







 文章介绍了NICE-SLAM在实时场景重建中的创新,特别是其采用的多层网格特征,解决了传统方法和学习方法的局限。通过分层表示场景,NICE-SLAM提高了对大场景和空洞的处理能力。此外,还涉及了优化方法、跟踪与建图策略,以及对动态物体的鲁棒性处理。
文章介绍了NICE-SLAM在实时场景重建中的创新,特别是其采用的多层网格特征,解决了传统方法和学习方法的局限。通过分层表示场景,NICE-SLAM提高了对大场景和空洞的处理能力。此外,还涉及了优化方法、跟踪与建图策略,以及对动态物体的鲁棒性处理。
前言
论文看到一半的时候给别人安利,突然被问起这篇文章创新点是什么,我竟然答不出来,又看了个寂寞,于是写下这篇总结。参考 https://zhuanlan.zhihu.com/p/582821039
论文阅读
Nice-slam的四个目标
- 实时
- 合理预测:传统方法无法做到
- 大场景有效:iMAP或是learning-based方法均未能实现的
- robust(同2):对nosie和未观测到的位置鲁棒
总之就是传统方法+learning-based方法+最新的iMAP都只做到了以上的一项或几项,都没我考虑的全面
创新点
multilevel grid-based features(基于网格的多层特征):替换了iMAP中的单层MLP,分为四个部分表示场景结构。局部特征网格能够保留更多的几何细节,并表示更大的场景,此外,还可以对空洞进行预测。而iMAP中的单层MLP表示整个场景,会被不断地全局更新(换句话说:MLP更倾向于学习后来的数据),导致其不仅不能预测空洞还不能表示大场景。
最大的创新点应该就是这个,其余的是一些非常零散的idea,比如:优化方法,如何mapping和tracking,如何加速训练,联合训练+分层训练,nerf采样方法等等。(纯属个人理解)
NICE-SLAM相当于采用了三维栅格地图,每个栅格保存局部的特征,用decoder将特征解码即可恢复出场景,因此即使场景面积很大也不存在网络遗忘的问题。
方法
Section3.1 Hierarchical Scene Representation
这章介绍encoder(feature grid)和decoder(MLP),也是最核心的内容。从左向右看,分别是MLP和feature grid。
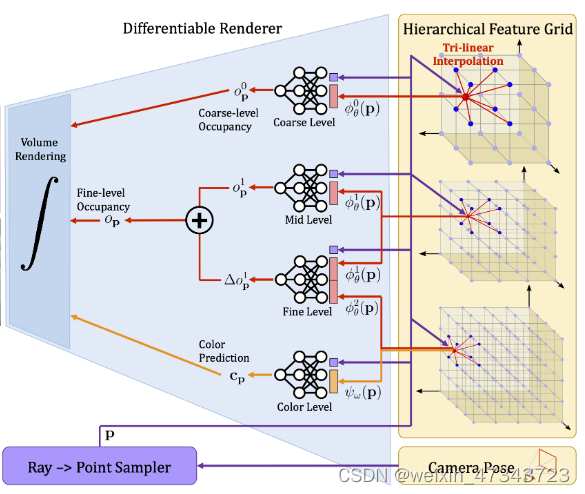
从上向下看,有四个部分——前三部分预测几何信息,第四部分预测颜色:
- coarse-level:为提升效率,gird采样块大且独立出来,用于预测(填补空洞,比如:地板墙面)。
- mid-level+fine-level:先经过mid-level预测出一个占用率o,使用fine-level预测出 Δ \Delta Δo,两者相加得到最终的占用率。从图中可以看到fine-level的输入是小网格+小小网格。
- color level:与前三层最大的不同在于,color-level的decoder和encoder都在更新,而前三层固定了MLP只更新特征网格,这样做有助于大场景的构建,MLP不会被新的特征影响。此处MLP是CNN+MLP预训练后,单独取MLP出来获得的。因此,color-level就会存在颜色被更新的问题,构建大场景时就不能有颜色信息了(我猜)。
Section3.2 Depth and Color Rendering
这章介绍如何通过nerf方法获得depth&color (使用已估计出的相机外参??这里没懂怎么得到的)
对于一条光线,使用分层和均匀采样一个得到N个点,对于这N个点都估计出一个权重wi(表示光线到i终止的概率),显然概率越大,这一点越容易是物体。coarse层和fine层的权重如下:


由权重可以获得渲染后的深度值和颜色值:
 其中,di是采样点到原点的距离。进一步地,还可以求出沿光线方向的深度方差(后续用到):
其中,di是采样点到原点的距离。进一步地,还可以求出沿光线方向的深度方差(后续用到):
Section3.3 Mapping and Tracking
这章介绍基于hierarchical scene representation和相机位姿的参数 θ \theta θ和 ω \omega ω的优化。(损失函数)
Mapping(建图)
建图阶段包含两个loss:
几何loss

光度loss

通过从当前帧和关键帧中均匀采样共M个像素,最小化loss。优化顺序如下:
1.使用
L
f
g
L{f \atop g}
Lgf优化mid-level feature grid
ϕ
1
θ
\phi{1 \atop \theta}
ϕθ1
2.使用
L
f
g
L{f \atop g}
Lgf优化mid-level和 fine-level feature grid
ϕ
1
θ
\phi{1 \atop \theta}
ϕθ1,
ϕ
2
θ
\phi{2 \atop \theta}
ϕθ2
3.使用local bundle adjustment(BA 局部约束调整)联合优化所有level的grids,color decoder,相机外参{Ri, ti}在第K个关键帧处。使用如下公式。

作者讲了这样做的原因:外分辨率的外观和fine-level都依赖于Mid-level所以先优化mid能够加快收敛。此外,使用并行三个线程加速优化过程:coarse-level,mid+fine+color,tracking(下个步骤)。这里难道不是下一阶段依赖上一阶段的优化结果吗?为什么可以并行优化呢?还是说先优化1,再根据1优化2,但1会进行到下一步?
Tracking(追踪)
如果说mapping阶段是优化scene representation,那tracking阶段就是优化当前帧的camera poses,即{R, t}。同样地,在当前帧中采样Mt个像素点使用如下loss:

其中,对几何损失做了修改,修改的Lg_var如下:

作者说使用Lg_var的好处是The modified loss down-weights less certain regions in the reconstructed geometry [46, 62], e.g., object edges. 修改后的loss降低了重建场景中不确定区域的权重。这里也没搞清楚原因
Robustness to Dynamic Objects:
当场景中出现动态物体时,NICE-SLAM可以通过过滤像素点来忽略这个动态物体,因为在动态物体上采样得到的像素点loss值(公式12)会很大。这里的loss中的 θ \theta θ和 ω \omega ω是已经优化的吗?
Keyframe Selection:
没看懂
实验
数据集(5个):Replica, ScanNet, TUM RGB-D Co-Fusion
Baseline:
| 名称 | 年份 | 分类 |
|---|---|---|
| TSDF-Fusion [11] | 1996 | |
| DI-Fusion [16] | 2020 | |
| iMAP [46] | 2021 | |
| BAD-SLAM[42] | 2019 | |
| Kintinuous[59] | 2012 | |
| ORB-SLAM2[16] | 2016 |
训练自己的数据集
1. Dataset文件夹下新建自己的数据集,包括:rgb和对应的深度图,名字对应上。
2. 在/utils/datasets.py文件下加入如下代码
# 第1步:创建自己的类
class Cube(BaseDataset):
def __init__(self, cfg, args, scale, device='cuda:0'
):
super(Cube, self).__init__(cfg, args, scale, device)
self.color_paths = sorted(
glob.glob(os.path.join(self.input_folder, 'rgb', '*.bmp'))) #此处设置数据格式
self.depth_paths = sorted(glob.glob(os.path.join(
self.input_folder, 'depth', '*.npy')))
self.n_img = len(self.color_paths)
self.load_poses(os.path.join(self.input_folder, 'trajectories'))
# 此处抄袭CoFusion数据集的代码,因为没有轨迹数据,所以这里其实是无效的,但为了与其他数据集对应,不得不多写上
def load_poses(self, path):
# We tried, but cannot align the coordinate frame of cofusion to ours.
# So here we provide identity matrix as proxy.
# But it will not affect the calculation of ATE since camera trajectories can be aligned.
self.poses = []
for i in range(self.n_img):
c2w = np.eye(4)
c2w = torch.from_numpy(c2w).float()
self.poses.append(c2w)
# 第2步:将自己的类加入dict中
dataset_dict = {
"replica": Replica,
"scannet": ScanNet,
"cofusion": CoFusion,
"azure": Azure,
"cube": Cube, # 自己的类
"tumrgbd": TUM_RGBD
}
# 第3步:修改基类BaseDataset的depth读取方式
# 77行
def __getitem__(self, index):
color_path = self.color_paths[index]
depth_path = self.depth_paths[index]
color_data = cv2.imread(color_path) # torch.Size([480, 640, 3])
if '.png' in depth_path:
depth_data = cv2.imread(depth_path, cv2.IMREAD_UNCHANGED)
elif '.exr' in depth_path:
depth_data = readEXR_onlydepth(depth_path)
elif '.npy' in depth_path: # 如果自己的depth格式与以上提供的均不同
depth_data = np.load(depth_path)
# 92行自己决定要不要注释掉 color_data = cv2.cvtColor(color_data, cv2.COLOR_BGR2RGB) # 转换图像颜色空间
本人使用的是原图(.bmp)+深度图(.npy),或许还会出现其他错误,需根据报错提示修改。
3.修改\configs下的.yaml文件
建立自己的文件夹,下面包含场景.yaml和数据集.yaml两个文件
场景.yaml文件:
inherit_form:指向数据集.yaml路径
data:数据读取和输出路径
cam:更换一系列内参
数据集.yaml文件:
dataset:刚刚所建立的字典的Key
mesh_freq: 生成mesh的频率
一些理解(Update 4.27)
关于场景表示
imap使用的是MLP来存储整个场景,这种方式的劣势首先是会受到后续输入数据的影响,引起MLP的遗忘问题,导致无法表示大场景。nice-slam重新创建出的一种表示方式——使用feature_grid(以下简称c)存储整个场景,最大的优势就是能够存储大场景,但这种方式也不完全属于显示表示,不过趋向于显示表示是否是未来基于nerf的slam方法的发展趋势呢?从结果来看,c这种表示方式确实会忽略掉一些细节,不过也很可能是loss函数定义的问题,更新时间也非常慢,这里暂不深究。
此外,在nicer-slam中替换掉了c,而使用SFD表示,具体文章还没有详细看,不过从空间和时间上,如何找到新的表示方式替换掉c确实是个大问题,即:使用更少的时间更新场景表示 or 更少的存储空间存储场景(两者其实并不冲突,毕竟计算量小更新时间自然就上去了)。
信息记录
NICE_SLAM.py文件中,在几个线程之间共享内存的变量
self.estimate_c2w_list #估计的位姿列表
self.gt_c2w_list # 位姿的GT列表
self.idx # 由tracker最后一帧更新 5,
self.mapping_first_frame #
self.mapping_idx # 最新的mapping idx (Replica 0, 5, 10)
self.mapping_cnt # ? counter for mapping(0, 1, 2, 3...)
self.shared_c # 存储特征网格
Mesher.py文件记录
如何由feature_grid获得对应的mesh?通俗来说,怎么把隐式表示转换为显示呢? 该函数的调用在Mapper.py中约789行
self.mesher.get_mesh(mesh_out_file, self.c, self.decoders, self.keyframe_dict, self.estimate_c2w_list, # 文件名 特征网格 MLP 关键帧 估计位姿
idx, self.device, show_forecast=self.mesh_coarse_level, # 索引值 cuda:0 False
clean_mesh=self.clean_mesh, get_mask_use_all_frames=False) # True Flase
对于每个输入参数的记录如下:
mesh_out_file output/Replica/office2/mesh/00005_mesh.ply
self.c {'grid_middle': tensor([[[[[ 3.4893e...='cuda:0'), 'grid_fine': tensor([[[[[ 3.2249e...='cuda:0'), 'grid_color': tensor([[[[[ 4.5727e...='cuda:0')}
self.decoders 4个MLP(coarse middle fine color)
self.keyframe_dict [{'gt_c2w': tensor([[ 7.0276e-01...000e+00]]), 'idx': tensor(0, dtype=torch.int32), 'color': tensor([[[0.8314, 0....h.float64), 'depth': tensor([[2.7276, 2.7... 1.1589]]), 'est_c2w': tensor([[ 7.0276e-01...='cuda:0')}]
self.estimate_c2w_list torch.Size([2000, 4, 4])
idx 当前mapper索引
show_forecast False
clean_mesh True
get_mask_use_all_frames False
过程如下:
- 由配置文件中的Bound和分辨率参数生成网格
grid = self.get_grid_uniform(self.resolution) - 调用open3d函数,由keyframe中的depth和rgb生成mesh,再由mesh获得包裹(包裹的含义如图所示)。生成包裹的目的是产生mask。
mesh_bound = self.get_bound_from_frames( keyframe_dict, self.scale)

- 由是否在包裹内生成mask;将网格的每个顶点和c一起输入到MLP中获得occ,特别注意的是:这里的points对应于当初的采样点,即:每个grid的顶点都对应于当初ray上每个采样点,相当于对网格上每个点进行一次深度的估计。
for i, pnts in enumerate(torch.split(points, self.points_batch_size, dim=0)):
mask.append(mesh_bound.contains(pnts.cpu().numpy()))
mask = np.concatenate(mask, axis=0)
for i, pnts in enumerate(torch.split(points, self.points_batch_size, dim=0)):
z.append(self.eval_points(pnts, decoders, c, 'fine', device).cpu().numpy()[:, -1])
- 根据深度生成volume,再从volume生成mesh
verts, faces, normals, values = skimage.measure.marching_cubes( # 查找3D体积(volume)中提取2D曲面(mesh)
volume=z.reshape( # 参数1: 3D体积 (M, N, P) array 把深度z转为网格的形状
grid['xyz'][1].shape[0], grid['xyz'][0].shape[0],
grid['xyz'][2].shape[0]).transpose([1, 0, 2]),
level=self.level_set, # 参数2: 等高线值 float
spacing=(grid['xyz'][0][2] - grid['xyz'][0][1], # 参数3:(M, N, P)对应的体素间距 体素的物理空间大小
grid['xyz'][1][2] - grid['xyz'][1][1],
grid['xyz'][2][2] - grid['xyz'][2][1]))
# return:
# verts---(N, 3)形状的网格顶点的空间坐标
# faces---(M, 3)形状的整数数组,表示三角面的索引。每个三角形由三个顶点组成,每个顶点由其在verts中的索引表示
# nornals---(N, 3)形状的浮点数数组,表示曲面每个点的法向量
# values---(N,)形状的浮点数数组,表示曲面每个点的值。这里的值通常与体积数据相关
- 根据verts和faces生成mesh,并根据mesh中的点、关键帧、位姿等信息从三角网格中移除被遮挡的面
# verts是由mesh生成的点,把点转到世界坐标系下
vertices = verts + np.array([grid['xyz'][0][0], grid['xyz'][1][0], grid['xyz'][2][0]])
# 从三角网格中移除被遮挡的面
seen_mask, forecast_mask, unseen_mask = self.point_masks(...)
mesh.update_faces(~face_mask)
- 筛选组件
# spilt()方法将网格分解为多个组件,参数用于指示是否仅返回完全封闭的组件
components = mesh.split(only_watertight=False)
# 筛选每个area>0.2的组件,并组合在一起
new_components = []
for comp in components:
if comp.area > self.remove_small_geometry_threshold * self.scale * self.scale:
new_components.append(comp)
mesh = trimesh.util.concatenate(new_components)
vertices = mesh.vertices
faces = mesh.faces
- color阶段(为mesh上色):由上面得到的mesh点,进一步输入到color层的MLP中得到每个点对应的RGB值
vertex_colors。由以下代码获得最终的mesh
mesh = trimesh.Trimesh(vertices, faces, vertex_colors=vertex_colors)
总结: mesh经历了几个阶段的变换:
- 正方体grid (
points) +feature_grid输入到MLP预测occ(z),由occ(z)生成等高线得到新的点和面(verts,faces),将verts转为世界坐标系(‘vertices’),并根据点和面获得 mesh1 - 从三角网格中移除被遮挡的面,并筛选其中符合要求的组件,获得mesh2
- 为mesh2上色:把mesh2的点继续输入到color_MLP里,获得每个点的RGB值,获得mesh3
Evaluation
Metrics有:accuracy,completion,completion ratio,Depth L1 ,这里需要注明几点:
1.前三个指标均在replica数据集上使用,ScanNet数据集不适用,作者给出的原因如下:

2. 单位都是cm,包括后续的ATE RMSE
3. 这里的GT_mesh一定要选择不带后缀的场景,即:room0.ply而不是room0_mesh.ply
在进行测评之前,需要先把两个mesh转为点云,并对两个点云进行简单的ICP配准(这一步可能会让结果提升1左右)。在每个点云上均匀采样20w个点,计算:
accuracy指标:
使用KDTree搜索距离gt的最近的目标点云,并对距离求均值
completion指标:
使用KDTree搜索距离目标点云的最近的gt,并对距离求均值
completion ratio指标:
使用KDTree搜索距离目标点云的最近的gt,并对其中<0.05的距离求百分比
Depth L1指标:
随机生成一个位姿,渲染该位姿下的rec_mesh和gt_mesh,得到两幅深度图并做L1 Loss


















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









