









 本文详细比较了多种语音合成模型,包括Fastspeech、VITS、MB-iSTFT-VITS等,分析了它们的架构、训练速度、性能差异,并介绍了VITS与MB-iSTFT-VITS的区别。实验结果显示,VITS在数据较少情况下表现良好,而MB-iSTFT-VITS更轻量化。还探讨了模型微调策略以适应多人语音合成。
本文详细比较了多种语音合成模型,包括Fastspeech、VITS、MB-iSTFT-VITS等,分析了它们的架构、训练速度、性能差异,并介绍了VITS与MB-iSTFT-VITS的区别。实验结果显示,VITS在数据较少情况下表现良好,而MB-iSTFT-VITS更轻量化。还探讨了模型微调策略以适应多人语音合成。
----------------------------------🗣️ 语音合成 相关系列直达 🗣️ -------------------------------------
🫧VITS :TTS | 保姆级端到端的语音合成VITS论文详解及项目实现(超详细图文代码)
🫧MB-iSTFT-VITS:TTS | 轻量级语音合成论文详解及项目实现
🫧MB-iSTFT-VITS2:TTS | 轻量级VITS2的项目实现以及API设置-CSDN博客
🫧PolyLangVITS:MTTS | 多语言多人的VITS语音合成项目实现-CSDN博客
🫧NaturalSpeech:TTS | NaturalSpeech语音合成论文详解及项目实现-CSDN博客
本文主要是语音合成模型实验结果经验总结!!
首先列出实验过的所有模型
- Fastspeech&Fastspeech2
- Tacotron&Tacotron2
- Transformer-TTS
- Bark(E2E)
- VITS/VITS2(E2E)
- NaturalSpeech2
- MB-iSTFT-VITS/ MB-iSTFT-VITS2(E2E)
1.语音合成主主要架构如下
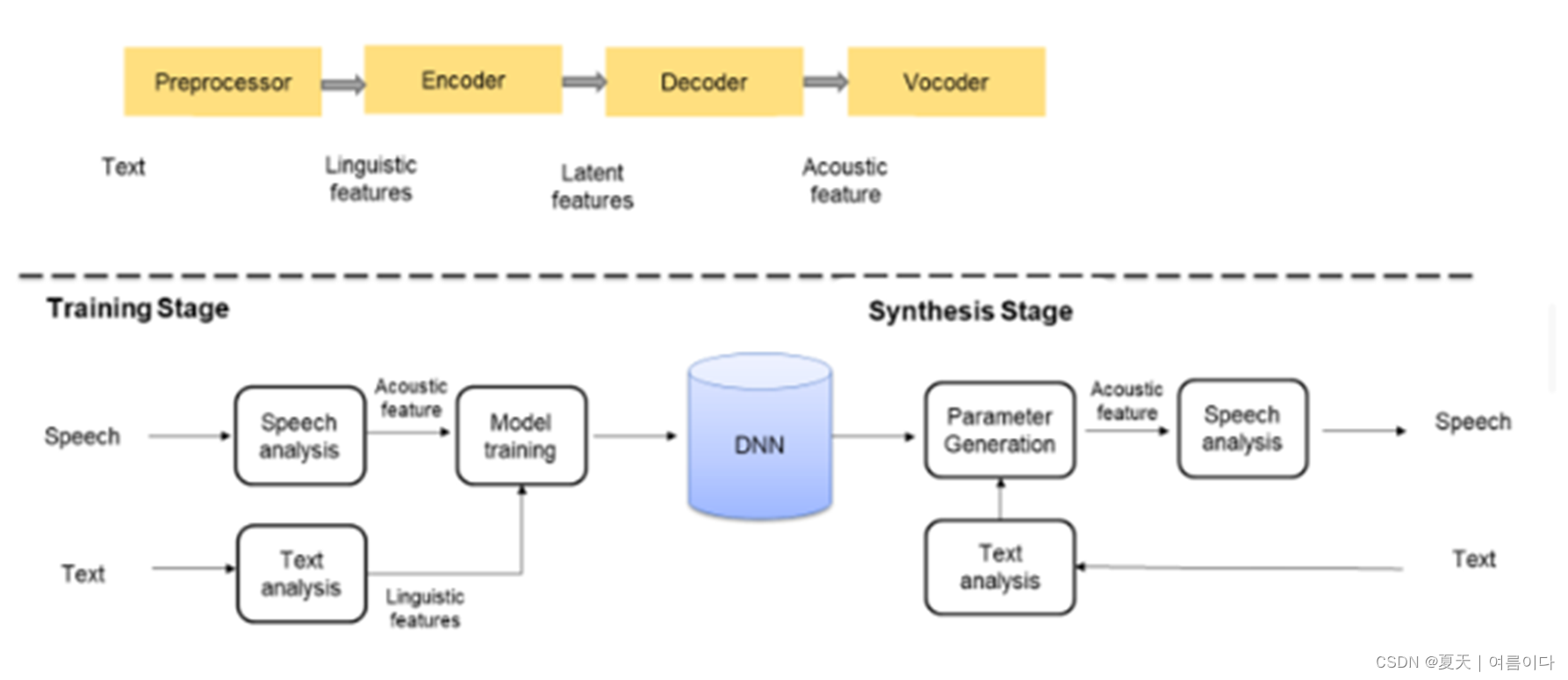
2.模型间的比较
# 比较基于同样的数据,参数等测试结果
| Model | Fastspeech2(VocGAN) | VITS | MB-iSTFT-VITS | MB-iSTFT-VITS2 | mini-MB-iSTFT-VITS2 | NaturalSpeech |
| Feature | MFA | MAS | MAS | MAS | MAS | MFA |
| Params | 27.0M | 28.11M | 27.49M | × | × | × |
| Model | checkpoint | G 456.22MB | D:535.10MB G:397.97MB | D:535.10MB G:420.90MB | D:535.09MB | D:535.09MB G:286.02MB |
| Train Speed | 5day | 4day | 8day | 8day | 2weeks | × |
| Inference Speed | 3.01sec | 2.44sec | 0.98sec | 1.9sec | 1.9sec | × |
3.模型优缺点
Fatespeech系列是俩阶段模型,对数据要求较高,尤其在使用MFA工具进行对齐时,可能出现错误,且语音数据越多,相对来说学习的越好。
VITS系列典型的端到端模型,便于训练,且在数据集较少的情况下依旧可以生成较好的语音。
4.vits与MB-isftf-vits的区别
论文中有详细体现,主要是代码实现的区别
在训练(train)中增加
"fft_sizes": [384, 683, 171],
"hop_sizes": [30, 60, 10],
"win_lengths": [150, 300, 60],
"window": "hann_window"在数据(data)中增加
"use_mel_posterior_encoder": true,
在模型(model)中
"use_mel_posterior_encoder": true,
"use_transformer_flows": true,
"transformer_flow_type": "pre_conv2",
"use_spk_conditioned_encoder": false,
"use_noise_scaled_mas": true,
"use_duration_discriminator": true,
"duration_discriminator_type": "dur_disc_2",
"ms_istft_vits": false,
"mb_istft_vits": true,
"istft_vits": false,
"subbands": 4,
"gen_istft_n_fft": 16,
"gen_istft_hop_size": 4,
vits中hidden_channels是192,而mb-istft-vits是96,因为mb-istft-vits是居于istft-vits构建的。
主要区别如下
if "use_mel_posterior_encoder" in hps.model.keys() and hps.model.use_mel_posterior_encoder == True: # P.incoder for vits2
print("Using mel posterior encoder for VITS2")
posterior_channels = 80 # vits2
hps.data.use_mel_posterior_encoder = True
else:
print("Using lin posterior encoder for VITS1")
posterior_channels = hps.data.filter_length // 2 + 1
hps.data.use_mel_posterior_encoder = False5.模型权重微调
在单人模型中训练三天后,(6000数据+A100)得到比较好的结果,使用最优权重在多人数据集且每个人语音数据为300左右上进行微调,结果表明虽基于不用的数据集进行训练,训练后生成的语音依旧比较像一开始的单人模型的音色。



















 3266
3266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











