







 超级会员免费看
超级会员免费看


在电力系统中有很多应用,下面还有一篇稍微比较牛的:

目录

1 灰狼优化算法基本思想
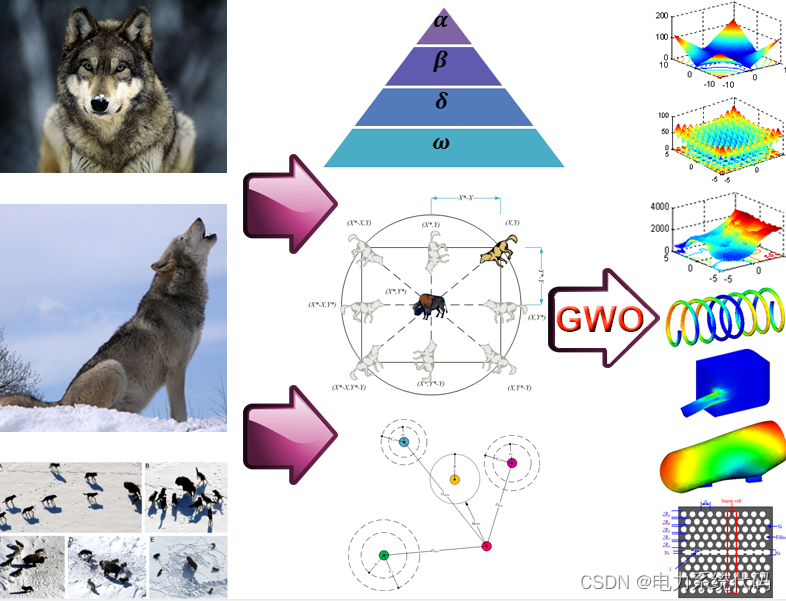
灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进。在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度。
在电力系统中有很多应用,下面还有一篇稍微比较牛的:
目录
灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进。在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

















 804
804







