







 TransXNet是一种新型的CNN-Transformer混合视觉识别网络,通过双重动态Token Mixer(D-Mixer)和多尺度前馈网络(MS-FFN)解决了传统卷积的静态限制和特征融合挑战,提高表示能力,适用于图像分类、检测和分割任务。
TransXNet是一种新型的CNN-Transformer混合视觉识别网络,通过双重动态Token Mixer(D-Mixer)和多尺度前馈网络(MS-FFN)解决了传统卷积的静态限制和特征融合挑战,提高表示能力,适用于图像分类、检测和分割任务。

论文:https://arxiv.org/pdf/2310.19380
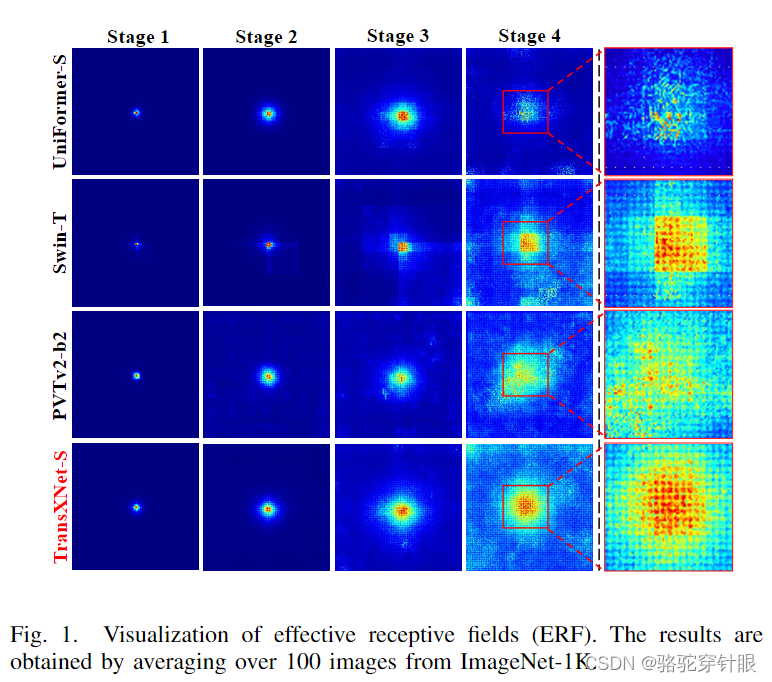
这篇论文试图解决什么问题?
这篇论文提出了一个名为TransXNet的新型混合卷积神经网络(CNN)和变换器(Transformer)的视觉识别架构,旨在解决以下问题:
卷积的静态性质限制:传统的卷积操作是静态的,无法根据输入的变化动态适应,这导致了卷积和自注意力(self-attention)之间的表示能力差异。自注意力能够动态计算注意力矩阵,而卷积核是输入独立的。
深度网络中的特征融合挑战:在构建深度网络时,通过堆叠包含卷积和自注意力的Token Mixer,卷积的静态性质阻碍了之前由自注意力生成的特征与卷积核的融合。
表示能力的次优:由于上述两个限制,现有网络的表示能力并不理想。
为了解决这些问题,论文提出了以下关键解决方案:
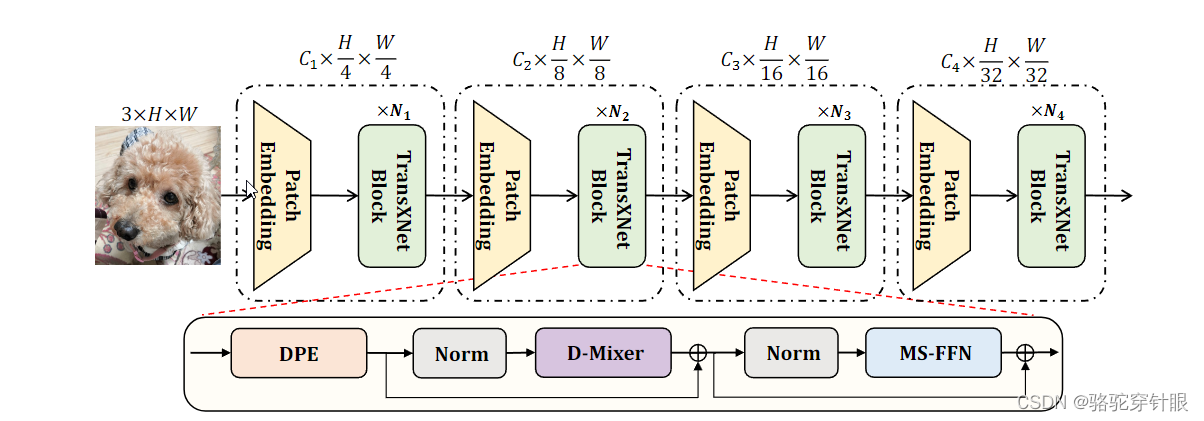
双重动态Token Mixer (D-Mixer):通过将输入特征分割并分别应用全局自注意力模块和输入依赖的深度卷积,以输入依赖的方式聚合全局信息和局部细节。
-
有效感受野的扩大:通过在所有阶段使用高效的全局自注意力机制,扩大了模型的有效感受野(ERF),并结合动态卷积进一步扩大了感受野。
-
TransXNet架构:使用D-Mixer作为基础构建块,设计了一种新的混合CNN-Transformer视觉主干网络,该网络在ImageNet-1K图像分类任务中取得了优异的性能,同时在计算成本上更具优势。
-
多尺度前馈网络 (MS-FFN):引入了一种新的前馈网络,用于在Token聚合过程中探索多尺度信息。
这些解决方案使得TransXNet在多个视觉任务中展现出强大的性能,包括图像分类、目标检测、语义分割和实例分割,同时保持较低的计算成本。
论文如何解决这个问题?
论文通过提出TransXNet架构来解决上述问题,具体解决方案包括以下几个关键组件:
-
双重动态Token Mixer (D-Mixer):D-Mixer是TransXNet的核心组件,它通过以下方式动态地聚合全局信息和局部细节:
-
输入分割:将输入特征图沿通道维度均匀分割为两个子特征图。
-
全局自注意力模块 (OSRA):对一个子特征图应用Overlapping Spatial Reduction Attention,以捕获全局上下文信息。
-
输入依赖的深度卷积 (IDConv):对另一个子特征图应用Input-dependent Depthwise Convolution,以引入归纳偏差并执行局部特征聚合。
-
特征图拼接:将OSRA和IDConv的输出沿通道维度拼接,然后通过Squeezed Token Enhancer (STE)进行高效的局部Token聚合。
-
有效感受野 (ERF) 的扩大:通过在网络的所有阶段使用全局自注意力机制,TransXNet能够有效地扩大模型的ERF,同时保持强大的局部敏感性。
-
多尺度前馈网络 (MS-FFN):MS-FFN在前馈网络中探索多尺度信息,通过使用不同尺度的深度卷积核来处理特征图的一部分,从而捕获多尺度的特征表示。
架构变体:TransXNet提供了不同大小的架构变体(如TransXNet-T, TransXNet-S, TransXNet-B),以适应不同的计算预算和应用需求。这些变体通过调整通道数、块的数量、注意力组数和MS-FFN的扩展比率来控制计算成本。
实验验证:论文通过在ImageNet-1K图像分类、COCO目标检测和实例分割、ADE20K语义分割等任务上的广泛实验,验证了TransXNet的性能。实验结果表明,TransXNet在保持较低计算成本的同时,取得了优于现有最先进方法的性能。
结构图
block 代码
class Block(nn.Module):
"""
网络模块类。
参数:
dim (int): 嵌入维度。
kernel_size (int): 动态卷积的卷积核大小。默认为 3。
num_groups (int): 动态卷积的组数。默认为 2。
num_heads (int): 自注意力的组数。默认为 1。
mlp_ratio (float): 多层感知器扩展比率。默认为 4。
norm_cfg (dict): 正则化层的配置字典。默认为 `dict(type='GN', num_groups=1)`。
act_cfg (dict): 激活函数配置字典,用于点卷积之间。默认为 `dict(type='GELU')`。
drop (float): Dropout 比率。默认为 0。
drop_path (float): 随机深度率。默认为 0。
layer_scale_init_value (float): Layer Scale 的初始值。默认为 1e-5。
"""
def __init__(self,
dim=64,
kernel_size=3,
sr_ratio=1,
num_groups=2,
num_heads=1,
mlp_ratio=4,
norm_cfg=dict(type='GN', num_groups=1),
act_cfg=dict(type='GELU'),
drop=0,
drop_path=0,
layer_scale_init_value=1e-5,
grad_checkpoint=False):
super().__init__()
self.grad_checkpoint = grad_checkpoint
mlp_hidden_dim = int(dim * mlp_ratio)
# 位置嵌入卷积层
self.pos_embed = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
# 构建正则化层
self.norm1 = build_norm_layer(norm_cfg, dim)[1]
# 混合不同的 token
self.token_mixer = HybridTokenMixer(dim,
kernel_size=kernel_size,
num_groups=num_groups,
num_heads=num_heads,
sr_ratio=sr_ratio)
self.norm2 = build_norm_layer(norm_cfg, dim)[1]
# 多层感知器模块
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_cfg=act_cfg,
drop=drop)
# 随机深度 DropPath
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
# 初始化 Layer Scale 或使用默认值
if layer_scale_init_value is not None:
self.layer_scale_1 = LayerScale(dim, layer_scale_init_value)
self.layer_scale_2 = LayerScale(dim, layer_scale_init_value)
else:
self.layer_scale_1 = nn.Identity 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









