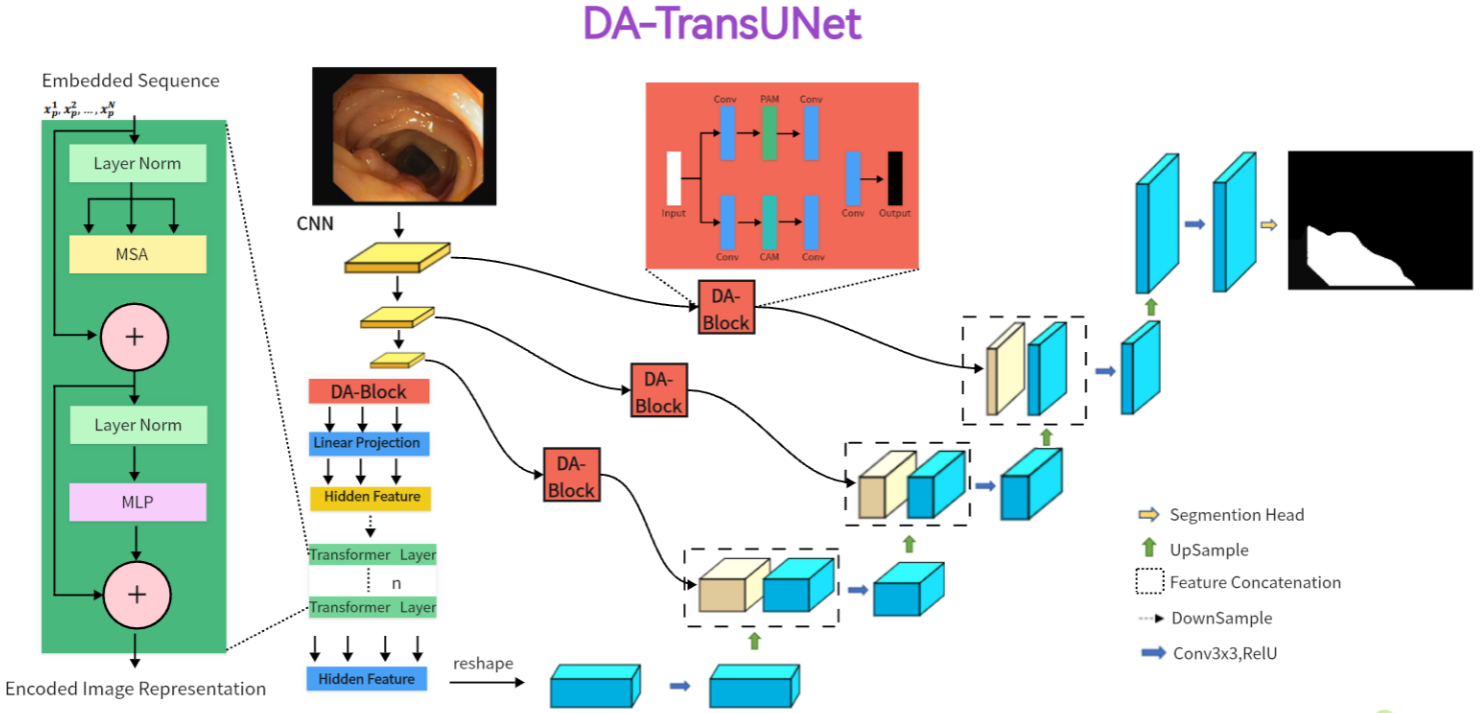
如图1所示,编码器架构由四个关键组件组成:卷积块、da块、嵌入层和变压器层。特别重要的是将DA块包含在Transformer层之前。本设计旨在对卷积后的特征进行专门的图像处理,增强Transformer对图像内容的特征提取。Transformer架构在保存全局上下文方面起着关键作用,而DA块增强了Transformer捕捉特定于图像的特征的能力,增强了它在图像中捕捉全局上下文信息的能力。该方法有效地将全局特征与特定于图像的空间和信道特征结合起来。
第一个组件包括U-Net体系结构的三个卷积块及其不同的迭代,将卷积操作与下采样过程无缝集成。每个卷积层都将输入特征图的大小减半,并将其维数加倍,这是经验发现的一种配置,可在保持计算效率的同时最大化特征表达。第二部分使用DA-Block在位置和通道两级提取特征,增强了特征表示的深度,同时保留了输入地图的内在特征。第三个组成部分是作为关键中间层的埋入层,使必要的尺寸适应成为可能,这是随后的Transformer层的前奏。第四个组件集成了Transformer层,用于增强全局特征提取,超越了传统CNNs的能力。将上述部分放在一起,它的工作原理如下:输入图像遍历三个连续的卷积块,系统地扩展接收域以包含重要特征。随后,da块通过应用基于位置和基于渠道的注意机制来细化特征。在此之后,重塑的特征在被引导到Transformer框架中以提取所有包含的全局特征之前,要经过嵌入层的维数转换。这种协调的进展保障了信息的全面保留跨越连续的卷积层。最后,重构Transformer生成的地形图,并引导地形图穿过中间地层到达解码器。
通过将卷积神经网络、变压器架构和双重关注机制结合起来,编码器配置最终实现了强大的特征提取能力,从而形成了一种共生的强大功能。
1.4具有双重注意的跳过连接
与其他 U 型结构模型类似,我们也在编码器和解码器之间加入了跳转连接,以弥合它们之间存在的语义差距。为了进一步缩小语义差距,我们在三个跳转连接层中的每一层都引入了双注意块(DA-Blocks),如图 1 所示。这一决定基于我们的观察,即传统的跳转连接通常会传输冗余特征,而 DA-Blocks 能有效过滤这些特征。将 DA-Blocks 集成到跳频连接中,可以从位置和信道两个角度完善稀疏编码特征,在减少冗余的同时提取更多有价值的信息。这样,DA-Blocks 就能帮助解码器更准确地重建特征图。此外,DA-Blocks 的加入不仅增强了模型的鲁棒性,还有效降低了对过拟合的敏感性,有助于提高模型的整体性能和泛化能力。
1.5 解码器
如图1所示,图的右半部分对应于解码器。解码器的主要作用是利用编码器获取的特征和跳过连接接收到的特征,采用上采样等操作,重建原始的特征图。
该解码器的组成部分包括特征融合、分割头和三个上采样卷积块。第一个组件:feature fusion是将通过skip连接传输的feature特征图与已有的feature特征图进行整合,从而帮助解码器忠实地重构原始feature map。第二部分:分割头部负责将最终输出的特征图恢复到原始尺寸。第三部分:三个上采样卷积块在每一步中递增地将输入特征图的大小增加一倍,有效地恢复了图像的分辨率。
将上述部分放在一起,工作流首先通过卷积块传递输入图像,然后执行上采样以增加特征特征图的大小。这些特征特征图的尺寸增加了两倍,而尺寸减少了一半。通过跳跃连接接收到的特征然后被融合,接着继续上采样和卷积。经过三次迭代后,生成的feature map进行最后一轮上采样,通过分割头将其精确还原到原始大小。由于这种结构,解码器展示了强大的解码能力,使用编码器和跳过连接的特性有效地恢复了原始的特征图。
2、实验
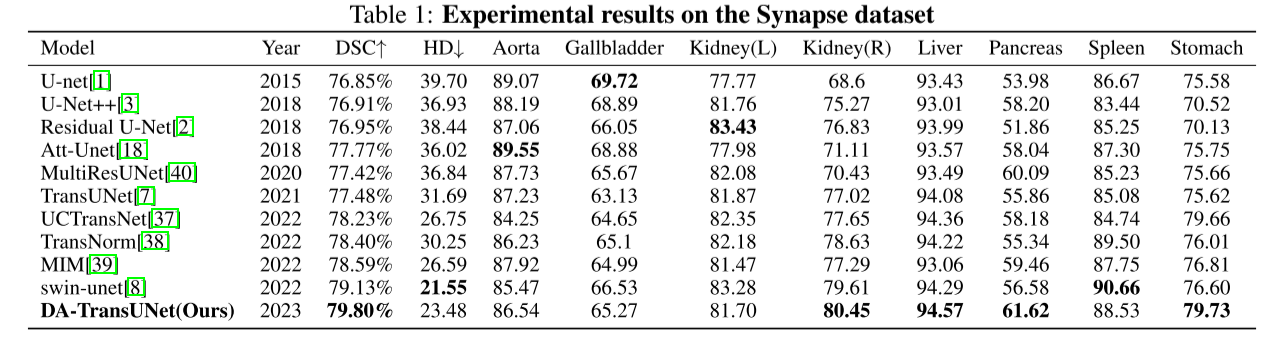
3、总结
在本文中,我们创新性地提出了一种新的图像分割方法,该方法是在TransUNet的体系结构中将da块与Transformer集成在一起。针对特定图像位置和通道特征的da块被进一步集成到跳跃连接中,以提高模型的性能。我们的实验结果,经过广泛的消融研究的验证,表明模型的性能在不同的数据集,特别是Synapse数据集的显著改善。
我们的研究揭示了da块在增强Transformer的特征提取能力和全局信息保持方面的潜力。数据块和Transformer的集成在不产生冗余的情况下,大大提高了模型的性能。此外,在skip连接中引入da块不仅有效地弥合了编码器和解码器之间的语义鸿沟,而且细化了特征特征图,提高了图像分割性能。


















 6714
6714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











