






编辑:3DCV
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门独家秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 这篇文章干了啥?
随着深度学习技术的不断发展,深度神经网络(DNNs)在图像识别和物体检测任务中取得了卓越的性能,并且利用这些网络的方法在图像检索任务中也得到了广泛探索。随着视觉-语言模型的兴起和广泛应用,文本到图像的检索已成为图像检索领域的主流研究方向之一。这些模型在互联网上收集的大量成对的图像-文本数据上进行预训练,学习将图像及其对应的文本映射到共享潜在空间中的相似密集向量表示。通过利用这些预训练模型,可以根据其密集向量之间的距离计算来检索与查询文本在语义上相似或相关的图像。
图像可以包含各种信息和特征,而判断图像是否相似或不同的标准本质上是主观的,且没有唯一定义。例如,在检索图像时,用户关注的图像特征可能因个人偏好和情境因素而异。然而,查询并不总是代表或反映用户的愿望或意图,它可能是不完整的或缺乏指定这些愿望所需的信息。尽管存在这些限制,视觉-语言模型仍试图通过基于训练过程中获得的知识来隐式补偿不完整查询中信息的缺失,从而提供与用户请求相关的结果。不幸的是,这种补偿的信息可能并不总是与用户的愿望或意图一致。
在文本检索中,基于关键词的方法在实际应用中常被用于检索包含指定关键词的文档。用户可以将多个关键词组合成搜索查询来指定其关注领域或主题。在查看检索结果后,用户可以通过修改和/或添加关键词作为反馈来迭代地优化其搜索查询。即使检索模型最初无法提供所需结果,用户也可以通过这种迭代过程自适应地获得与其偏好或意图一致的结果。鉴于这些灵活的能力,我们旨在探索将基于关键词的检索方法更好地应用于图像检索任务的方法。
虽然我们可以直接将传统的视觉-语言模型应用于基于关键词的检索,但我们不能忽视过去几年大型语言模型(LLMs)所取得的显著进展,这些模型已显示出在对话界面中理解上下文的非凡能力。此外,已经提出了多模态LLMs(M-LLMs)来通过视觉提示理解图像中的视觉信息,这涉及将图像与文本数据一起作为查询进行处理。通过利用M-LLMs的先进功能,我们可以从图像中提取特征,并以标签和字幕等文本数据的形式进行语言表示。然后,我们可以利用自然语言处理(NLP)技术的优势来进行图像检索任务。我们将生成的文本数据编码为稀疏词汇向量,并利用高效的检索算法来实现基于其稀疏词汇表示的有效图像检索。
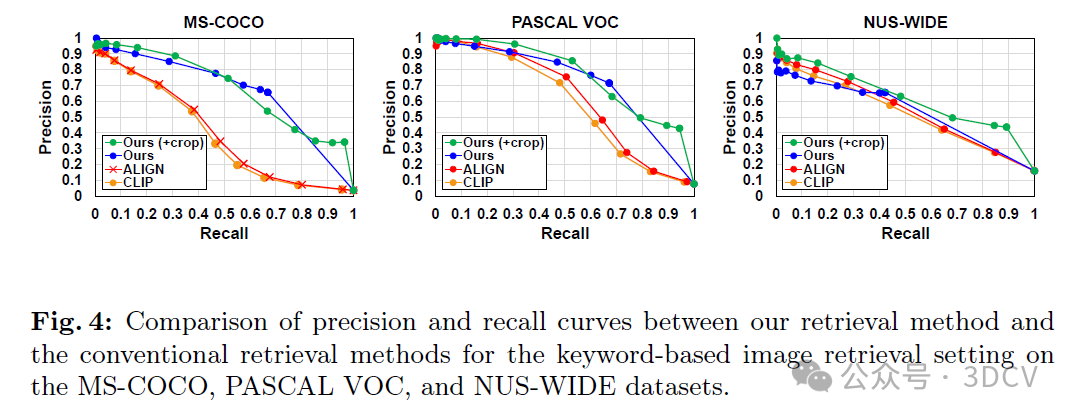
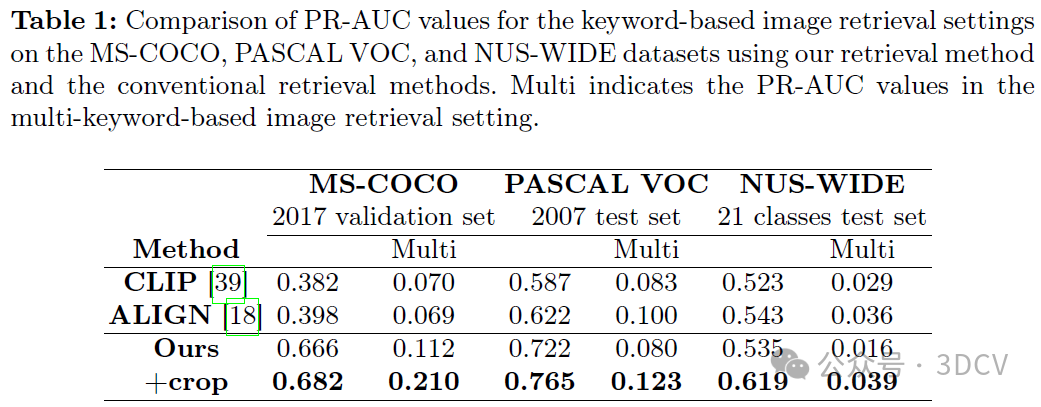
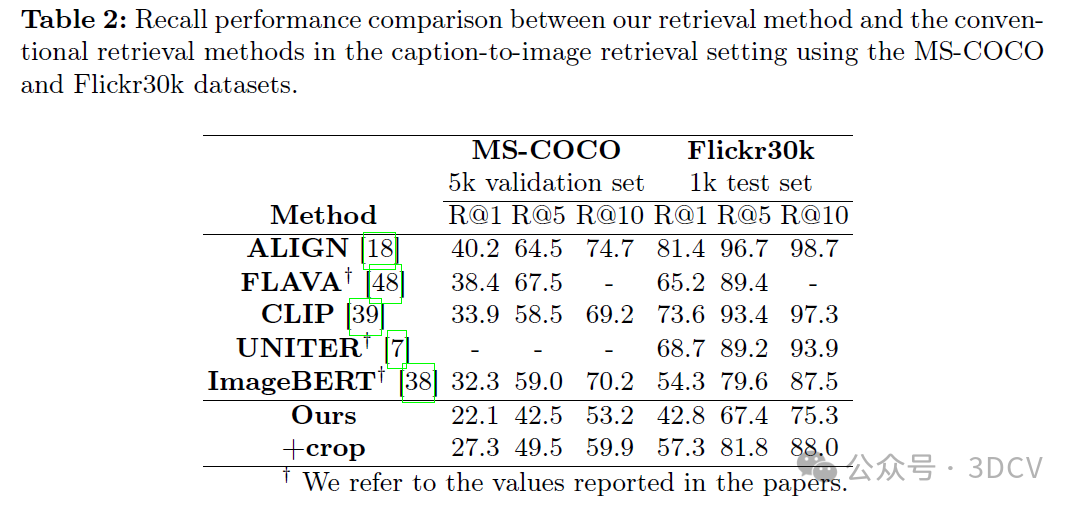
在本文中,我们专注于文本到图像的检索任务,并在这种强大的M-LLMs兴起的时代重新思考该任务。作为文本到图像的检索任务,我们考虑了一个基于关键词的图像检索场景,其中搜索查询由代表图像内容或对象的几个单词组成。通过对基准数据集进行定量分析,我们证明了我们的检索系统在精确度和召回率方面优于传统的基于视觉-语言模型的检索方法。具体而言,我们引入了一种裁剪技术来辅助M-LLM有效地提取图像特征,并通过评估图像和文本之间相关性的度量来分析其有效性。我们的研究结果表明,如果使用信息量较少的字幕作为搜索查询,则传统的基于视觉-语言模型的方法会优于我们的方法。这似乎取决于是否存在补偿信息量较少查询中信息缺失的功能。然而,当我们将关键词纳入搜索查询时,我们的系统的检索性能显著提高,使查询明确且信息丰富。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
作者:Kengo Nakata, Daisuke Miyashita, Youyang Ng, Yasuto Hoshi, Jun Deguchi
机构:Kioxia Corporation
原文链接:https://arxiv.org/abs/2408.16296
2. 摘要
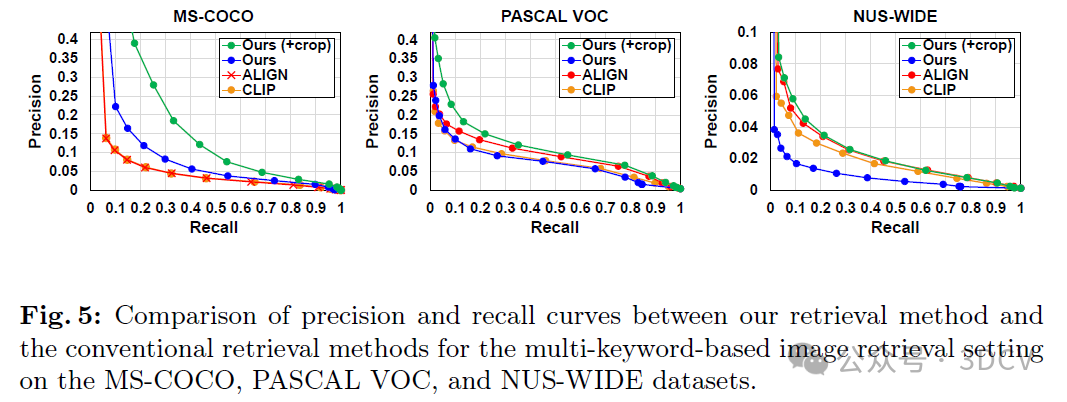
在本文中,我们重新思考稀疏词汇表示的图像检索。通过利用支持视觉提示的多模态大型语言模型(M-LLM ),我们可以提取图像特征并将其转换为文本数据,从而使我们能够利用自然语言处理中采用的高效稀疏检索算法来执行图像检索任务。为了帮助LLM提取图像特征,我们将数据增强技术应用于密钥扩展,并使用图像和文本数据之间的相关性度量来分析影响。在基于关键字的图像检索场景中,我们在MS-COCO、PASCAL VOC和NUS范围的数据集上实验性地显示了与传统的基于视觉语言模型的方法相比,我们的图像检索方法具有更好的精度和召回性能,其中关键字用作搜索查询。我们还证明了通过迭代地将关键词合并到搜索查询中可以提高检索性能。
3. 效果展示
4. 主要贡献
本文的主要贡献如下:
——我们引入了一个利用M-LLMs和基于稀疏词汇表示的检索算法的文本到图像检索系统,并在各种基准数据集上评估了其有效性。
——为了提高M-LLM在提取图像特征方面的性能,我们采用了数据增强技术进行关键词扩展,并定量评估了检索性能的提升。
5. 基本原理是啥?
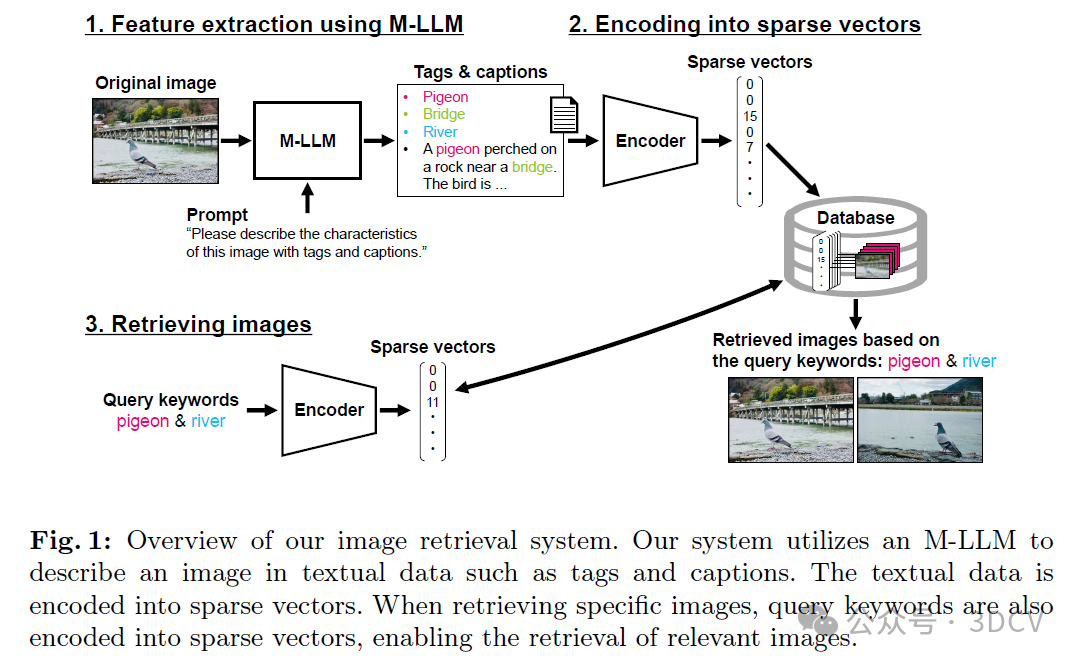
图1概述了我们的图像检索系统。该系统包含三个过程:(1)使用M-LLM进行特征提取,(2)编码为稀疏向量,(3)检索图像。我们的系统接受基于文本的查询(如关键词),并从数据库中返回一组相关图像。每个过程的具体描述如下。
关键扩展的数据增强技术。为了从图像中的不同视角充分提取特征和信息,我们采用了裁剪技术,该技术常用于图像识别任务中的数据增强。如图2所示,我们将原始图像分割成多个片段作为裁剪后的图像,例如两个垂直片段、两个水平片段、四个片段或九个片段。对于每个裁剪后的图像,M-LLM会生成一个相应的描述图像特征的标题。通过将所有生成的标题(包括从原始图像中得出的标题)连接起来,我们可以从整个图像中提取一组全面的特征。裁剪技术有助于M-LLM有效地从图像中提取特征,同时扩展数据库中的关键集(即关键扩展),从而提高检索性能。推荐课程:国内首个面向具身智能方向的理论与实战课程
对于图像裁剪,我们还可以利用YOLO或空间变换网络等目标检测模型。然而,当使用目标检测模型时,模型无法检测到对象或不存在对象的区域(如天空景观、玻璃田或海域)将不会被裁剪。因此,M-LLM无法从这些图像区域中提取信息。为了避免目标检测模型中归纳偏差的影响,本文不使用此类模型,而是采用固定模式裁剪,无论图像中对象的位置如何,如图2所示。

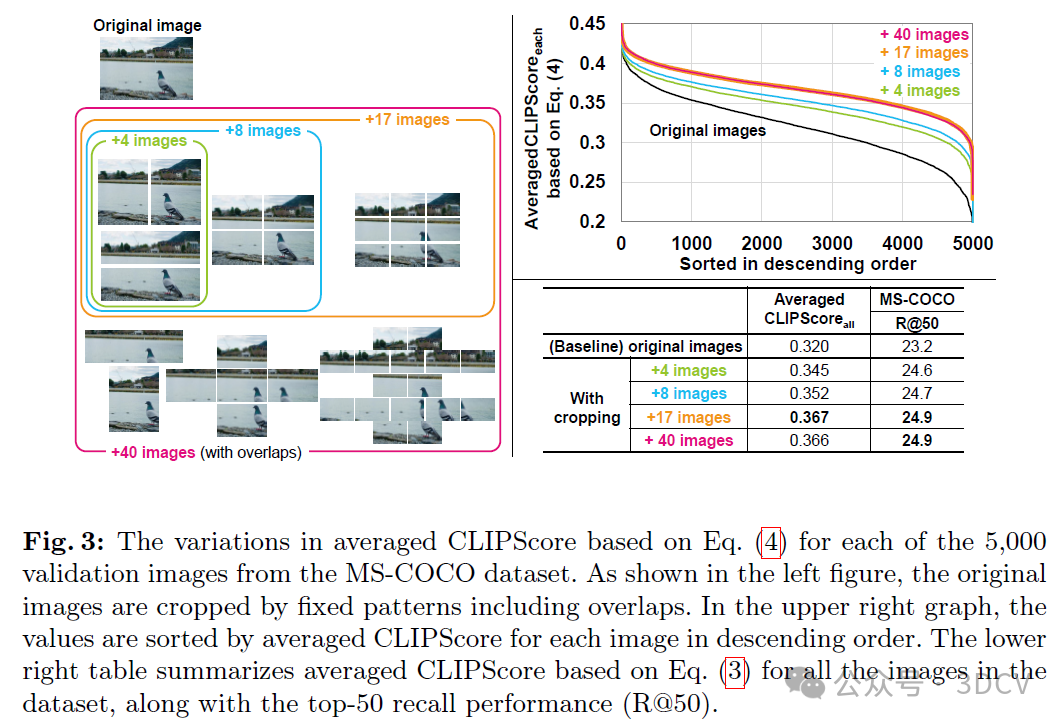
如图3左图所示,原始图像通过包含重叠边缘的固定模式进行裁剪,以评估裁剪模式边界处信息丢失的影响。图3右上图显示了根据公式(4)对MS-COCO数据集中5000张验证图像的平均CLIPScore变化。随着裁剪图像数量增加到17张,根据公式(3)计算的数据集中所有图像的平均CLIPScore增加,如右下表所示。我们还评估了检索性能,通过前50名召回率(R@50)来衡量图像检索效果(召回率根据第4.1节中描述的基于关键词的图像检索场景计算,如公式(6)所示)。随着裁剪图像数量增加到17张,我们可以观察到R@50的改进。另一方面,当裁剪图像数量从17张增加到40张(通过重叠裁剪)时,基于公式(3)的平均CLIPScore并未增加,且召回性能也未得到改善。此时,我们认为裁剪的影响已达到饱和点,原始图像的信息损失已得到有效缓解。因此,我们选择了17种固定裁剪模式。推荐课程:国内首个面向具身智能方向的理论与实战课程
6. 实验结果

7. 总结 & 未来工作
在本文中,我们介绍了一种图像检索系统,该系统利用多模态大型语言模型(M-LLM)将图像特征提取为文本数据,并采用自然语言处理(NLP)任务中常用的高效稀疏检索算法。我们将基于关键词的图像检索场景视为文本到图像的检索任务,其中利用关键词进行搜索查询和细化搜索标准。在基于关键词的图像检索场景中,我们证明了我们的方法在基准数据集上的精确度和召回率方面优于传统的基于视觉语言模型的方法。特别是,我们引入了一种裁剪技术,该技术有助于M-LLM有效地提取图像特征。我们使用CLIPScore分析了裁剪技术的影响,并基于检索性能的提升,实证展示了其有效性。最后,我们证明了像用户反馈一样将关键词迭代纳入搜索查询中,可以显著提高我们的检索性能。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
35个顶会论文的课题如下:
课题如下:
1、基于环境信息的定位,重建与场景理解
2、轻是级高保真Gaussian Splatting
3、基于大模型与GS的 6D pose estimation
4、在挑战性遮挡环境下的GS-SLAM系统研究
5、基于零知识先验的实时语义地图构建SLAM系统
6、基于3DGS的实时语义地图构建
7、基于文字特征的城市环境SLAM
8、面向挑战性环境的SLAM系统研究
9、特殊激光传感器融合视觉的稠密SLAM系统
10、基于鲁棒描述子与特征匹配的特征点法SLAM
11、基于yolo-world的语义SL系统
12、基于自监督分割的挑战性环境高斯SLAM系统
13、面向动态场景的视觉SLAM系统研究
14、面向动态场景的GS-SLAM系统研究
15、集成物体级地图的GS-SLAM系统
16、挑战场景下2D-2D,2D-3D或3D-3D配准问题
17、未知物体同时重建与位姿估计问题类别级或开放词汇位姿估计问题
18、位姿估计中的域差距问题
19、可形变对象(软体)的实时三维重建与非刚性配准
20、机器人操作可形变对象建模与仿真
21、基于图像或点云3D目标检测、语义分割、轨迹预测.
22、医疗图像分割任务的模型结构设计
23、多帧融合的单目深度估计系统研究
24、复杂天气条件下的单目深度估计系统研究高精度的单目深度估计系统研究
25、基于大模型的单目深度估计系统研究
26、高精度的光流估计系统多传感器融合的单目深度估计系统研究
28、水下图像复原/增强
30、Real-World图像去雾(无监督/物理驱动)
31、LDR图像/视频转HDR图像/视频
33、压缩后图像/视频的增强/复原
34、图像色彩增强(image retouching)
















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









