









https://zhuanlan.zhihu.com/p/34404607
https://zhuanlan.zhihu.com/p/34436551
hardmax
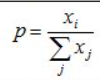
softmax
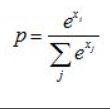
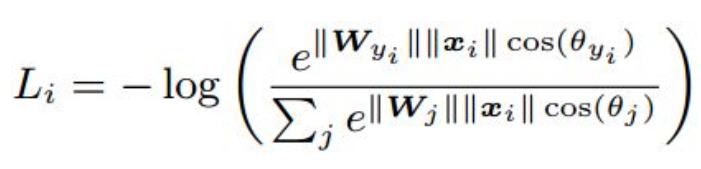
- Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
- 但Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠。
- 所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
Large-softmax(增大类间m倍角度)


- SphereFace W归一化
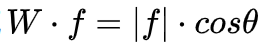
- ArcFace f也归一化
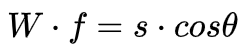
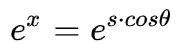
仅仅考虑cos优化
Angular softmax==SphereFace(w归一化)

归一化了权值W,让训练更加集中在优化深度特征映射和特征向量角度上,降低样本数量不均衡问题
L-Softmax和SphereFace都采用乘性margin使不同类别更加分离,特征相似度都采用cos距离,而且都开源代码非常良心。需要注意这两个loss直接训练很难收敛,实际训练中都用到了退火方法(annealing optimization strategy):
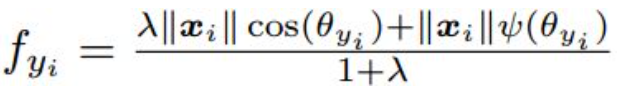
center loss
为每个类别学习一个中心,并将各个类别特征拉向这个中心


内存消耗比较大
Ringloss

COCO(con-generous cosine) loss归一化x和w


L2norm softmax:x模归一,再乘以a固定或者适应

特征权重归一化的重要性
- 从最新方法来看,权值W和特征f(或x)归一化已经成为了标配,而且都给归一化特征乘以尺度因子s进行放大,目前主流都采用固定尺度因子s的方法(看来自适应训练没那么重要)
- 权值和特征归一化使得CNN更加集中在优化夹角上,得到的深度人脸特征更加分离
- 特征归一化后,特征向量都固定映射到半径为1的超球上,便于理解和优化;但这样也会压缩特征表达的空间;乘尺度因子s,相当于将超球的半径放大到s,超球变大,特征表达的空间也更大(简单理解:半径越大球的表面积越大)
仅仅特征归一化后无法收敛必须乘以尺度因子
- 仅特征归一化时,输出 [公式] 等价于 [公式] ,理想情况下,优后 [公式] 是0,x2=x3=x4都输出0,此时激活值为{1, 0, 0, 0},指数函数非线性放大后输出为{e, 1, 1, 1},归一化后置信度是{47.54%, 17.49%, 17.49%, 17.49%},远远达不到收敛的要求,所以仅归一化是不能训练的。
- 归一化后乘尺度因子s,这里以s=60为例,输出 [公式] 等价于 [公式] ,理想情况下,优后 [公式] 是0,x2=x3=x4都输出0,此时激活值为{60, 0, 0, 0},指数函数非线性放大后输出为{exp(60), 1, 1, 1},归一化后置信度是{100%, 0%, 0%, 0%},完全可以达到收敛要求。所以特征归一化必须乘尺度因子。
AM-loss: Additive Margin loss(sphere乘性margin–>加性margin)
Additive Margin Softmax for Face Verification
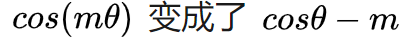
不需要退火优化
cosFace同AM-loss
CosFace: Large Margin Cosine Loss for Deep Face Recognition
ArcFace代码是Insihgtface
ArcFace: Additive Angular Margin Loss for Deep Face Recognition 2019
在SphereFace的基础上,同样改用加性margin但形式略有区别,

直接在角度空间约束。前面的softmax变体都是cos空间约束
https://zhuanlan.zhihu.com/p/76541084
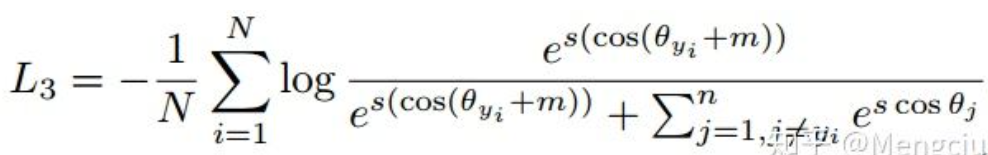


一键刷爆Facedataset
https://zhuanlan.zhihu.com/p/33750684















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









