






NHANES数据库分析,一步一个坎。常规分析小半年,现在半天全部搞定!
标准的NHANES数据库分析步骤,包括数据下载整合——数据清洗——数据加权分析三步,可以说各有各难点。
为了教大家如何用NHANES数据库,顺利完成一篇SCI论文,我们将推出"半天完成一篇NHANES数据库SCI论文“系列文章,手把手带你快速搞定分析!
本文是系列文章的第二篇:如何10分钟完成NHANES数据的清洗工作!

常规NHANES数据库数据清洗

按照常规的NHANES分析流程,在我们从官网下载一堆xpt格式文件后,需要修改变量名,合并不同数据集并进行数据纳排处理!
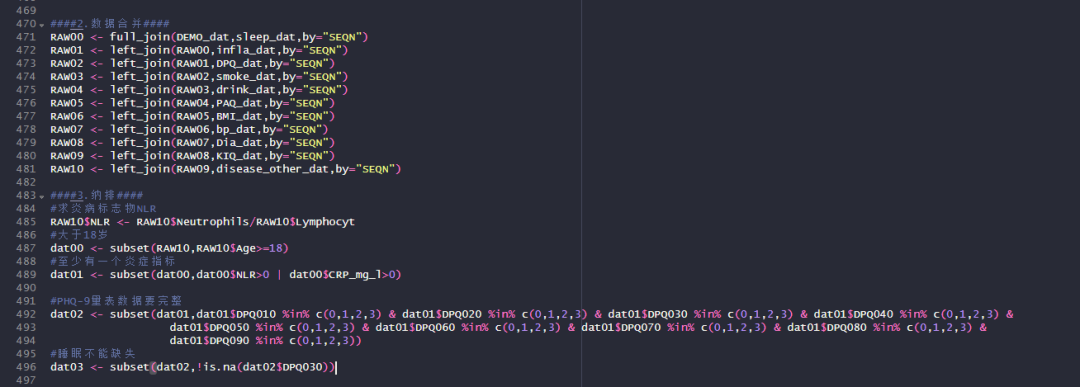
但是郑老师开发的一站式NHANES数据下载与分析平台,选择变量后直接整合为数据集,大大减少了数据清洗的工作量!
NAHNES数据下载别浪费时间在xpt文件了!换个工具,下载整合一步到位!
因此,这里我们只需要根据研究目的,进行数据的纳排,筛选目标人群即可!
话不多说,下面带大家一起见证——10分钟搞定全部的数据纳排!

一站式NHANES数据库分析平台

由浙江中医药大学统计老师郑卫军主持的NAHNES一站式下载分析平台,从下载到统计分析,居然半天就能搞定!
✅数据实时更新!与官网保持一致!
✅基于R语言成熟R包开发,统计准确有保障!
✅中英文切换使用,简直小白救星!
✅全部菜单式零代码操作,上手嘎嘎快!
我们在前面完成第1步数据下载,第2步数据整合后,平台自动跳转到"数据纳排"界面。
纳排步骤:选中变量——添加纳排条件——更新数据——下载数据!
|
|
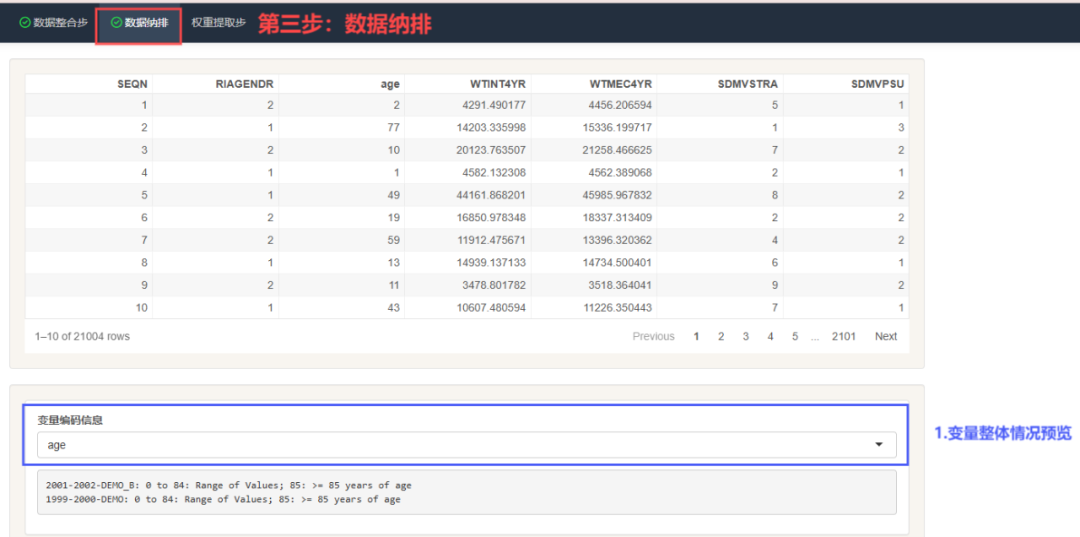
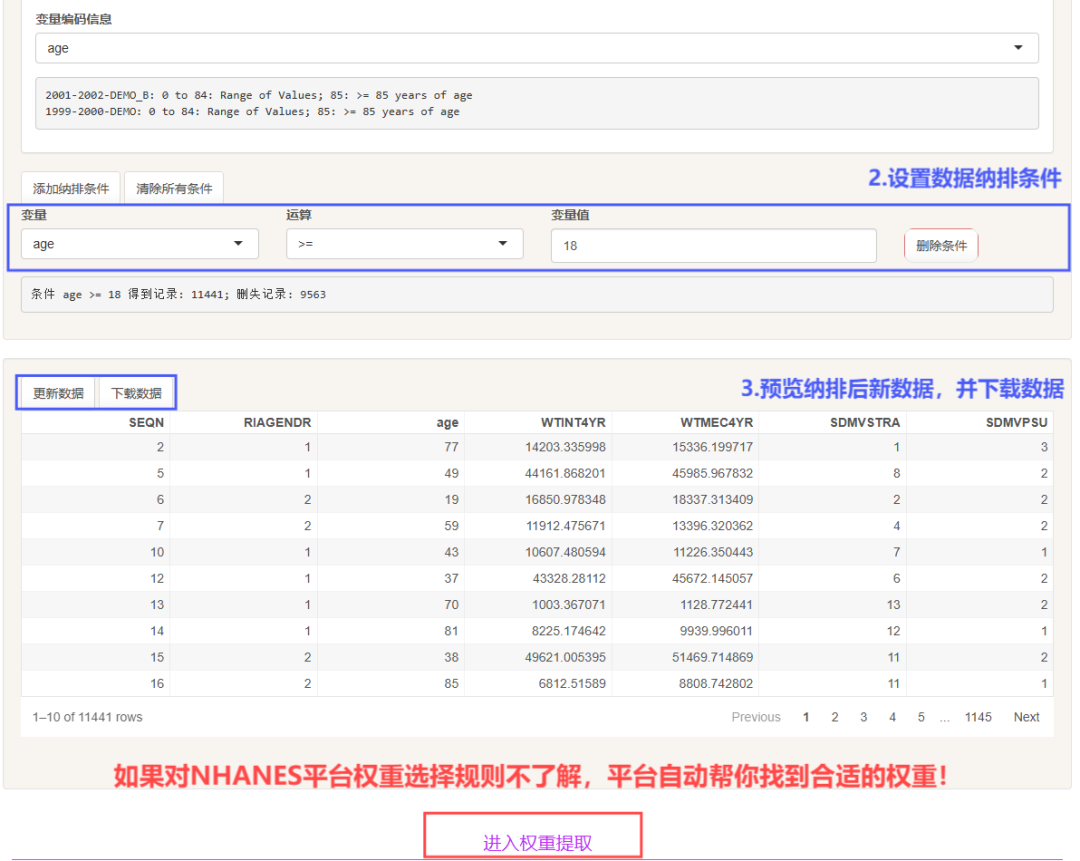
如果对NHANES分析权重的计算规则不了解,平台还会帮你一键计算权重,可以说是非常贴心了!
平台的纳排设置支持数值型变量大小的限定,以及定性变量的纳入与排出!
|
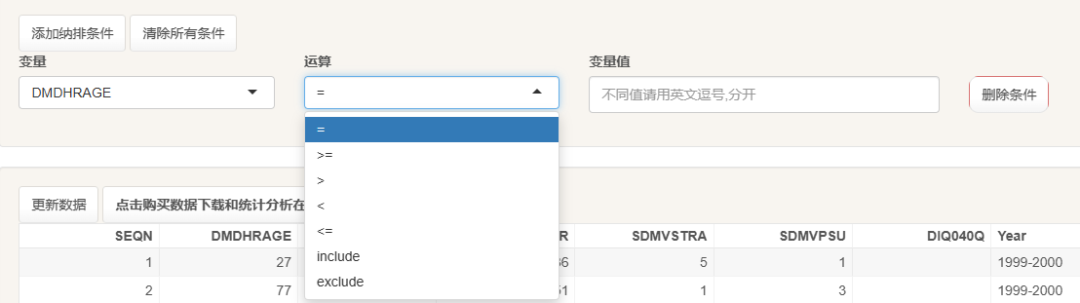
全部搞定后,就会得到一份带有指定权重的NAHNES数据集啦!变量均已合并整好,可以直接用于下一步分析!
|
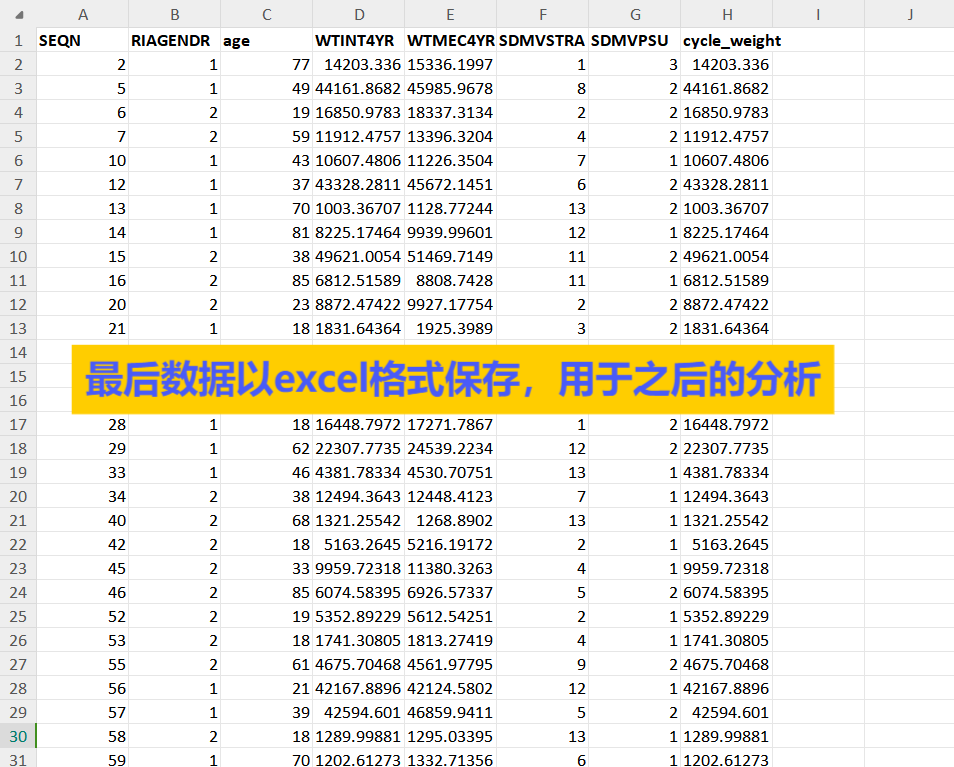
到这里,我们的的分析数据集就已经准备完毕。
我们下一篇继续为大家介绍NHANES数据加权分析,同样使用平台快速实现!大家敬请期待!
关于这个NHANES数据分析平台
俗话说”十年磨一剑“,经过长时间的打磨,郑卫军老师统计团队最终推出这个NHANES数据分析平台。解决了大家在挖掘过程中,NHANES数据库下载难、分析难等常见问题,助力大家更快完成一篇高质量文章!
如有对该平台感兴趣的学友,赶紧联系我们,早买早享受吧!
网站使用费用
本在线平台售价2000元/年
(有购买其它郑老师统计课程的学员享受9折优惠)
服务内容
✅买1年送1年,共2年的平台使用权限
✅平台后期会更新100多个NHANES综合性指标数据
✅提供1年期在线数据分析咨询
购买方式
可以添加下方助教微信咨询详情,或搜索微信号:aq566665。
可开技术服务费、培训费、咨询费等发票;可出具课程学习通知,方便报销,可以对公转账。

助教二维码,联系咨询

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









