







随着政府数据开放政策的推进,越来越多的公共数据资源被公开,为研究者、开发者以及公众提供了宝贵的信息资源。深圳市政府公开数据平台便是其中之一,提供了丰富的数据集以供下载和使用。本篇文章将详细介绍如何通过注册深圳市政府公开数据平台账号,并使用API接口批量下载数据集。我们将按照步骤完成从注册账号到通过API接口获取数据的全过程,并提供一份完整的Python脚本,实现自动化下载。
首先需要注册平台的账号,最好实名认证,这样可以下载的数据比较多;
找到需要下载的数据,选择下面的调用数据接口,在跳转的页面中找到调用说明部分;
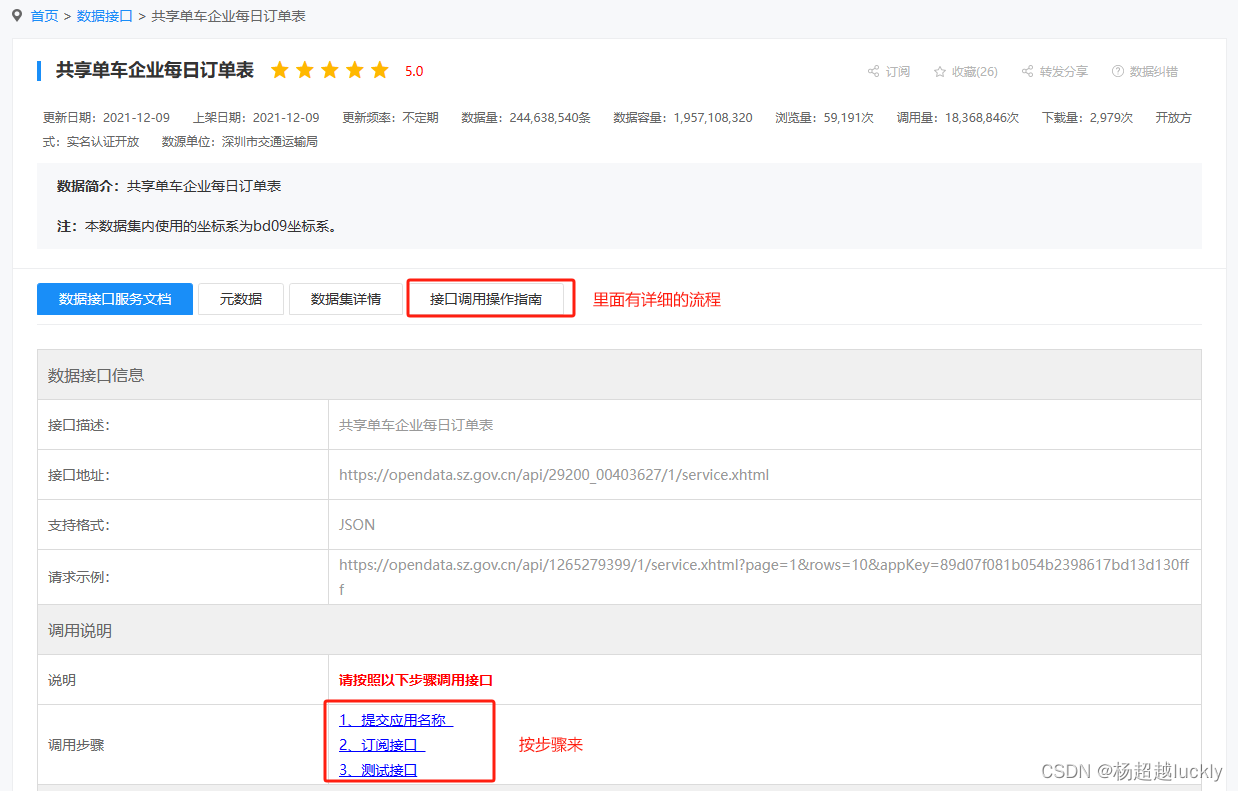
接口文档步骤部分:一定要按1.提交应用名称,2.订阅接口,3.测试接口的步骤来,也可以下载接口文档,里面有详细的操作说明;然后进行接口测试发送请求,看是否有返回内容;
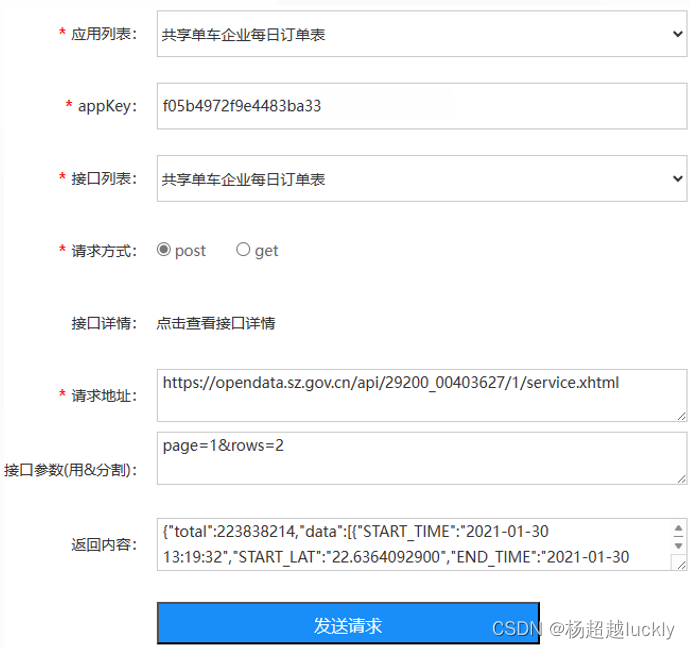
通过接口获取时会有两个参数:ROWS和PAGE,ROWS=N代表把N条数据作为一页对数据集进行划分,PAGE=M代表选取第M页的数据;
下面是通过接口获取数据的代码,将代码中的"RequestURL","DataSize","appKey"分别改成请求地址,数据条数和appKey然后运行即可;
# 完整代码(环境Python3.11)
import requests
import pandas as pd
import time
# 参数设置
RequestURL = 'https://opendata.sz.gov.cn/api/29200_00403627/1/service.xhtml' # 输入项目地址
Rows = 5000 # 每页返回的记录数
DataSize = 10000 # 输入次数
PageSize = (DataSize + Rows - 1) // Rows # 计算总页数
appKey = 'f05b4972f9e4483ba33' # API密钥
header = headers = {'User-Agent': 'Custom'} # 设置请求头
FileName = 'dataset.csv' # 输出文件名
# 测试API请求,检查返回状态码是否为200
print('Page Size:', PageSize)
strhtml = requests.get(RequestURL + '?appKey=' + appKey + '&page=1&rows=1', headers=header)
if strhtml.status_code != 200:
print('API请求失败,状态码:', strhtml.status_code)
exit()
# 读取数据
pd_data = []
page_num = 1
while page_num <= PageSize:
# 计算当前页码对应的URL参数
page_params = '?appKey=' + appKey + '&page=' + str(page_num) + '&rows=' + str(Rows)
try:
# 发送请求并获取响应内容
strhtml = requests.get(RequestURL + page_params, headers=header)
data = strhtml.json()['data']
if page_num == PageSize: # 最后一页数据可能不足Rows条,需特殊处理
data = data[:DataSize % Rows]
for row in data:
# 将每条数据转换为DataFrame,并添加到pd_data列表中
pd_data.append(pd.DataFrame.from_dict(row, orient='index').T)
print('获取第{}页数据,共{}页'.format(page_num, PageSize))
page_num += 1
except Exception as e:
print('请求第{}页数据失败,原因:{}'.format(page_num, e))
continue
# 将所有DataFrame合并为一个DataFrame并保存为CSV文件
pd.concat(pd_data, ignore_index=True).to_csv(FileName)
print('数据已成功保存为', FileName)结果数据dataset.csv;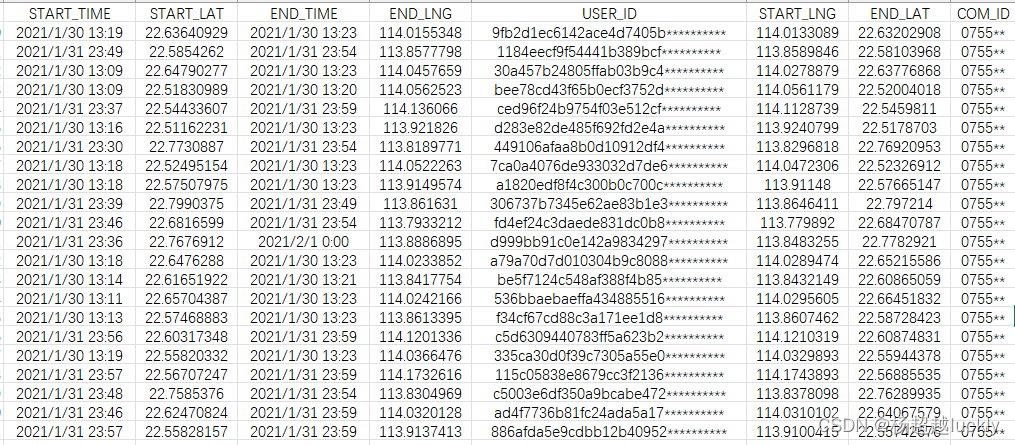
参考来源:深圳市政府公开数据集获取(附完整代码) - 知乎 (zhihu.com)
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。


















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











