







文章目录
前言
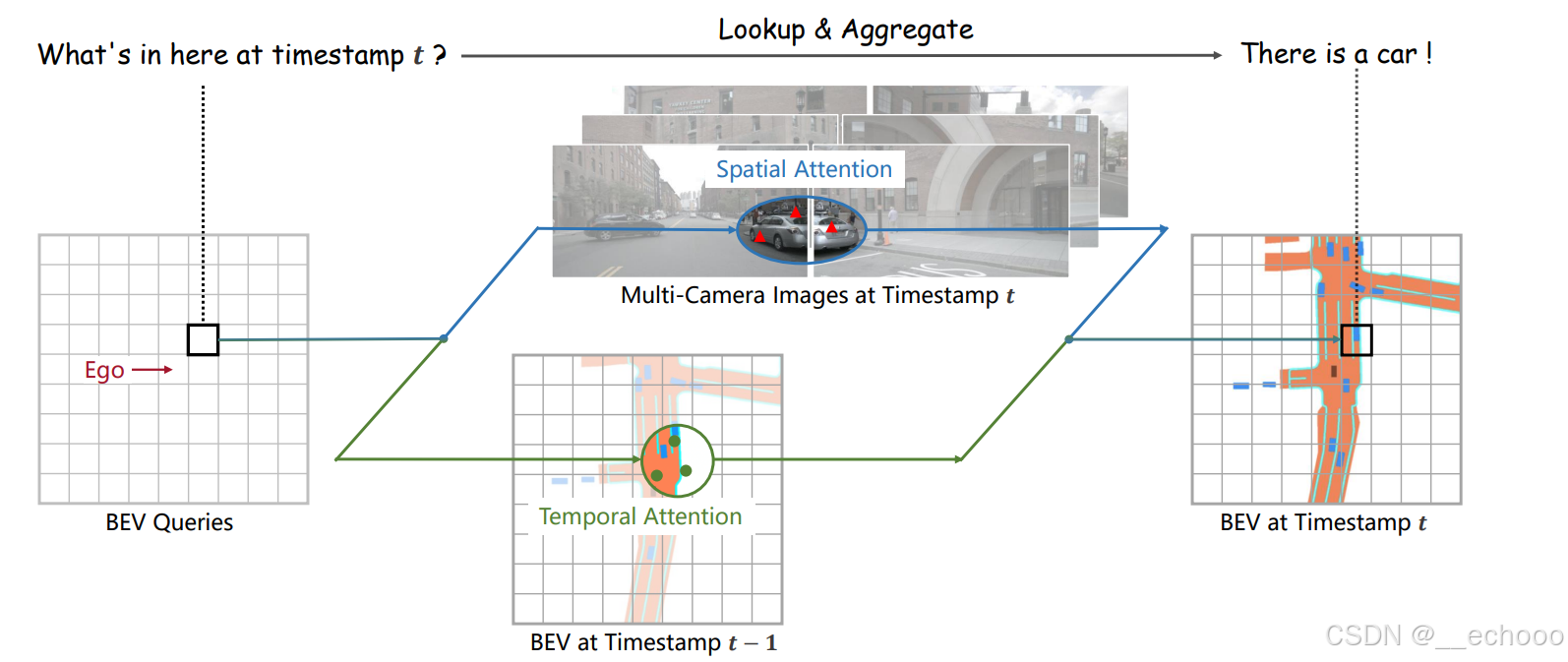
BEVFormer 是 BEV感知算法中的一篇经典之作,值得入门BEV感知的伙伴们好好学习
一、BEVFormer
BEVFormer 是 ECCV 2022 的一篇论文
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
当然,原作者也提供了中文版的论文:BEVFormer
若网站无法访问,可以直接去我上传的资源里面下载中文版原文
1.1 Motivation
自动驾驶中的视觉感知问题,尤其是对周围环境的全面理解,通常依赖于从多个摄像头获取的信息。传统的自动驾驶系统通过将多个摄像头图像投影到鸟瞰图(BEV)上,来生成一个全局的视角表示。这种表示对于多目标检测和追踪等任务非常有帮助。BEV表示可以将周围环境的物体位置、大小、方向等信息有效地传递给后续的决策模块。
然而,当前的多摄像头系统和基于BEV的感知方法面临以下挑战:
- 视角差异:每个摄像头的视角和拍摄方向不同,如何将这些信息整合到一个统一的BEV表示中是一个关键问题。
时空关系的建模:多摄像头系统不仅需要捕捉空间信息,还需要考虑时间序列的动态变化。例如,如何在多个时间步骤内整合这些图像信息,捕捉运动目标的时序特征。 - 高维度的信息处理:多摄像头图像往往包含大量信息,如何高效地处理这些图像并提取有用的特征是一个挑战。
为了解决这些问题,论文提出了 BEVFormer,通过引入 时空变换器(Spatiotemporal Transformers),能够在空间和时间维度上有效地学习和融合来自多个摄像头的图像信息,从而生成更加准确的BEV表示,帮助进行精确的3D目标检测和追踪。
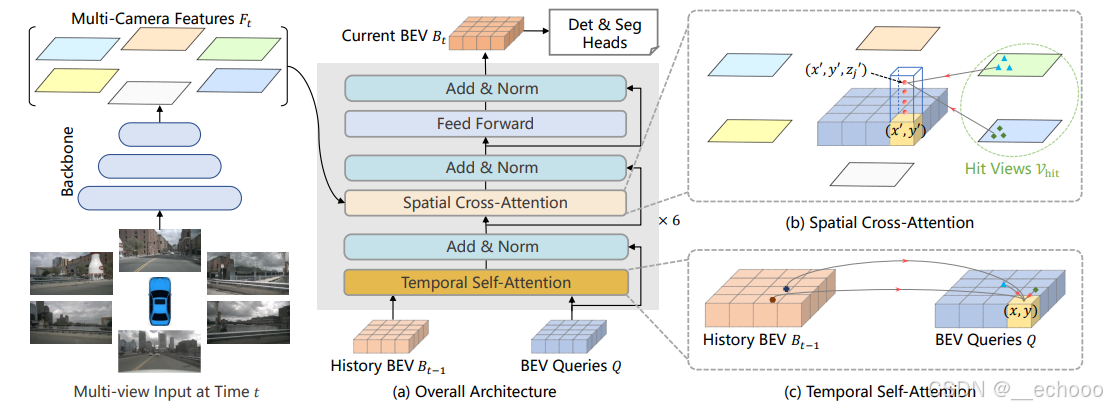
1.2 Method
-
Multi-Camera Image Encoding:
首先,输入的多摄像头图像通过主干网络进行特征提取,得到每个摄像头视角的特征图。这些特征图包含了图像的空间信息,但需要进一步处理以生成一个全局一致的BEV表示。 -
Spatiotemporal Transformer Module:
BEVFormer使用了一个 时空变换器(Spatiotemporal Transformer) 来学习和建模来自多个摄像头图像的空间和时间依赖关系。这个模块不仅考虑了来自不同摄像头视角的信息,还考虑了时间维度上的依赖(例如,目标的运动轨迹)。
Transformer模块通过自注意力机制(Self-Attention)将多个摄像头视角和时间步骤的信息聚合到一起,生成全局一致的BEV表示。 -
BEV Representation Generation:
经过时空变换器的处理后,得到的特征被映射到一个鸟瞰图(BEV)坐标系中,生成最终的BEV表示。这些BEV特征图可以用来进一步进行目标检测、追踪等任务。 -
Post-Processing:
最后,BEV表示会经过一些后处理步骤,生成最终的预测结果,例如在BEV图上标注物体的边界框和位置。
3. Input & Output
输入:
网络的输入是来自多个摄像头的图像。具体来说,假设有 N 个摄像头,输入为一个包含 N 张图像的序列。每张图像的尺寸可以是 H×W,因此每个摄像头的输入图像是一个 H×W×C 的张量,其中 C 是图像的通道数(如RGB图像为3)。
另外,网络还可能使用 时间序列的图像,即在多个时间步骤中捕捉到的图像,用于建模运动目标的时序特征。
输出:
输出是生成的 鸟瞰图(BEV)表示,通常是一个 H’×W’×C’ 的张量,其中 H’ 和 W’ 是输出的 BEV 图像的空间尺寸,C’ 是 BEV 图像的通道数,通常是物体检测所需的特征维度。
输出还包括 目标检测结果,如物体的 3D 边界框、位置、速度等信息。
那么接下来就开始实战复现吧!!
二、环境配置
由于环境依赖较为复杂,容易出现很多问题,因此记录下来,方便以后查阅,也希望能帮到各位
2.1 创建环境
推荐重新创建一个 conda 环境
conda create -n your_env_name python=3.8 -y
conda activate your_env_name
your_env_name 为你给该环境取的名字
2.2 安装pytorch相关库
- 如果你是 CUDA 11.1 ,则可以使用文档中的命令安装torch
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
- 但是如果你的环境不是 CUDA 11.1,推荐使用适合cuda版本的torch(当然大多数情况都可以向下兼容)
注:推荐 torch>=1.9,并且python是3.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cuxxx
注:上面最后的cuxxx,表示你电脑的版本。如cuda11.6,则替换成cu116
不过需要注意这个方式下载的torch所对应python版本是否适配自身的电脑
- 如果下载缓慢可以直接进网址选择合适的版本下载:
https://download.pytorch.org/whl/
注:推荐找到 torch-xxx+cuxxx-cp3x-linux_x86的这种形式的whl包
一共三个要下载:torch、torchvision、torchaudio

以下是源码 推荐的配置对应的名字,在上面的网站找到下载
torch-1.9.1+cu111-cp38-cp38-linux_x86_64.whl
torchvision-0.10.1+cu111-cp38-cp38-linux_x86_64.whl
torchaudio-0.9.1-cp38-cp38-manylinux1_x86_64.whl
下载完成后,依次安装即可:
pip install
2.3 安装gcc (可选)
安装gcc到conda环境里面
conda install -c omgarcia gcc-6
2.4 安装mmcv-full
安装mmcv-full
这里推荐不要随意更换 mmcv-full 的版本,否则可能后续有很多坑…
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
注意!!这里推荐后面加上 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
并且!!后面改成自己的torch对应的版本以及torch所对应的cuda版本!!!
如上面 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
则是安装适配 torch1.9.0+cu111 版本的mmcv-full==1.4.0
注:期间会下载很多其他的库,如果遇到下载缓慢的包可以手动下载
手动下载pip换源下载可以参考 【pip 安装】国内 pip 镜像源换源方法以及 pip 基本操作
经典报错:fatal error: THC/THC.h: No such file or directory
报错信息:
./mmcv/ops/csrc/pytorch/cuda/psamask_cuda.cu:5:10: fatal error: THC/THC.h: No such file or directory
5 | #include <THC/THC.h>
| ^~~~~~~~~~~
compilation terminated.
error: command ‘/usr/local/cuda-11.6/bin/nvcc’ failed with exit code 1
[end of output]
报错原因:THC方法目前在最新版本的 Pytorch 中已被弃用,并被 ATen API 取代,因此在高版本的Pytorch(版本在1.11.0及以上)编译安装的时候就会遇到无法找到THC/THC.h的报错。
解决方案:降低 pytorch 的版本
输出以下信息即安装成功

2.5 安装mmdet 以及 mmseg
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
2.6 源码安装mmdet3d
克隆仓库并切换到推荐分支
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
注:这里还是推荐使用 v0.17.1 这个分支,其他的分支可能出现不兼容的情况
安装
安装的过程可能比较久,需要耐心等待…
python setup.py install
以下几个库可能比较难下载,必要时可以单独下载
opencv-python
scikit-image
tensorboard
networkx
matplotlib
2.7 安装相关库
安装相关依赖
pip install einops fvcore seaborn iopath==0.1.9 timm==0.6.13 typing-extensions==4.5.0 pylint ipython==8.12 numpy==1.19.5 matplotlib==3.5.2 numba==0.48.0 pandas==1.4.4 scikit-image==0.19.3 setuptools==59.5.0
安装detectron2
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
如果是 “正常上网”,上面的仓库无法安装,可以使用下面这种方法安装,参考 detectron2 Installation
git clone https://github.com/facebookresearch/detectron2.git python -m pip install -e detectron2
至此,就终于配置完 BEVFormer 的相关环境了!!
三、实战
3.1 下载权重
创建放权重的文件夹
mkdir ckpts
推荐直接进入该网址 https://github.com/zhiqi-li/storage/releases/download/v1.0/r101_dcn_fcos3d_pretrain.pth 进行下载
下载完成后放到 ckpts 这个文件夹里面
3.2 准备数据集
按照下面这个文件层级准备:
bevformer
├── projects/
├── tools/
├── configs/
├── ckpts/
│ ├── r101_dcn_fcos3d_pretrain.pth
├── data/
│ ├── can_bus/
│ ├── nuscenes/
│ │ ├── maps/
│ │ ├── samples/
│ │ ├── sweeps/
│ │ ├── v1.0-test/
| | ├── v1.0-trainval/
| | ├── nuscenes_infos_temporal_train.pkl
| | ├── nuscenes_infos_temporal_val.pkl
然后下载 can_bus文件
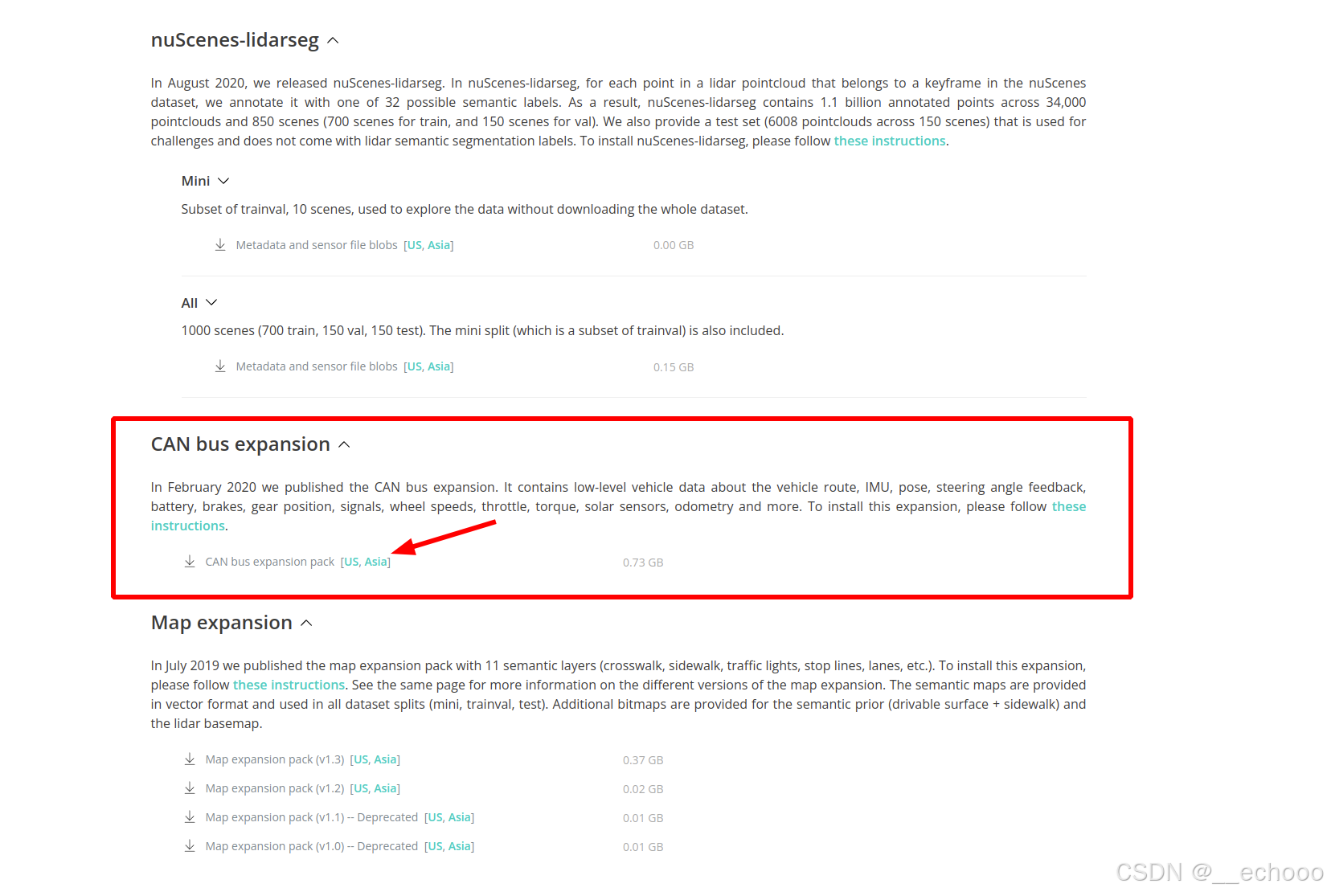
将其解压,并放到对应的文件夹中
unzip can_bus.zip
生成数据pkl文件
# 对于nuscenes full data
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0 --canbus ./data
当然使用mini数据集也可以
# 对于nuscenes mini data
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini --canbus ./data
3.3 运行测试
下载权重:
自行选择模型的大小,然后点击下载
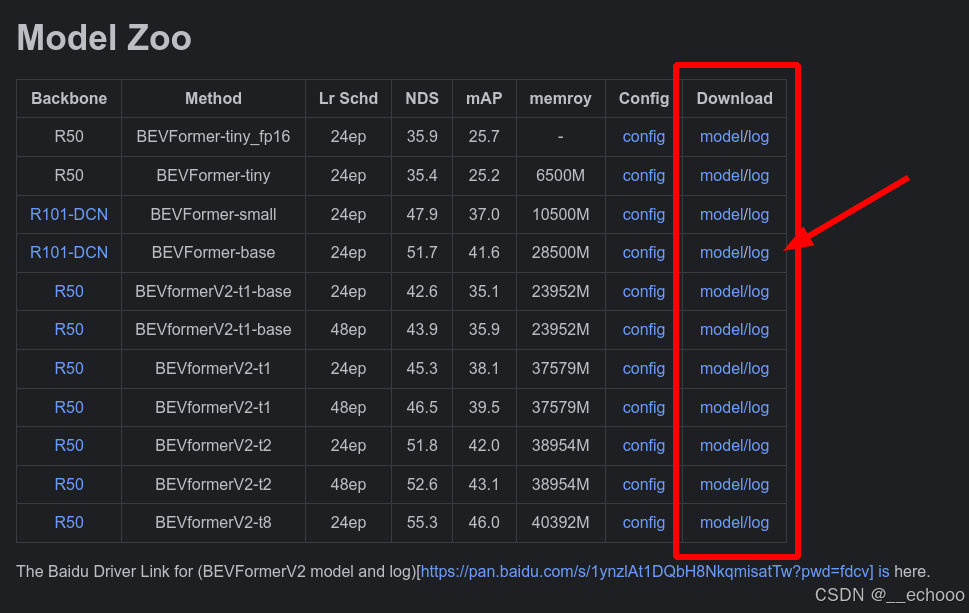
运行测试:
./tools/dist_test.sh ./projects/configs/bevformer/bevformer_base.py ./ckpts/bevformer_r101_dcn_24ep.pth 8
- 参数1:模型配置文件config的路径
- 参数2:权重的路径
- 参数3:GPU数量
3.4 启动可视化
可能报错:libgobject动态库导入报错
报错信息:ImportError: /lib/x86_64-linux-gnu/libgobject-2.0.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
解决方案:让这个项目能找到这个动态库
先检测是否有这个动态库
ldconfig -p | grep libffi
ldconfig -p | grep libgobject
若没有则安装
sudo apt upgrade libglib2.0-0
sudo apt upgrade libffi7
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libffi.so.7
可能报错:找不到 tools 这个库
报错信息:ModuleNotFoundError: No module named ‘tools’
但是实际上是有的,只是python找不到
解决方案:导入python路径
在当前项目文件夹中,输入下面命令:
export PYTHONPATH=./
可能报错:
报错信息:ImportError: cannot import name ‘cached_property’ from ‘functools’
这可能是由于python版本低于3.8 导致
如果需要重装python版本,推荐将前面的依赖和环境都重装一遍,不然后续容易出现不兼容的情况
解决方案:重装环境
3.5 训练
训练的命令:
./tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py 8
- 参数1:配置文件的路径
- 参数2:GPU数量
可能的报错:
Traceback (most recent call last):
File “./tools/train.py”, line 263, in
main()
File “./tools/train.py”, line 180, in main
cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
File “ib/python3.8/site-packages/mmcv/utils/config.py”, line 541, in dump
f.write(self.pretty_text)
File “lib/python3.8/site-packages/mmcv/utils/config.py”, line 496, in pretty_text
text, _ = FormatCode(text, style_config=yapf_style, verify=True)
TypeError: FormatCode() got an unexpected keyword argument ‘verify’
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 11997) of binary: bin/python
原因:由于 yapf 版本不兼容导致的。FormatCode 函数中的 verify 参数在新版本中可能已经被移除或改变了。
解决方案:降低 yapf 版本
pip install yapf==0.31.0
四、总结
首先简单讲解了BEVFormer的原理的结构,其次主要记录了BEVFormer代码完整的全流程环境配置以及实战其中容易出现的问题,后续有其他更好的想法以及补充也会更新上来


















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











