







在推荐系统中,分析和挖掘用户行为是至关重要的,尤其是在美团外卖这样的平台上,用户行为表现出多样性,包括不同的行为主体(如商家和产品)、内容(如曝光、点击和订单)和场景(如APP首页和小程序)。传统的推荐系统通过不断添加用户行为到模型中,导致两个主要问题:一是行为主体的多样性导致特征稀疏,二是用户、商家和商品行为的独立建模忽略了行为间的异构知识融合。为了克服这些问题,研究者们提出了利用大模型(LLM)来融合和推理用户行为中的异构知识。LLM因其丰富的语义知识和强大的推理能力,在多个领域展现了卓越性能。通过设计新的用户行为建模框架,研究者们能够将结构化的用户行为数据转化为非结构化的异构知识,进而通过指令调整和微调,使LLM更精准地适应个性化推荐任务。这一方法不仅提高了推荐系统的性能,还为处理用户行为的复杂性和多样性提供了新途径。
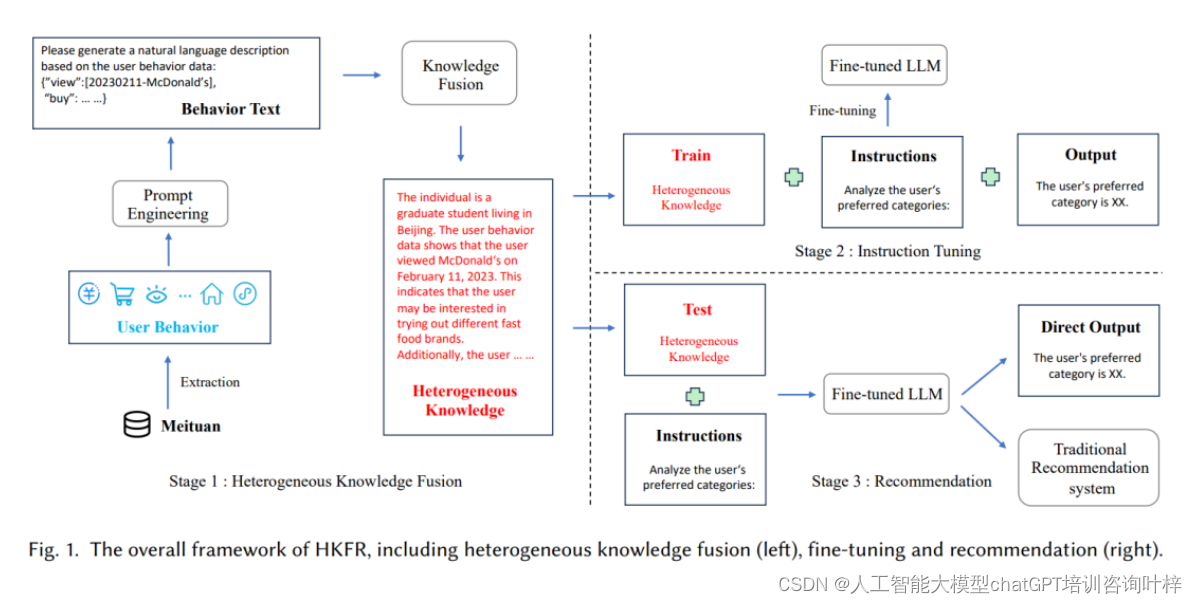
异构知识融合(HKF)是一种创新的个性化推荐方法,通过以下三个阶段实现的:
1. 异构知识融合
在这一阶段,研究者们利用大型语言模型(LLM)的语义理解和推理能力,将用户行为中的多样化信息融合为统一的知识表示。具体来说,他们首先从数据库中以用户为中心提取出多维度的行为数据,包括不同的行为主体(如商家、商品)、行为内容(如曝光、点击、订单)和行为场景(如APP首页、小程序)。然后,通过设计模板化的文本语言,将这些异构行为数据转化为结构化的文本描述。最后,使用如ChatGPT这样的LLM进行知识融合,将行为文本转化为包含丰富语义信息的异构知识文本。
2. 指令微调(Instruction Tuning)
为了使LLM更好地适应推荐任务并提高其在推荐任务中的性能,研究者们设计了一个指令数据集,该数据集包含了输入、指令和输出三个部分。输入即为上一阶段生成的异构知识文本。指令则是一系列为推荐任务特别设计的任务描述,包括用户对类别、价格和商家等的偏好推荐。输出是用户下一次订单的真实标签。基于这个指令数据集,研究者们对LLM进行微调,以提高其对异构知识的理解和推荐任务的适应性。他们选择了一个开源的LLM模型ChatGLM-6B作为基础模型,并采用了LoRA(Low-rank Adaptation)方法进行微调。
3. 推荐
在推荐阶段,研究者们将用户行为的异构知识从数据库中检索出来,作为LLM的输入。然后,根据推荐任务设计指令,利用微调后的LLM进行推理和计算,最终输出用户的推荐结果。这些推荐结果可以是直接以自然语言形式呈现的推荐内容,也可以作为语义特征,与传统推荐模型中的现有特征结合,以增强推荐效果。
通过这三个阶段,研究者们构建了一个能够处理用户行为异构性并提供个性化推荐的系统。该方法的核心在于利用LLM的能力来理解和整合用户行为中的复杂信息,并通过专门的指令调整来优化模型的推荐性能。
作者们通过一系列实验来验证他们提出的异构知识融合(HKF)方法在个性化推荐任务中的有效性。以下是实验部分的详细说明:
1. 实验实施
数据集: 作者们选择了2023年3月至4月的美团外卖数据集作为实验数据。
任务设计: 设计了20个推荐任务指令,构建了包含10万用户和100万条指令数据的数据集。
测试集: 测试集选自2023年5月9日的样本,包含10,000条指令数据,用于评估推荐POIs和类别的任务。
数据限制: 由于输入长度限制,用户序列长度被限制为300。
匿名化处理: 用户和POI数据在输入到LLM之前进行了匿名化处理。
2. 结果与分析
评估指标: 为了评估推荐效果,作者们选择了top-k HR(精准率)和top-k NDCG(标准化折扣累积增益)作为评估指标,其中k=5和10。
与传统方法比较: 将HKF方法与传统推荐方法(如Caser和BERT4Rec)以及语言模型(如P5和ChatGLM-6B)进行了比较。
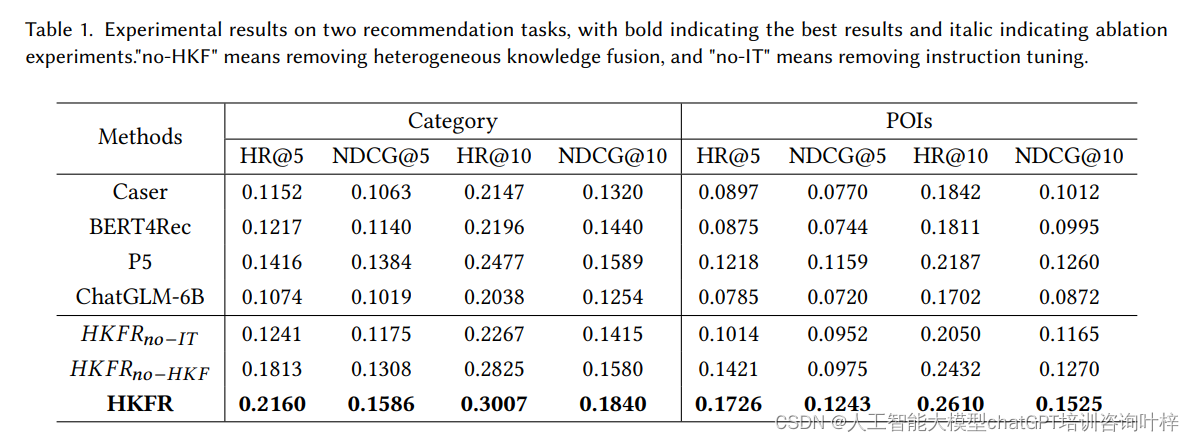
实验结果
性能提升: 实验结果表明,HKF方法在Waimai数据集上的表现超过了多个基线模型,实现了显著的性能提升。
异构知识融合的重要性: 通过对比去除异构知识融合阶段的模型,证明了异构知识融合对于准确捕捉用户兴趣和提升模型性能的重要性。
指令调整的效果: 通过对比去除指令调整阶段的模型,展示了指令调整可以有效促进LLM适应下游推荐任务。
在线A/B测试
在线应用: 作者们还在美团外卖推荐系统中进行了在线A/B测试,使用前一天用户搜索查询的计算特征,并在当前日进行实时计算。
测试时间: 实验运行时间为2023年5月9日至5月19日。
测试结果: HKF方法在冷启动用户中实现了点击通过率(CTR)提升2.45%和总商品交易额(GMV)提升3.61%,而对其他用户则没有显著影响。
实验结论
实验结果证明了HKF方法在整合异构用户行为和提高推荐性能方面的有效性。作者们指出,尽管LLM在餐饮领域的专业知识不足,限制了其对异构行为的完全理解和整合,但通过在该领域进一步训练LLM,可以克服这一限制。
这些实验不仅展示了HKF方法的潜力,还为未来的研究方向提供了指导,即通过在特定领域内进一步训练LLM,以更好地整合异构知识并提升推荐系统的性能。
通过在Waimai数据集上的广泛实验,HKFR证明了其在提升个性化推荐性能方面的显著效果。未来工作的方向,即在餐饮领域对HKFR进行更深入的训练,以期实现更精准的异构知识整合和更优的推荐效果。通过不断优化和特定领域的定制化训练,HKFR有潜力进一步推动个性化推荐系统的发展。



















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











