







 文章介绍了预训练语言模型在下游任务精调时面临的计算和存储成本问题,并提出差值精调策略,包括Adapter方法、PromptTuning和PrefixTuning,以及利用低秩近似方法LoRA来减少资源消耗和提升训练效率。
文章介绍了预训练语言模型在下游任务精调时面临的计算和存储成本问题,并提出差值精调策略,包括Adapter方法、PromptTuning和PrefixTuning,以及利用低秩近似方法LoRA来减少资源消耗和提升训练效率。
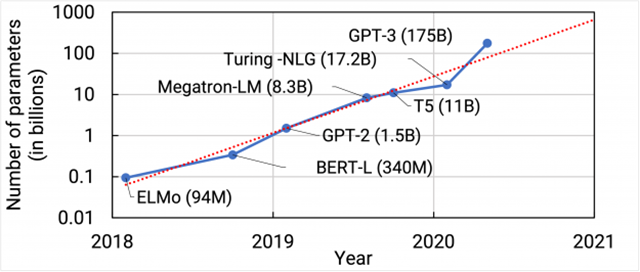
随着预训练语言模型规模的快速增长,在下游任务上精调模型的成本也随之快速增加。这种成本主要体现在两方面上:一,计算开销。以大语言模型作为基座,精调的显存占用和时间成本都成倍增加。随着模型规模扩大到10B以上,几乎不可能在消费级显卡或者单卡上进行训练;二,存储开销。如果对于每一个下游任务,我们都需要精调全量模型并存储相应的参数,那么所需要的存储开销也是相当惊人的。以GPT-3 175B为例,为仅仅一个任务存储精调模型的全量参数就需要350/700GB(取决于精度)。因此,如何在兼顾精调的表现的同时提升效率,是一个重要的研究问题。
本篇文章将介绍差值精调策略(delta tuning)。这类方法的核心思路是,通过只训练少量参数,并冻结其他模型参数,逼近甚至达到全量参数精调的效果。具体而言,现有的主流方法可以总结为三类:添加参数方法(addition-based),限制参数方法(Specification-based)和重参数化方法(reparameterization-based)。
一、添加参数方法
1.1 Adapter方法
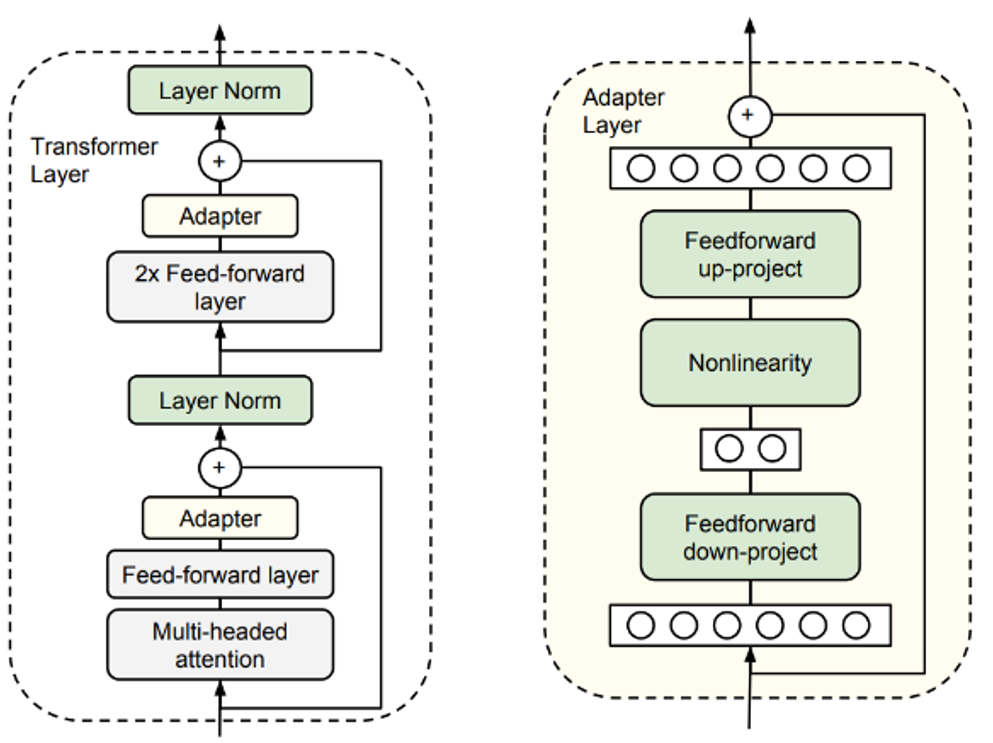
Houlsby et al.[1]最早提出了adapter方法,即在语言模型的每个transformer层中添加少量可学习的参数,并冻结其余参数,如图所示。为了减少参数量,作者采用了两层FFN作为adapter的网络结构进行降维-升维。为了使得初始化结果等价于原始网络,作者采用了残差连接并零初始化adapter结构。实验表明,在多项任务上,仅使用0.5%-8%的训练参数就能逼近全量参数精调的效果,并且训练速度能提升约60%。需要注意的是,由于引入了串行的额外模块,模型的推理速度会略微下降4%-6%。
1.2 连续化提示学习
1.2.1 Prompt tuning[2]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









