






0. 论文信息
标题:Three Things to Know about Deep Metric Learning
作者:Yash Patel, Giorgos Tolias, Jiri Matas
机构:Czech Technical University in Prague
原文链接:https://arxiv.org/abs/2412.12432
1. 导读
本文研究了开集图像检索中的有监督深度度量学习,主要集中在三个关键方面:损失函数、混合正则化和模型初始化。在深度度量学习中,通过梯度下降来优化检索评估度量recall@k是合乎需要的,但是由于其不可微的性质而具有挑战性。为了克服这一点,我们提出了一个可微分的替代损失,这是计算大批量,几乎相当于整个训练集。通过绕过GPU内存限制的实现,这一计算密集型过程变得可行。此外,我们引入了一种有效的混合正则化技术,该技术对成对标量相似性进行操作,有效地进一步增加了批量大小。通过使用在大规模数据集上预先训练的基础模型初始化视觉编码器,进一步增强了训练过程。通过对这些组件的系统研究,我们证明了它们的协同作用使得大型模型几乎可以解决流行的基准测试。
2. 引言
深度度量学习(DML)是一种利用深度模型的表征学习任务,通常旨在通过非参数化(即最近邻)分类器实现检索或分类。对于检索任务,由于评估是在训练期间未见过的类别上进行的,因此将其视为开集任务。因此,要获得良好的性能(通过已建立的信息检索指标来衡量,如平均精度均值(mAP)或Recall@k),良好的泛化能力至关重要。由于特定领域的训练数据通常有限,因此正确初始化模型而非从零开始训练至关重要。本研究聚焦于图像DML,旨在弥合学习与评估目标之间的鸿沟,同时探索模型初始化的重要性。
在深度学习中,最小化作为测试时评估指标函数的损失已被证明对众多计算机视觉和自然语言处理任务有益。例如,将交并比(IoU)作为损失函数可以提升目标检测和语义分割的性能;结构相似性、峰值信噪比和感知损失作为图像压缩中的重建损失,根据相应的评估指标可以获得更好的结果。当评估指标不可微时,无法通过梯度下降在评估指标上训练深度网络。为解决此问题,现有的DML方法使用代理损失函数,如对比损失、三元组损失和边界损失。对于距离度量,这些损失函数鼓励将同类样本拉近,同时将不同类样本推开。作为可微函数,它们提供了一种折衷方案,虽然在经验上能取得合理性能,但可能与评估指标不完全一致,如图1所示。
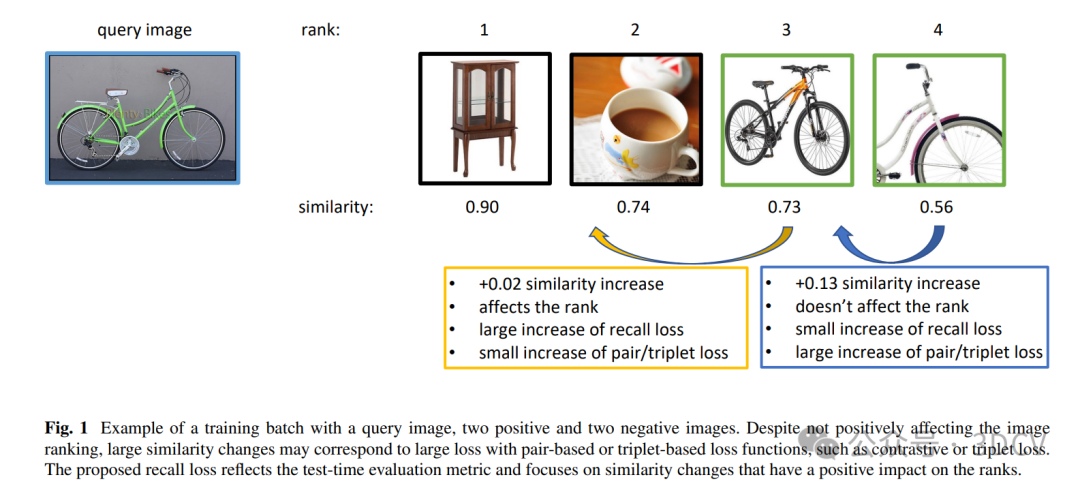
我们提出了一种Recall@k指标的手工设计平滑近似作为训练的替代函数,以及一种在图像间相似性空间中高效操作的mixup技术。图2展示了评估指标与所提损失之间的比较。对于不可微损失的通用训练方法,如行动者-评论家方法和学习替代方法,不适用于Recall@k。这是因为这些方法仅限于可分解函数,其中每个示例的性能度量是可用的。Engilberge等人曾尝试过这种方法,他们使用LSTM学习基于排序的度量,但由于训练缓慢,在后续工作中并未采用。

在各种DML基准测试中,通常使用基于ImageNet分类的预训练权重来初始化模型,而非因下游任务训练数据有限而从头开始初始化模型。近期关于视觉表征学习的文献在大规模预训练方面做出了重大努力,包括完全监督、弱监督或无监督预训练。这些预训练模型旨在实现有效的迁移学习,无论保持冻结还是微调。然而,它们对DML的影响仍在很大程度上未被探索。本研究调查了使用广为人知的大规模预训练方法成果来初始化模型的影响。

3. 主要贡献
本文是对我们先前工作的扩展,其贡献概述如下:
• 提出了一种新的损失函数,它是Recall@k的替代函数。为模拟测试时设置,我们借鉴先前工作的实现技巧,使用非常大的批量进行训练。
• 我们通过一种新的基于mixup的正则化技术进一步扩大了批量大小,该技术计算效率高,能够虚拟地扩大批量,而无需创建混合嵌入。其效率是通过在相似性估计的最后阶段(即标量相似性混合)上操作而获得的。
• 通过纳入广为人知的方法(即CLIP、DiHT、DINOv2、SWAG和在ImageNet-21k上的训练),探索了不同预训练作为模型初始化的影响。
• 我们使用公平的验证协议进行超参数调整,这在文献中并非标准做法。
• 我们使用大型骨干网络、强大的模型初始化和所提损失,在多个DML基准测试中取得了近乎完美的结果。
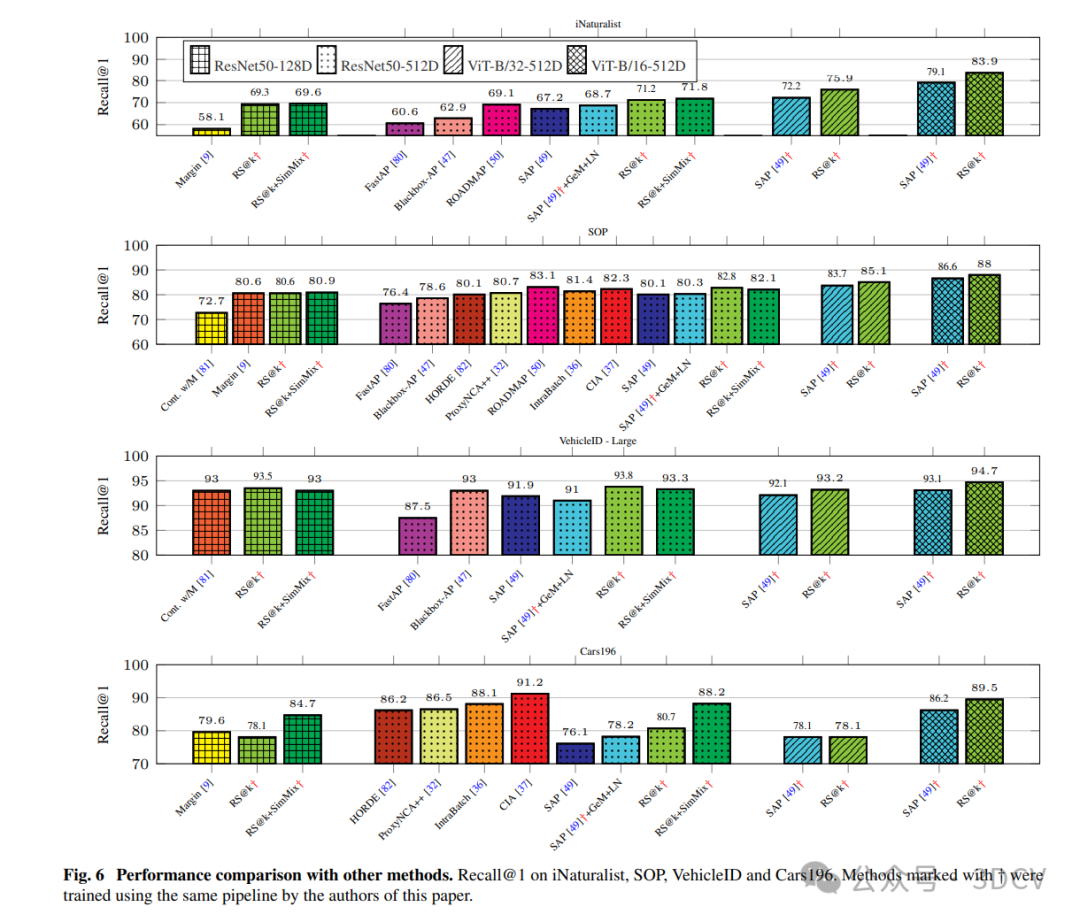
凭借上述贡献,我们在iNaturalist上实现了90.0%的Recall@1分数,在StanfordOnline-Products上实现了90.8%的Recall@1分数,在Cars196数据集上实现了97.2%的Recall@1分数。此外,我们在iNaturalist上实现了97.6%的Recall@16,在SOP上实现了97.7%的Recall@10,在Cars196上实现了99.3%的Recall@8,这表明在某些设置下,这些基准测试已近乎解决。我们希望本文中针对不同架构和初始化的多样化实验能为该领域的未来探索提供指导和基线。
4. 总结
本文提出了一种新颖的替代损失函数,用于使用召回@k指标进行深度度量学习的训练。需要大批量的数据,本文通过两种方式来解决这个问题:一是实现框架,该框架在很大程度上摆脱了硬件限制;二是提出的Sim-Mix,它有效地和虚拟地增加了批处理大小。在多个标准的深度度量学习和实例级搜索基准上取得了最先进的结果,使用了不同的骨干。使用最近大规模培训前方法的模型初始化,进一步提高了结果,使一些基准似乎几乎得到解决。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









