






0. 论文信息
标题:Why Transformers Need Adam: A Hessian Perspective
作者:Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, Zhi-Quan Luo
机构:The Chinese University of Hong Kong、Shenzhen Research Institute of Big Data
原文链接:https://arxiv.org/abs/2402.16788
代码链接:https://github.com/zyushun/hessian-spectrum
1. 引言
Transformer模型[84]已成为人工智能发展的主要驱动力。然而,对Transformer训练的理解仍然有限。例如,Transformer训练在很大程度上依赖于Adam优化器。相比之下,作为卷积神经网络(CNNs)的公认优化器,带有动量的随机梯度下降(SGD)在Transformer上的表现明显不如Adam。然而,这一性能差距背后的原因仍不清楚。理解为什么SGD在Transformer上的表现不如Adam是一个引人入胜的问题。首先,从理论角度来看,这有助于我们更好地理解Transformer乃至更广泛意义上的神经网络的训练。其次,从计算角度来看,这种理解可能会激发设计更好的神经网络训练算法的灵感。
在本研究中,我们通过Hessian矩阵的视角,探索了SGD在Transformer上表现远不如Adam的原因。我们首先研究了Transformer的完整Hessian谱,即Hessian矩阵的全部特征值密度。根据理论,完整的Hessian谱在很大程度上决定了基于梯度的方法的行为,因此我们怀疑它也可能有助于解释SGD表现不佳的原因。我们使用数值线性代数的工具,对SGD与Adam表现相当的CNN(卷积神经网络)和SGD远落后于Adam的Transformer的完整谱进行了实证比较。然而,尽管优化器行为不同,但CNN和Transformer的谱往往非常相似。因此,我们尚未在完整的Hessian谱中识别出与Transformer上Adam和SGD之间差距相关的关键特征。为了揭示原因,需要对Hessian进行更细致的研究。
为什么SGD在Transformer上的表现显著差于Adam,而在CNN上则不然?通过剖析CNN和Transformer的结构,我们注意到CNN是通过重复堆叠相似的参数块(卷积层)构建的,而Transformer则涉及不同参数块(如注意力层中的查询、键、值、输出投影块以及多层感知机(MLP)层)的非顺序堆叠。我们假设这些架构差异可能导致不同的优化特性。直观上,不同的参数块对整体损失的贡献不同,因此每个块都可能从优化器的专门处理中受益,这是Adam能提供而SGD不能的灵活性。这一观察促使我们研究每个参数块的Hessian谱,我们称之为块级Hessian谱。
通过检查块级Hessian谱,我们发现了SGD表现不佳的一个可能解释:Transformer固有的“异质性”。我们提供了实证和理论证据来支持这一解释。
2. 摘要
SGD在《Transformer》上的表现比Adam差很多,但原因仍不清楚。在这部作品中,我们通过Hessian的镜头提供了一种解释:(I) Transformer是“异质的”:跨越参数块的Hessian谱变化剧烈,这种现象我们称之为“块异质”;(ii)异质性阻碍SGD: SGD在解决区块异质性问题时表现不如Adam。为了验证(I)和(ii ),我们检查了各种变压器、CNN、MLPs和二次问题,发现SGD在没有块异构性的问题上可以与Adam表现相同,但是当异构性存在时,SGD表现比Adam差。我们最初的理论分析表明,SGD性能更差,因为它对所有块应用一个单一的学习率,这不能处理块之间的异质性。如果我们使用Adam中设计的坐标式学习率,这种限制可以得到改善。
3. 主要贡献
我们的贡献可以概括如下:
• 解释SGD在Transformer上表现不如Adam的原因。我们通过研究块级Hessian谱来解释SGD在Transformer上表现不佳的原因。首先,我们识别出一种称为“块异质性”的现象,它指的是不同参数块之间Hessian谱的巨大差异。在所有检查的Transformer中都观察到了这种块异质性,但在CNN中则没有。其次,我们验证了块异质性会阻碍SGD的性能。在各种Transformer、CNN和MLP中,我们展示了SGD在存在块异质性的问题上始终表现不如Adam,而在其他问题上的表现则相当。
• 二次模型上的理论结果。我们构建了具有和不具有块异质性的凸二次问题,并发现梯度下降(GD)在具有块异质性的问题上大大落后于Adam,但在其他问题上的表现则相当。我们的理论分析表明,在具有块异质性的二次问题上,GD可能比Adam慢。我们指出GD比Adam慢的原因在于它对所有块使用单一学习率。通过像Adam那样为不同块分配不同的学习率,可以减轻这一缺陷。
我们强调,我们不主张块异质性是Adam和SGD之间性能差距的唯一原因,但它至少是一个重要原因。我们既从实证上也从理论上验证了,在存在块异质性的情况下,SGD的表现不如Adam。
4. 完整的Hessian谱不够丰富
我们研究Transformer的全Hessian谱出于两个原因。首先,Hessian谱显著影响梯度方法的行为。其次,先前的研究表明,Hessian谱为神经网络现象提供了深入见解,如BatchNorm对训练速度的影响。因此,我们假设Hessian谱也可能解释为什么在Transformer上SGD远远落后于Adam。
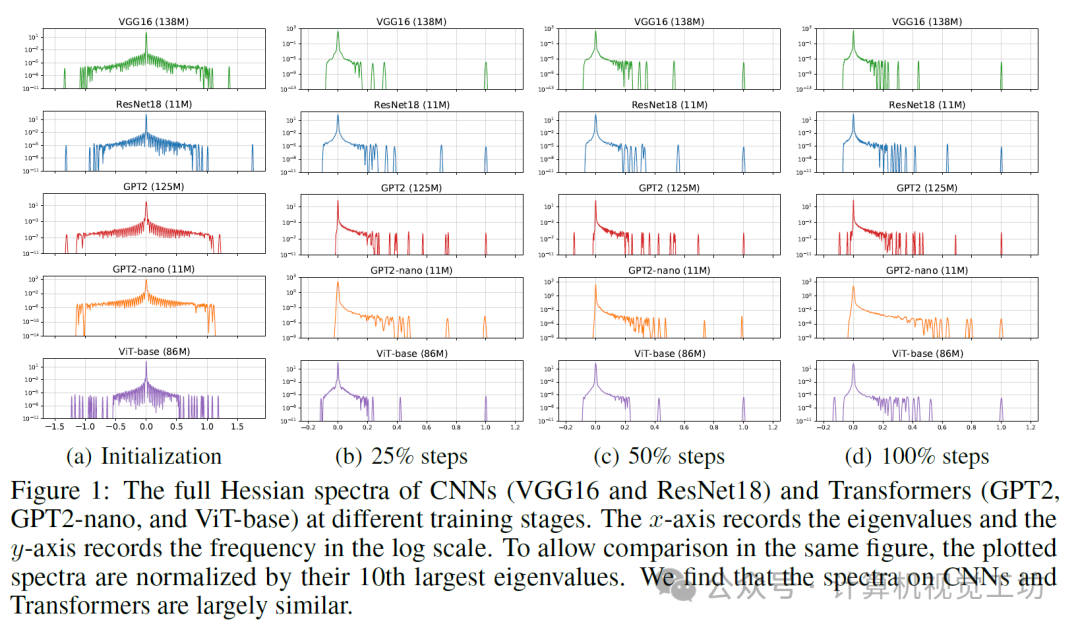
我们比较了卷积神经网络(CNN,其中SGD的表现与Adam相似)和Transformer(其中SGD的表现不如Adam)的全Hessian谱,如图1所示。不幸的是,结果表明,仅全Hessian谱可能不足以解释Transformer上Adam和SGD之间的差距。我们详细阐述如下。谱中的主要信息在于其(A)分散性,(B)形状,以及(C)训练过程中的演变。关于(A),我们观察到不同模型的特征值分散情况相似,Transformer中没有特别大的异常值。因此,分散性似乎与SGD为何不如Adam无关。我们进一步研究了(B)和(C)。对于图1中的所有CNN和Transformer,我们观察到类似的现象:在初始化时,谱的形状大致以0为中心对称。随着训练的进行,大多数负特征值消失,形状演变为“主体”和一些“异常值”的组合。由于Transformer和CNN的谱形状和演变都相当相似,因此它们也无法解释为什么SGD在Transformer上表现不如Adam。
综上所述,我们尚未在全Hessian谱中发现任何关键现象,这些现象可以与Transformer上Adam和SGD之间的性能差距相关联。
5.通过分块Hessian谱的主要发现
什么其他因素可能导致SGD在Transformer上表现显著差于Adam,但在CNN上则不然?我们识别出了一些在全Hessian谱分析中被忽视的关键特征。
Hessian结构。现有文献表明,多层感知机(MLP)的Hessian接近块对角矩阵[18, 73, 60]。此外,从理论上将块对角结构归因于(i)神经网络中的逐层设计和(ii)交叉熵损失。沿着这一工作路线,我们还观察到在图2中的小型Transformer中存在接近块对角的Hessian,其中每个主块中的变量对应于Transformer中每个块的参数。这些结果表明,接近块对角的Hessian在神经网络中可能是常见的。

Transformer的构建规则。如图3所示,CNN由相似参数块(卷积层)的重复堆叠构成。相比之下,Transformer由不同的参数块组成,如注意力机制中的Query、Key、Value和MLP层。此外,这些块以非顺序方式堆叠。由于这些块的设计不同,它们可能具有不同的优化特性,这可以进一步影响优化器的行为。

综合以上因素,我们假设分块Hessian谱,即Hessian[∇²L(w)]l的主块的谱,l ∈ [L],可能会提供额外的见解。分块谱中包含哪些在全谱中不包含的额外信息?根据定义,分块Hessian构成了全Hessian的主块子矩阵。我们注意到,Transformer被观察到具有接近块对角的Hessian。对于块对角矩阵,分块谱编码了特征值的位置,即全矩阵的一个特征值位于哪个块中。相比之下,全谱忽略了这一位置信息。在以下部分中,我们研究了各种模型的分块Hessian谱,并表明它们确实比全谱携带了更多用于区分CNN和Transformer的信息。
我们在这里展示了VGG16(CNN)和BERT(Transformer)的分块谱的形状。我们为每个模型采样了四个块,并在图3中展示了这些谱。在BERT中,嵌入、注意力和MLP块的Hessian谱差异很大。相比之下,在ResNet中,卷积层的谱是相似的。我们进一步验证了其余参数块的这一观察结果。我们计算了所有可能块对之间特征值密度的Jensen-Shannon(JS)距离,并在图4中展示了结果。
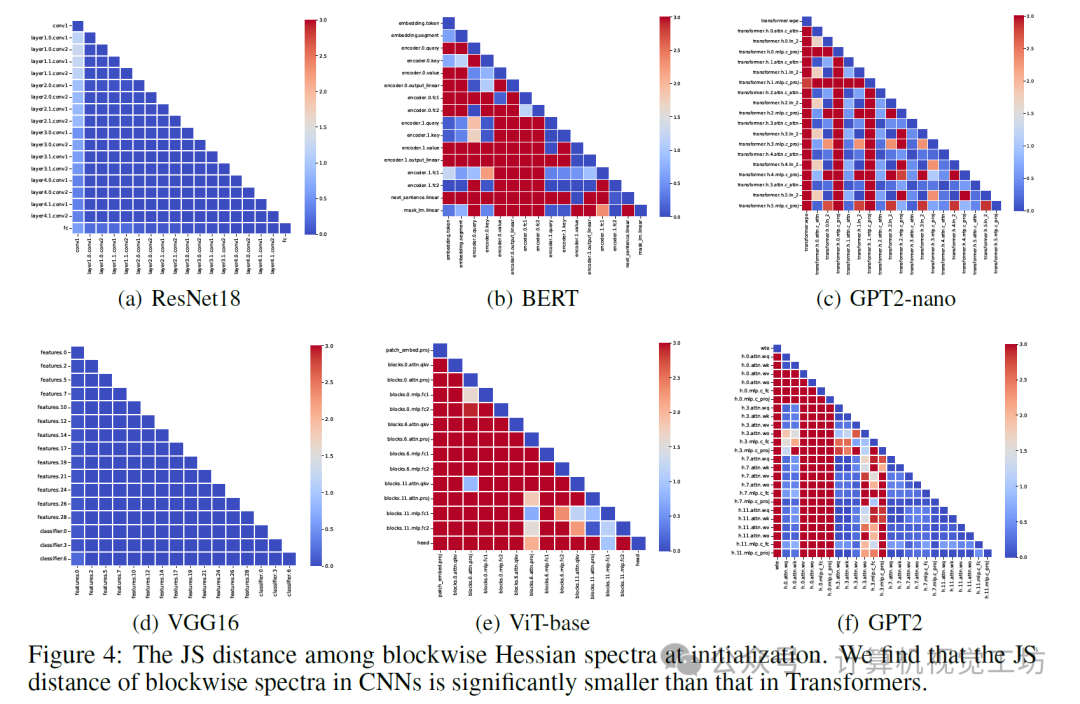
图4中的结果表明了一个新现象:在我们检查的所有Transformer中,分块Hessian谱在块之间差异很大。在以下部分中,我们将这一现象称为“块异质性”。相比之下,CNN的分块Hessian谱是相似的,并且没有观察到块异质性。我们将这一现象称为“块同质性”。这些结果表明,块异质性在区分CNN和Transformer方面是有信息的。直观上,CNN中的块同质性来自重复相似的卷积层,而Transformer中的块异质性则源于非顺序堆叠的不同层,如Query、Value和MLP。在以下部分中,我们将展示块异质性与Transformer上SGD和Adam之间的性能差距密切相关。
6. 在具有块异质性的各种任务上,SGD的表现不如Adam
图3和图4已经表明:(1)在Transformer上,SGD的表现不如Adam。(2)Transformer具有块异质性。现在我们进一步将块异质性与SGD在非Transformer模型上的不佳表现联系起来。这将直接在“块异质性”和“为什么SGD不如Adam”之间建立联系,而无需通过Transformer或注意力块作为中介。我们考虑了一个人为示例和一个现实世界示例。
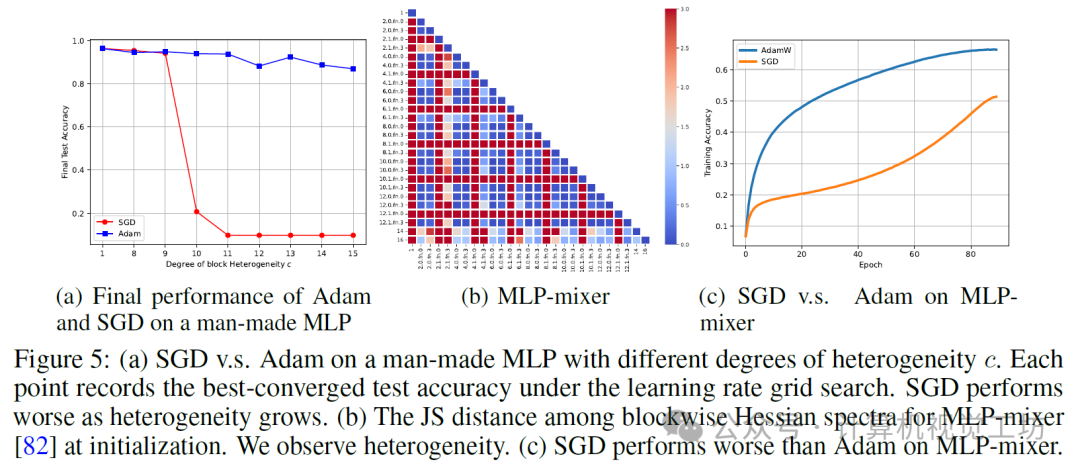
示例1:一个人为的MLP。我们在MNIST上考虑了一个4层的MLP,并通过用常数c缩放每一层来改变异质性的程度。图5(a)显示,随着异质性的增加,SGD逐渐表现不如Adam。
示例2:MLP-mixer。我们考虑了MLP-mixer[82],这是一种著名的全MLP架构,在某些视觉任务上优于CNN和ViT。图5(b)(c)显示,MLP-mixer的初始Hessian具有块异质性,并且SGD在该架构上落后于Adam。
7. 预训练Transformer中的块异质性降低
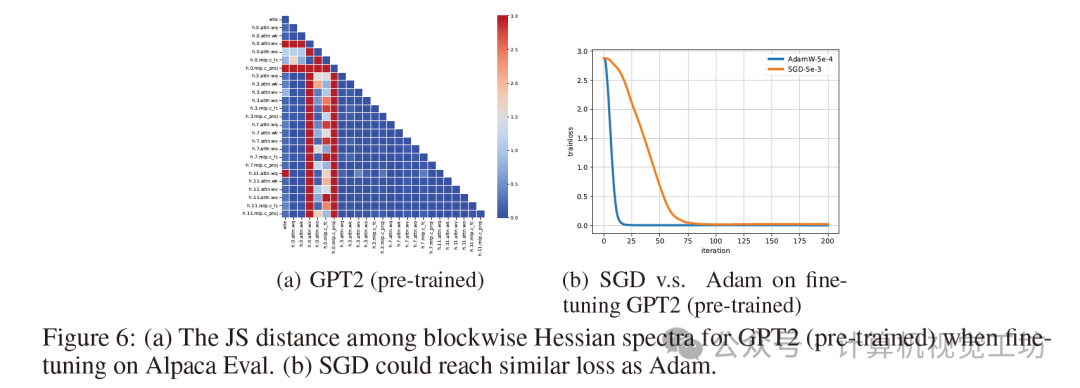
我们注意到,不同的Transformer表现出不同程度的块异质性。尽管所有检查的Transformer都显示出强烈的块异质性,但我们发现这种异质性可以得到缓解,从而导致SGD的性能下降减少。如图6所示,与从头开始预训练GPT2相比(图4(f)),在SFT任务上预训练的GPT2可以表现出较少的块异质性。在这种情况下,虽然SGD仍然比Adam慢,但它在收敛时达到了相似的损失。与从头开始训练GPT2相比,SGD和Adam之间的性能差距显著缩小。这些发现表明,由架构设计引起的异质性可以通过选择“良好”的权重来减轻。这部分解释了为什么像SGD甚至其零阶版本这样的更简单方法仍然可以有效地微调语言模型,尽管收敛速度较慢。
8. 总结 & 未来工作
在本文中,我们探究了为何在Transformer模型上,随机梯度下降(SGD)的表现远逊于Adam优化器。我们提出了一个现象,称为Hessian矩阵的块异质性,并将其与Adam和SGD之间的性能差距联系起来。我们提供了初步理论来支持这一观点。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~

















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









