







 本文详细介绍了目标检测的发展历程,从传统的HOG、SIFT特征提取到深度学习方法,如R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN、Cascade R-CNN)、YOLO系列(YOLOv1、YOLOv2、YOLOv3、YOLOv5)以及其他的检测框架如SSD、RetinaNet、Focal Loss等。文章探讨了这些方法的原理、优缺点,并对比了它们在性能和效率上的差异。
本文详细介绍了目标检测的发展历程,从传统的HOG、SIFT特征提取到深度学习方法,如R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN、Cascade R-CNN)、YOLO系列(YOLOv1、YOLOv2、YOLOv3、YOLOv5)以及其他的检测框架如SSD、RetinaNet、Focal Loss等。文章探讨了这些方法的原理、优缺点,并对比了它们在性能和效率上的差异。
文章目录
- 一、BACKGROUND
- 二、传统目标检测方法(后面更新)
- 三、深度学习方法
-
-
- R-CNN
- SPP-NET(金字塔池化)
- Fast RCNN
- RPN(region proposal network)
- Faster RCNN
- Cascade RCNN
- Mask RCNN
- HTC(Hybrid Task Cascade)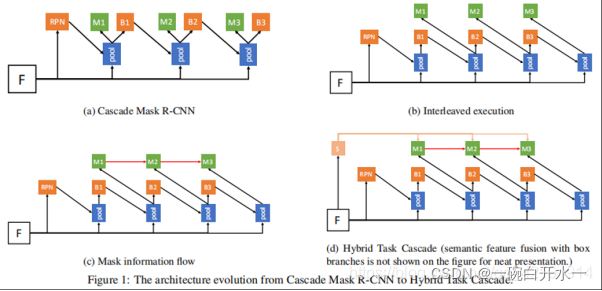
- SSD
- YOLO(V1,V2,V3)
- YOLOv3-tiny & YOLOv3-tiny-mobilenet
- yolov5
- PP-YOLO
- YOLO-X
- RetinaNet(Focal Loss for Dense Object Detection)
- RefineDet(Single-Shot Refinement Neural Network for Object Detection)
- FCOS
- ATSS
- FSAF(Feature Selective Anchor-Free Module for Single-Shot Object Detection)
- M2Det(A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network)
- EfficientDet: Scalable and Efficient Object Detection
- others
- LRF
- DetectoRS
- VIT 系列
-
注:以下主要介绍了各种目标检测的方法概要, 而非详细解说,若要查看详细解读,可点击各方法中的 链接进行查阅。
一、BACKGROUND
在过去的十多年时间里,传统的机器视觉领域,通常采用特征描述子来应对目标识别任务,这些特征描述子最常见的就是 SIFT 和 HOG.而 OpenCV 有现成的 API 可供大家实现相关的操作
计算机视觉五大技术:图像分类、对象检测、目标跟踪、语义分割和实例分割
目前学术和工业界出现的目标检测算法分成3类:
1、传统的目标检测算法:Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化;
2、双阶段方法:候选区域/框 + 深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案, 如:R-CNN(Selective Search + CNN + SVM)SPP-net(ROI Pooling)Fast R-CNN(Selective Search + CNN + ROI)Faster R-CNN(RPN + CNN + ROI)R-FCN等系列方法;
3、单阶段方法: 基于深度学习的回归方法:YOLO/SSD/DenseBox 等方法, 及anchor based 和anchor free的方法。
二、传统目标检测方法(后面更新)
HOG(方向梯度直方图Histogram of Oriented Gradient)
HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,是与SIFT、SURF、ORB属于同一类型的描述符。HOG不是基于颜色值而是基于梯度来计算直方图的,它通过计算和统计图像局部区域的梯度方向直方图来构建特征。HOG特征结合SVM分类器已经被广泛应用到图像识别中,尤其在行人检测中获得了极大的成功。
此方法的基本观点是:局部目标的外表和形状可以被局部梯度或边缘方向的分布很好的描述,即使我们不知道对应的梯度和边缘的位置。(本质:梯度的统计信息,梯度主要存在于边缘的地方)

SIFT 特征提取
- sift = cv2.xfeatures2d.SIFT_create() 实例化
参数说明:sift为实例化的sift函数
- kp = sift.detect(gray, None) 找出图像中的关键点
参数说明: kp表示生成的关键点,gray表示输入的灰度图,
- ret = cv2.drawKeypoints(gray, kp, img) 在图中画出关键点
参数说明:gray表示输入图片, kp表示关键点,img表示输出的图片
- kp, dst = sift.compute(kp) 计算关键点对应的sift特征向量
参数说明:kp表示输入的关键点,dst表示输出的sift特征向量,通常是128维的
BOW
BoW模型最初是为解决文档建模问题而提出的,因为文本本身就是由单词组成的。它忽略文本的词序,语法,句法,仅仅将文本当作一个个词的集合,并且假设每个词彼此都是独立的。这样就可以使用文本中词出现的频率来对文档进行描述,将一个文档表示成一个一维的向量。
将BoW引入到计算机视觉中,就是将一幅图像看着文本对象,图像中的不同特征可以看着构成图像的不同词汇。和文本的BoW类似,这样就可以使用图像特征在图像中出现的频率,使用一个一维的向量来描述图像。
BOW一般过程:
- 取一个样本数据集
- 对样本集中的每幅图像提取描述符(采用SIFT,SURF等方法)
- 将每一个描述符都加入到BOW训练器中
- 将描述符聚类到K簇中(聚类的中心就是视觉单词)

- 利用词汇字典中的词汇表示图像, 利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用词汇字典中的词汇近似代替,通过统计词汇字典中每个词汇在图像中出现的次数,可以将图像表示成为一个k维数值向量, 即基于这些特征到最近簇心的距离来实现向量化,已形成直方图。

简略过程:
feature_detector = cv2.xfeatures2d.SIFT_create()
bow_kmeans_trainer = cv2.BOWKMeansTrainer(k)
voc = bow_kmeans_trainer.cluster()
bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(self.descriptor_extractor, flann)
bow_img_descriptor_extractor.setVocabulary(voc)
bow_img_descriptor_extractor.compute(im, feature_detector.detect(im))
三、深度学习方法

R-CNN
结构:selective search →ROI →CNN→max score
也可参考:这篇文章
对一张图片,用各种大小的框(大牛们发明好多选定候选框的方法,比如EdgeBoxes和Selective Search。)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)候选区域方法(region proposal method)创建目标检测的感兴趣区域(ROI)。在选择性搜索(selective search,SS)中,我们首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。能够生成候选区域的方法很多,比如: objectness、selective search、category-independen、object proposals、constrained parametric min-cuts(CPMC)、 multi-scale、 combinatorial grouping、Ciresan。 R-CNN 采用的是 Selective Search 算法。
**selective search:**
输入: 一张图片;
输出:候选的目标位置集合L
算法:
1: 利用切分方法得到候选的区域集合R = {r1,r2,…,rn}
2: 初始化相似集合S = ϕ
3: foreach 遍历邻居区域对(ri,rj) do
4: 计算相似度s(ri,rj)
5: S = S ∪ s(ri,rj)
6: while S not=ϕ do
7: 从S中得到最大的相似度s(ri,rj)=max(S)
8: 合并对应的区域rt = ri ∪ rj
9: 移除ri对应的所有相似度:S = S\s(ri,r*)
10: 移除rj对应的所有相似度:S = S\s(r*,rj)
11: 计算rt对应的相似度集合St
12: S = S ∪ St
13: R = R ∪ rt
14: L = R中所有区域对应的边框


下面展开进行介绍
1、生成候选区域
使用Selective Search(选择性搜索)方法对一张图像生成约2000-3000个候选区域,基本思路如下:
(1)使用一种过分割手段,将图像分割成小区域
(2)查看现有小区域,合并可能性最高的两个区域,重复直到整张图像合并成一个区域位置。优先合并以下区域:- 颜色(颜色直方图)相近的 -纹理(梯度直方图)相近的- 合并后总面积小的- 合并后,总面积在其BBOX中所占比例大的在合并时须保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其它小区域,保证合并后形状规则。
(3)输出所有曾经存在过的区域,即所谓候选区域
2、特征提取
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。
使用CNN模型进行训练,例如AlexNet,一般会略作简化,如下图:
3、类别判断
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络(如上图的AlexNet)输出的4096维特征,输出是否属于此类。
4、位置精修
目标检测的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小,故需要一个位置精修步骤,对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
R-CNN将深度学习引入检测领域后,一举将PASCAL VOC上的检测率从35.1%提升到53.7%。
位置精修方法:
G x = P x + P w ∗ t x , G y = P y + P w ∗ t y , G w = P w ∗ e t w , G h = P h ∗ e t h G_x= P_x+P_w*t_x, \\G_y= P_y+P_w*t_y, \\G_w= P_w*e^{t_w},\\G_h= P_h*e^{t_h} Gx=Px+Pw∗tx,Gy=Py+Pw∗ty,Gw=Pw∗etw,Gh=Ph∗eth
最大瓶颈是2k个候选区域都要经过一次CNN,速度非常慢。Kaiming He大神最先对此作出改进,提出了SPP-net,最大的改进是只需要将原图输入一次,就可以得到每个候选区域的特征。
[完结]
SPP-NET(金字塔池化)
(金字塔池化) -> ROI POOLING

我们使用三层的金字塔池化层pooling,分别设置图片切分成多少块,论文中设置的分别是(1,4,16),然后按照层次对这个特征图feature A进行分别处理(用代码实现就是for(1,2,3层)),也就是在第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征,
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征.
然后将这1+4+16=21个特征输入到全连接层,进行权重计算. 当然了,这个层数是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可
[完结]
Fast RCNN
也可参考这篇文章




一张完整图片–>CNN–>得到每张候选框的特征–>分类+回归
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
[完结]
RPN(region proposal network)
通过上述介绍可以知道,Faster R-CNN与Fast R-CNN最大的区别就是提出了一个叫RPN(Region Proposal Networks)的网络,专门用来推荐候选区域的,RPN可以理解为一种全卷积网络,该网络可以进行end-to-end的训练,最终目的是为了推荐候选区域,如下图所示
 Feature map->经卷积得到score[N,C,2] and loc[N,C,4] loc即dx, dy, dw, dh, 经下列与anchor变换后得到原图尺寸对应的推荐框。再经高宽大于阈值的筛选,score top6000的筛选,得到6000个符合要求的推荐框。再经NMS 得到剩下的推荐框。
Feature map->经卷积得到score[N,C,2] and loc[N,C,4] loc即dx, dy, dw, dh, 经下列与anchor变换后得到原图尺寸对应的推荐框。再经高宽大于阈值的筛选,score top6000的筛选,得到6000个符合要求的推荐框。再经NMS 得到剩下的推荐框。

解释一下上面这张图:
1)在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图(feature maps),所以相当于feature map每个点都是256-dimensions
2)在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息),同时256-d不变
3)假设在conv5 feature map中每个点上有k个anchor(原文如上k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates(scores和coordinates为RPN的最终输出)
4)补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(至于什么是合适的anchors接下来RPN的训练会讲)
RPN训练中对于正样本文章中给出两种定义。第一,与ground truth box有最大的IoU的anchors作为正样本;第二,与ground truth box的IoU大于0.7的作为正样本。文中采取的是第一种方式。文中定义的负样本为与ground truth box的IoU小于0.3的样本。
[完结]
Faster RCNN
也可参考这篇文章和这篇文章
Faster R-CNN的主要贡献是设计了提取候选区域的网络RPN,代替了费时的选择性搜索,使得检测速度大幅提高。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









