






目录
1 transformers框架
1.1 transformers框架+BF16+1张RTX4090 GPU(51.52 token/s)
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.cuda.empty_cache()
# 加载本地模型和 tokenizer
model_path = "/root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, trust_remote_code=True).cuda()
# 构建对话消息
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
input_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.cuda()
# 记录开始时间
start_time = time.time()
# 生成文本
output = model.generate(input_ids, max_new_tokens=512, do_sample=True, top_p=0.85, temperature=0.35)
# 解码生成的文本
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 记录完成时间
completion_time = time.time() - start_time
# 计算生成的新 token 数量
num_new_tokens = output.shape[1] - input_ids.shape[1]
# 计算 token 生成速度
token_speed = num_new_tokens / completion_time if completion_time > 0 else float('inf')
# 提取助手回复部分
response_start_index = output_text.find("assistant") + len("assistant")
response_text = output_text[response_start_index:].strip()
# 输出结果
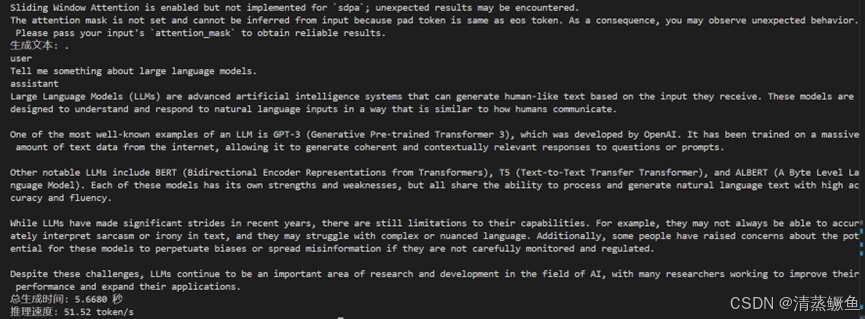
print(f"生成文本: {response_text}")
print(f"总生成时间: {completion_time:.4f} 秒")
print(f"推理速度: {token_speed:.2f} token/s")
生成文本
Large Language Models (LLMs) are advanced artificial intelligence systems that can generate human-like text based on the input they receive. These models are designed to understand and respond to natural language inputs in a way that is similar to how humans communicate.
One of the most well-known examples of an LLM is GPT-3 (Generative Pre-trained Transformer 3), which was developed by OpenAI. It has been trained on a massive amount of text data from the internet, allowing it to generate coherent and contextually relevant responses to questions or prompts.
Other notable LLMs include BERT (Bidirectional Encoder Representations from Transformers), T5 (Text-to-Text Transfer Transformer), and ALBERT (A Byte Level Language Model). Each of these models has its own strengths and weaknesses, but all share the ability to process and generate natural language text with high accuracy and fluency.
While LLMs have made significant strides in recent years, there are still limitations to their capabilities. For example, they may not always be able to accurately interpret sarcasm or irony in text, and they may struggle with complex or nuanced language. Additionally, some people have raised concerns about the potential for these models to perpetuate biases or spread misinformation if they are not carefully monitored and regulated.
Despite these challenges, LLMs continue to be an important area of research and development in the field of AI, with many researchers working to improve their performance and expand their applications.
2 vLLM框架
vllm:高吞吐率且存储高效的大模型推理服务框架
2.1 vLLM框架+BF16+1张RTX4090 GPU(163.66token/s)
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
import time
model_dir="/root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct"
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Pass the default decoding hyperparameters of Qwen2.5-7B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model=model_dir, trust_remote_code=True)
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 记录推理开始时间
start_time = time.time()
# generate outputs
outputs = llm.generate([text], sampling_params)
# 记录推理结束时间
end_time = time.time()
# 计算生成的token数量
generated_tokens = sum(len(output.outputs[0].token_ids) for output in outputs)
# 计算推理时间和速度
inference_time = end_time - start_time
tokens_per_second = generated_tokens / inference_time if inference_time > 0 else 0
# 打印生成结果和推理速度
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
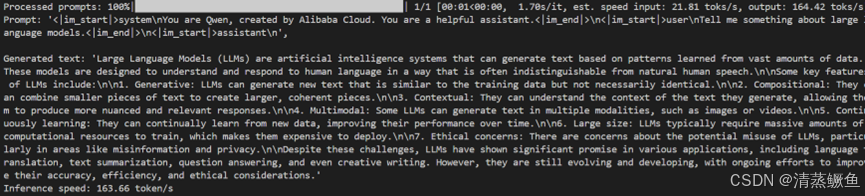
print(f"Prompt: {prompt!r},\n\nGenerated text: {generated_text!r}")
# 打印推理速度:token/s
print(f"Inference speed: {tokens_per_second:.2f} token/s")
输入输出文本
Prompt: '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\nTell me something about large language models.<|im_end|>\n<|im_start|>assistant\n',
Generated text: 'Large Language Models (LLMs) are artificial intelligence systems that can generate text based on patterns learned from vast amounts of data. These models are designed to understand and respond to human language in a way that is often indistinguishable from natural human speech.\n\nSome key features of LLMs include:\n\n1. Generative: LLMs can generate new text that is similar to the training data but not necessarily identical.\n\n2. Compositional: They can combine smaller pieces of text to create larger, coherent pieces.\n\n3. Contextual: They can understand the context of the text they generate, allowing them to produce more nuanced and relevant responses.\n\n4. Multimodal: Some LLMs can generate text in multiple modalities, such as images or videos.\n\n5. Continuously learning: They can continually learn from new data, improving their performance over time.\n\n6. Large size: LLMs typically require massive amounts of computational resources to train, which makes them expensive to deploy.\n\n7. Ethical concerns: There are concerns about the potential misuse of LLMs, particularly in areas like misinformation and privacy.\n\nDespite these challenges, LLMs have shown significant promise in various applications, including language translation, text summarization, question answering, and even creative writing. However, they are still evolving and developing, with ongoing efforts to improve their accuracy, efficiency, and ethical considerations.'
参数解释
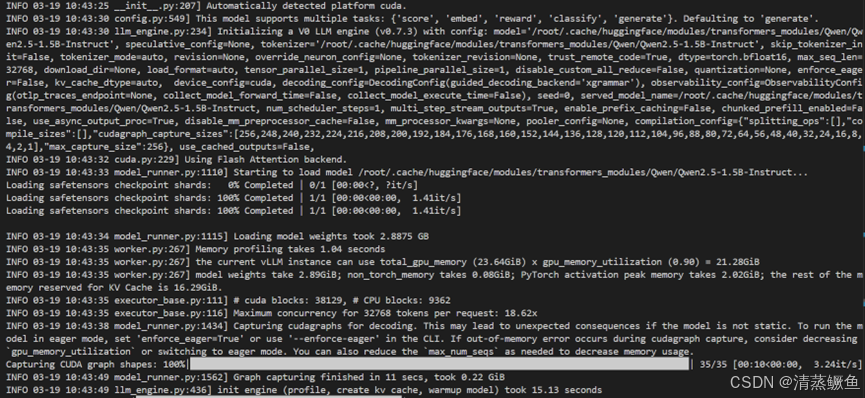
INFO 03-18 11:49:46 __init__.py:207] Automatically detected platform cuda.
- 自动检测到当前运行平台为 CUDA,意味着模型将利用 GPU 进行计算加速。
INFO 03-18 11:49:51 config.py:549] This model supports multiple tasks: {'embed', 'classify', 'reward', 'generate', 'score'}. Defaulting to 'generate'.
- 该模型支持多种任务,包括嵌入(embed)、分类(classify)、奖励计算(reward)、文本生成(generate)和评分(score),默认选择的任务是文本生成(generate)。
INFO 03-18 11:49:51 llm_engine.py:234] Initializing a V0 LLM engine (v0.7.3) with config: model='/root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct', speculative_config=None, ……max_capture_size":256}, use_cached_outputs=False,`
- 初始化一个版本为 0.7.3 的 LLM 引擎,配置信息包括使用的模型(Qwen2.5-1.5B-Instruct)、分词器、数据类型(torch.bfloat16)、最大序列长度(32768)、设备配置(CUDA)等。
INFO 03-18 11:49:53 cuda.py:229] Using Flash Attention backend.
- 使用 Flash Attention 后端,这是一种优化的注意力计算方法,可以提高计算效率。
INFO 03-18 11:49:54 model_runner.py:1110] Starting to load model /root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct...
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 1.37it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 1.37it/s]
- 开始加载 Qwen2.5-1.5B-Instruct 模型的检查点文件,加载过程从 0% 到 100% 完成,每秒处理 1.37 个检查点分片。
INFO 03-18 11:49:55 model_runner.py:1115] Loading model weights took 2.8875 GB
- 加载模型权重占用了 2.8875 GB 的内存。
INFO 03-18 11:49:56 worker.py:267] Memory profiling takes 1.13 seconds
- 内存分析耗时 1.13 秒。
INFO 03-18 11:49:56 worker.py:267] the current vLLM instance can use total_gpu_memory (23.64GiB) x gpu_memory_utilization (0.90) = 21.28GiB
- 当前 vLLM 实例可使用的 GPU 内存为总 GPU 内存(23.64GiB)乘以 GPU 内存利用率(0.90),即 21.28GiB。
INFO 03-18 11:49:56 worker.py:267] model weights take 2.89GiB; non_torch_memory takes 0.08GiB; PyTorch activation peak memory takes 2.02GiB; the rest of the memory reserved for KV Cache is 16.29GiB.
- 模型权重占用2.89GiB,非PyTorch内存占用0.08GiB,PyTorch激活峰值内存占用2.02GiB,剩余用于KV缓存的内存为16.29GiB。
INFO 03-18 11:49:56 executor_base.py:111] # cuda blocks: 38129, # CPU blocks: 9362
- CUDA 块数量为 38129,CPU 块数量为 9362。
INFO 03-18 11:49:56 executor_base.py:116] Maximum concurrency for 32768 tokens per request: 18.62x
- 每个请求32768个标记的最大并发度为18.62倍。
Capturing CUDA graph shapes: 100%|████████████████████████████████████████████████████████████████████████████████████████████| 35/35 [00:10<00:00, 3.26it/s]
- 捕获CUDA图形状的过程从0%到100%完成,共35个形状,每秒处理3.26个。
INFO 03-18 11:50:10 model_runner.py:1562] Graph capturing finished in 11 secs, took 0.22 GiB
- CUDA图捕获完成,耗时11秒,占用0.22GiB内存。
INFO 03-18 11:50:10 llm_engine.py:436] init engine (profile, create kv cache, warmup model) took 15.20 seconds
- 初始化引擎(包括性能分析、创建 KV 缓存和预热模型)总共耗时 15.20 秒。
Processed prompts: 100%|█████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.70s/it, est. speed input: 21.83 toks/s, output: 164.61 toks/s]
- 处理Prompt的进度为100%,共处理1个Prompt,每个Prompt平均耗时1.70秒,估计输入速度为每秒21.13个token,输出速度为每秒164.42个token。
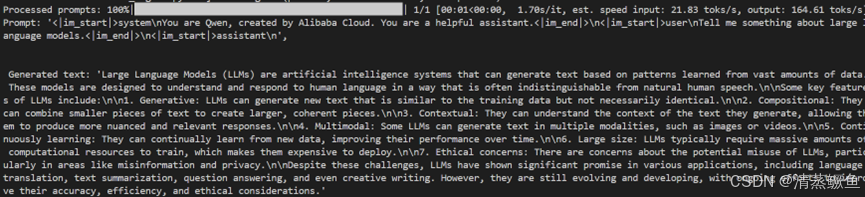
2.2 vLLM框架+BF16+2张RTX4090 GPU(122.08token/s)
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
import time # 导入时间模块
model_dir = "/root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct"
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Pass the default decoding hyperparameters of Qwen2.5-7B-Instruct
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model=model_dir, trust_remote_code=True, tensor_parallel_size=2)
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 记录推理开始时间
start_time = time.time()
# generate outputs
outputs = llm.generate([text], sampling_params)
# 记录推理结束时间
end_time = time.time()
# 计算生成的token数量
generated_tokens = sum(len(output.outputs[0].token_ids) for output in outputs)
# 计算推理时间和速度
inference_time = end_time - start_time
tokens_per_second = generated_tokens / inference_time if inference_time > 0 else 0
# 打印生成结果和推理速度
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r},\n\nGenerated text: {generated_text!r}")
# 打印推理速度:token/s
print(f"Inference speed: {tokens_per_second:.2f} token/s")
处理Prompt的进度为100%,共处理1个Prompt,每个Prompt平均耗时1.91秒,估计输入速度为每秒19.43个token,输出速度为每秒122.86个token。
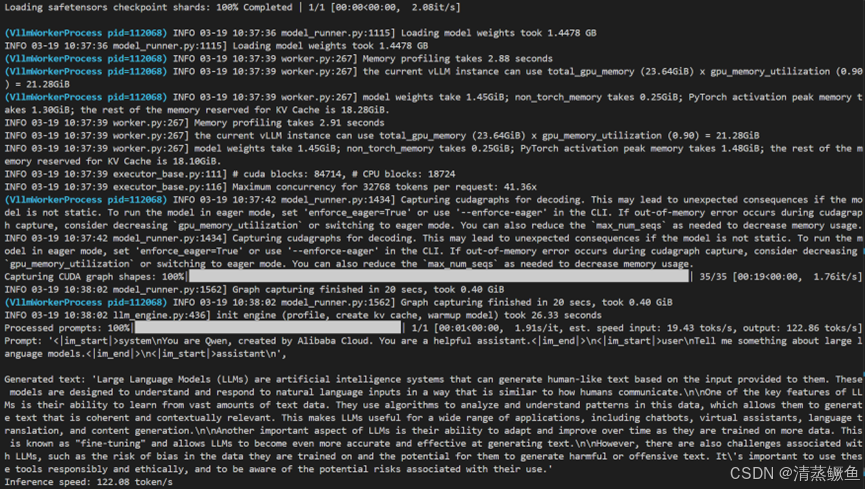
注:H800是有NVLink的通信快,4090卡间通信比较慢,2卡不一定快。
2.3 vLLM框架+AWQ +2张RTX4090 GPU(170.07 token/s)
安装AWQ:(但此处并不用,vllm本身支持awq)
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
import time # 导入时间模块
model_dir="/root/.cache/huggingface/modules/transformers_modules/Qwen/Qwen2.5-1.5B-Instruct-AWQ"
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Pass the default decoding hyperparameters of Qwen2.5-7B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model=model_dir, trust_remote_code=True, tensor_parallel_size=2, quantization="awq")
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 记录推理开始时间
start_time = time.time()
# generate outputs
outputs = llm.generate([text], sampling_params)
# 记录推理结束时间
end_time = time.time()
# 计算生成的token数量
generated_tokens = sum(len(output.outputs[0].token_ids) for output in outputs)
# 计算推理时间和速度
inference_time = end_time - start_time
tokens_per_second = generated_tokens / inference_time if inference_time > 0 else 0
# 打印生成结果和推理速度
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r},\n\nGenerated text: {generated_text!r}")
# 打印推理速度:token/s
print(f"Inference speed: {tokens_per_second:.2f} token/s")
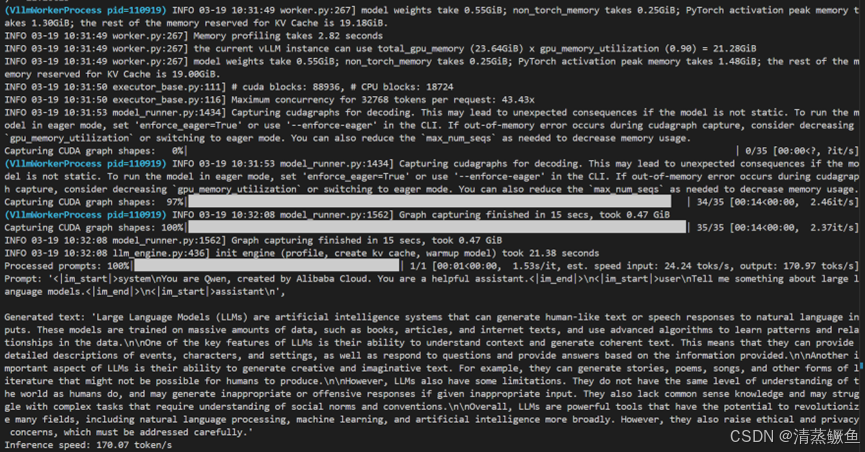
参考:https://qwen.readthedocs.io/zh-cn/latest/deployment/vllm.html

















 9280
9280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









