









AttRec论文笔记
Next Item Recommendation with Self-Attention (arxiv.org)
这篇文章是18年的一篇文章,作为常用的baseline,大概阅读一下。
摘要
本文提出了一种新的序列感知推荐模型。该模型利用自注意力机制从用户的历史交互中推断出项与项之间的关系。通过自适应,它能够估计用户交互轨迹中每一项的相对权重,从而学习用户瞬时兴趣的表示。模型最终在一个度量学习框架中进行训练,同时考虑了短期和长期意图。在不同领域的大量数据集上的实验表明,我们的方法比最先进的方法有很大的优势。
相关工作
- 序列推荐
- 推荐系统+神经网络
- 注意力机制
方法
模型由两部分组成,分别是自注意力模块和collaborative metric learning(不知道这个怎么翻译),前者模拟短期喜好,后者模拟长期喜好。
1 序列推荐

U
,
I
:
\mathcal U, \mathcal I:
U,I:用户/项目集,一共
M
M
M个用户,
N
N
N个项目;
H
u
\mathcal H^u
Hu: 表示用户
u
u
u的历史序列,按时间排序;
我们的目标是:基于用户历史序列,预测下一个可能购买的商品。
2 短期兴趣建模
本文用自注意力机制来进行短期兴趣的提取,从图可以看出,改动在Value,没有用矩阵
W
v
W^v
Wv来映射。
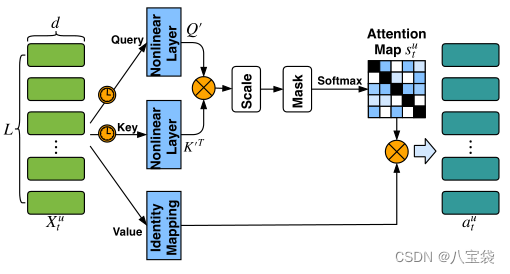
作者认为,短期兴趣可以从最近的
L
L
L次交互中提取,于是定义了矩阵
X
t
u
X^u_t
Xtu:

X
X
X的维度是
N
×
d
N\times d
N×d, 就是每行代表一个项目,embedding的维度是
d
d
d.
这个说实话不懂为什么要这样表示,每行为啥要从1到
d
d
d. (应该就是对应项目embeddings的堆叠)

常规操作,输出的
s
t
u
∈
L
×
L
s_t^u\in L\times L
stu∈L×L, 表示每个项目之间的相似性,作者直接用
X
t
u
X^u_t
Xtu当做Value,所以:

attention模块最后的输出就是
a
t
u
∈
L
×
d
a_t^u\in L\times d
atu∈L×d,看作是用户的短期兴趣。
下面的
m
t
u
m_t^u
mtu就是把
L
L
L个行向量加起来求了个平均,目的在于降维,得到单一表征,作者也比较了求和,取最值等操作来得到
m
m
m的方法。
最后,为了保持序列的特征,加入位置向量,作者用的时间尺度,直接加到
X
X
X矩阵里了,个人感觉这个没有直接加入位置embedding那样的方法更容易理解。

2 长期喜好建模

U
,
V
U, V
U,V: 用户/项目的embedding矩阵;
然后直接用了欧氏距离来衡量用户和项目直接的接近程度。(所以这样就可以表示长期兴趣了吗。。?)
目标函数
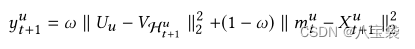
y
y
y就是用来排序的喜好度得分,
H
t
+
1
u
\mathcal H^u_{t+1}
Ht+1u就是对用户
u
u
u预测的当前项目,前面半截是长期兴趣,后面的半截是短期,用
ω
\omega
ω来控制权重。前后都是用的“用户”和项目间的距离,
V
V
V和
X
X
X都是项目embedding, 只是学习的参数不一样。(这里感觉符号系统有问题,后面
X
X
X应该没有上标
u
u
u的。)
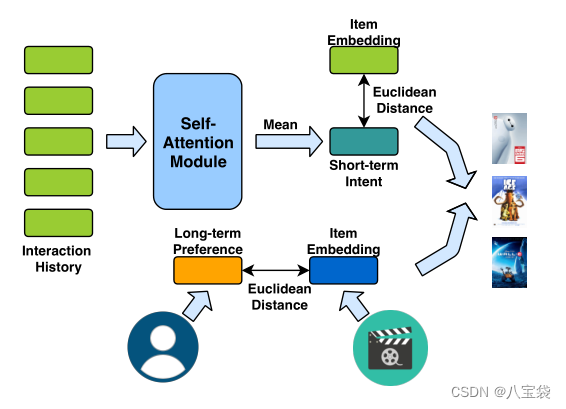
这个图竟然就是整个流程了。。。
损失函数
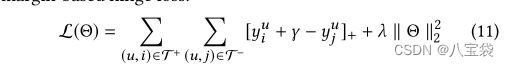
margin-based hinge loss,成对训练,
γ
\gamma
γ作为一个分割正负例的边界(这个不懂是干嘛的,第一次接触,本文设置为0.5),
i
,
j
i,j
i,j就是正负样本,后面是
λ
\lambda
λ控制的正则项。好像没说训练的负样本个数是多少,不知道是不是我没找到。
实验部分
指标
用了MRR和HR@50
效果
略
总结
刚刚入门序列推荐,感觉这个比SASRec拉了些。。感觉方法太过于简单,短期兴趣用最近交互的L=5个项目通过attention机制得到,长期兴趣直接用项目和用户之间的欧氏距离。
损失函数第一次接触,打算再看几篇文章,看看有没有其他人用。














 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









