






 本文介绍了PointNet中的T-Net,一个微型网络用于生成3x3旋转矩阵,标准化点云的旋转和平移。STN3d和STNkd类展示了如何实现这种变换,而PointNetfeat模块结合了全局特征和特征变换。
本文介绍了PointNet中的T-Net,一个微型网络用于生成3x3旋转矩阵,标准化点云的旋转和平移。STN3d和STNkd类展示了如何实现这种变换,而PointNetfeat模块结合了全局特征和特征变换。
pointnet网络中t-net网络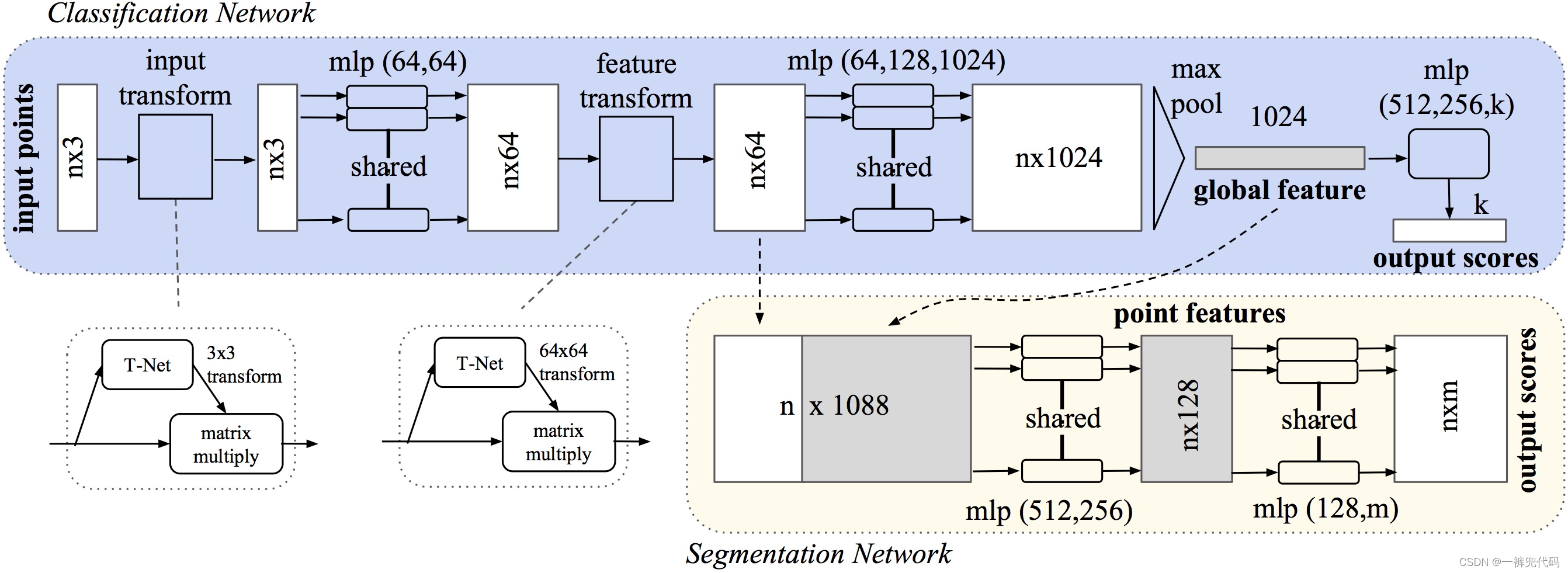
T−Net是一个微型网络,用于生成一个仿射变换矩阵来对点云的旋转、平移等变化进行规范化处理。这个变换/对齐网络是一个微型的PointNet,它输入原始点云数据,输出为一个3∗3 的旋转矩阵
1.输入的点云为(x,y,z),需要一个3*3的旋转矩阵
2.将点云映射到k维的冗余空间,学习一个k*k的旋转矩阵,由于旋转矩阵具有正交性,因此校对需要引入一个正则化的惩罚项,希望尽可能接近于一个正交矩阵
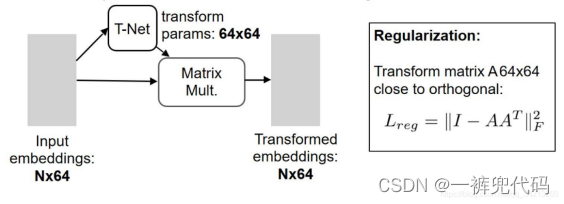
在网上找到两段代码,方便大家学习一下!!!
# T-Net: is a pointnet itself.获取3x3的变换矩阵,校正点云姿态;效果一般,后续的改进并没有再加入这部分
# 经过全连接层映射到9个数据,最后调整为3x3矩阵
class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
#mlp
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
#fc
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
#激活函数
self.relu = nn.ReLU()
#bn
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
# Variable已被弃用,之前的版本中,pytorch的tensor只能在CPU计算,Variable将tensor转换成variable,具有三个属性(data\grad\grad_fn)
# 现在二者已经融合,Variable返回tensor
# iden生成单位变换矩阵
# repeat(batchsize, 1),重复batchsize次,生成batchsize x 9的tensor
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
#将单位矩阵送入GPU
if x.is_cuda:
iden = iden.cuda()
x = x + iden
# view()相当于numpy中的resize(),重构tensor维度,-1表示缺省参数由系统自动计算(为batchsize大小)
# 返回结果为 batchsize x 3 x 3
x = x.view(-1, 3, 3)
return x
# 数据为k维,用于mlp之后的高维特征,同上
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
#包含变换矩阵的中间网络
class PointNetfeat(nn.Module):
def __init__(self, global_feat = True, feature_transform = False):
super(PointNetfeat, self).__init__()
self.stn = STN3d()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
self.feature_transform = feature_transform
if self.feature_transform:
self.fstn = STNkd(k=64)
def forward(self, x):
n_pts = x.size()[2]# size()返回张量各个维度的尺度
trans = self.stn(x)#得到3x3的坐标变换矩阵
x = x.transpose(2, 1)#调整点的维度,将点云数据转换为nx3形式,便于和旋转矩阵计算
x = torch.bmm(x, trans)#点的坐标和3x3的变换矩阵相乘
x = x.transpose(2, 1)#再把点的坐标调整回来3xn
x = F.relu(self.bn1(self.conv1(x)))#作者本来在这里用了两次mlp
if self.feature_transform:
trans_feat = self.fstn(x)#得到64x64的特征变换矩阵
x = x.transpose(2,1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2,1)
else:
trans_feat = None
pointfeat = x# 保留经过第一次mlp的特征,便于后续分割进行特征拼接融合
x = F.relu(self.bn2(self.conv2(x)))# 第二次mlp的第一层,64->128
x = self.bn3(self.conv3(x))# 第二次mlp的第二层,128->1024
x = torch.max(x, 2, keepdim=True)[0]# pointnet的核心操作,最大池化操作保证了点云的置换不变性(最大池化操作为对称函数)
x = x.view(-1, 1024)# resize池化结果的形状,获得全局1024维特征
if self.global_feat:
return x, trans, trans_feat#返回特征、坐标变换矩阵、特征变换矩阵
else:
x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)
return torch.cat([x, pointfeat], 1), trans, trans_feat#分割时候会用到的global特征、坐标变换矩阵、特征变换矩阵
在这里插入代# K=3 代表输入的是原始点云,是每个点的维度(x,y,z). point_cloud 是一个Tensor,属性如下:
# point_cloud=Tensor("Placeholder:0", shape=(32, 1024, 3), dtype=float32, device=/device:GPU:0)
def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = point_cloud.get_shape()[0].value #点云的个数(一个batch包含的点云数目,pointNet 为 32)
num_point = point_cloud.get_shape()[1].value #每个点云内点的个数 (pointNet 为 1024)
input_image = tf.expand_dims(point_cloud, -1) #在point_cloud最后追加一个维度,BxNx3 变成 BxNx3x1 3d张量-->4d张量
# 输入点云point_cloud有3个axis,即B×N×3,tf.expand_dims(point_cloud, -1) 将点云最后加上一个size为1 的axis
# 作为 input_image(B×N×3×1),则input_image的channel数为1。
# net=Tensor("transform_net1/tfc1/Relu:0", shape=(x,x,x,x), dtype=float32, device=/device:GPU:0)
# 64 代表要输出的 channels (单通道变成64通道)
# [1,3]代表1行3列的矩阵,作为卷积核。将B×N×3×1转换成 B×N×1×64
# 步长:stride=[1,1] 代表滑动一个距离。决定滑动多少可以到边缘。
# padding='VALID',在原始图像上加边界(这里默认不加)
# bn: 批归一化
# is_training=is_training 设置训练模式
# bn_decay=bn_decay
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
# 128 代表要输出的 channels
# [1,1]代表1行1列的矩阵,作为卷积核。将B×N×1×64转换成 B×N×1×128
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
# 1024 代表要输出的 channels
# [1,1]代表1行1列的矩阵,作为卷积核。将B×N×1×128转换成 B×N×1 X 1024
net = tf_util.conv2d(net, 1024, [1, 1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
#对上一步做 max_pooling 操作,将B×N×1×1024 转换成 B×1×1 X 1024
net = tf_util.max_pool2d(net, [num_point, 1], padding='VALID', scope='tmaxpool')
# 利用1024维特征生成256维度的特征向量
# 将 Bx1x1x1024变成 Bx1024
net = tf.reshape(net, [batch_size, -1])
# 将 Bx1024变成 Bx512
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
# 将 Bx512变成 Bx256
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_XYZ') as sc:
assert(K==3)
# weights(wights,[256,9],dtype=tf.float32)
weights = tf.get_variable('weights', [256, 3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
#<tf.Variable 'transform_net1/transform_XYZ/biases:0' shape=(9,) dtype=float32_ref>
biases = tf.get_variable('biases', [3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
#<tf.Variable 'transform_net1/transform_XYZ/biases:0' shape=(9,) dtype=float32_ref>
#变成
#Tensor("transform_net1/transform_XYZ/add:0", shape=(9,), dtype=float32, device=/device:GPU:0)
biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)
# net = shape(32,256) weight = shape(256,9) ===> net*weight = transform(32,9)
# Tensor("transform_net1/transform_XYZ/MatMul:0", shape=(32, 9), dtype=float32, device=/device:GPU:0)
transform = tf.matmul(net, weights)
# Tensor("transform_net1/transform_XYZ/MatMul:0", shape=(32, 9), dtype=float32, device=/device:GPU:0)
# 变成
# Tensor("transform_net1/transform_XYZ/BiasAdd:0", shape=(32, 9), dtype=float32, device= / device: GPU:0)
transform = tf.nn.bias_add(transform, biases)
# 由Tensor("transform_net1/transform_XYZ/BiasAdd:0", shape=(32, 9), dtype=float32, device=/device:GPU:0)
# 变成
# Tensor("transform_net1/Reshape_1:0", shape=(32, 3, 3), dtype=float32, device=/device:GPU:0)
transform = tf.reshape(transform, [batch_size, 3, K])
return transform码片


















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









