







文章目录
前言
现在自动驾驶中的 Occupany network 到底是什么呢?为什么在如今的自动驾驶的感知算法中显得如此重要?它的优势是什么?Occupany network 与3D目标检测有什么区别?Occupany network 与3D语义分割有什么区别?
一、Occupany network是什么?
综述:
3D Occupancy Perception for Autonomous Driving
相关部分数据集:
Waymo
Kitti Dataset
OpenOccupancy
OpenScene: Autonomous Grand Challenge Toolkits
相关文章参考:
Tesla Occupancy Network
OccNet 栅格占据网络:重建智能驾驶场景表征
Occupancy 解读
SemanticKITTI 研读
SemanticKITTI论文翻译与学习
ICCV’23 | OpenOccupancy语义占用新突破:首个周视占用感知基准
1.1 Occupany network 的来龙去脉
Occupany network 即占用网络,这个网络概念最早被提出是在2018的论文:
论文:Occupancy Networks: Learning 3D Reconstruction in Function Space
这篇论文是基于三维重建任务的工作,主要核心是利用占位网络隐含地表示表示任意拓扑结构的高分辨率几何图形,相比单个图像、嘈杂点云和粗离散体素网格进行三维重建具有更好的效果。
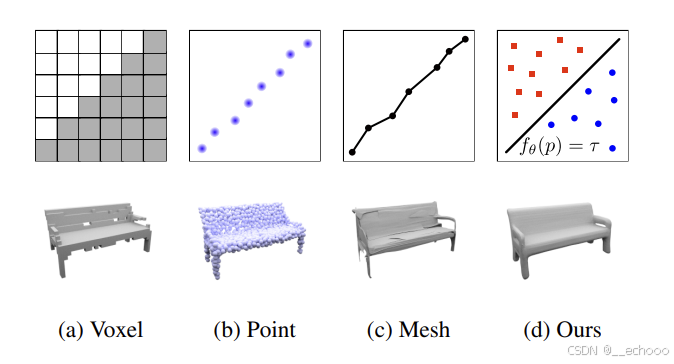
而让 Occupany network 真正流行并运用到自动驾驶感知的是 Tesla
在 2022 年的 Tesla AI Day 上, Tesla 将 Bev(鸟瞰图) 感知进⼀步升级,提出了基于 Occupancy Network 的感知⽅法。
引入Occupancy算法的背景:
业界在实现自动驾驶的过程中,小样本目标的漏检误检问题,非立体的平面目标画像的误检问题等等,是传统算法无法解决的。其根因可以简单归纳几点:
- 接近地平线的远景区域深度极度不一致问题
- 传统的3D目标感知算法过于依赖数据集的类别标注,不常见的物体类别没被标注,从而导致无法被检测出来
- 小样本目标问题:远距离目标的深度信息消失,或者超低分辨率很难决定一个目标区域的深度(例如图右桥墩漏检后导致致命性车辆撞击问题)
- 遮挡问题、鬼影问题:不能穿透遮挡区域或者行驶车辆来识别被遮挡目标,遮挡目标长记忆轨迹预测困难
- 2D或者2.5D视频约束问题:非立体的平面目标画像问题:难以对应到真实3D场景,难区分静态和动态目标
- 2D目标固定框问题:难以识别悬挂或者悬空的障碍物(可能不在目标检测框内,例如卸货卡车的千斤顶支撑架,卡车货架顶上的人梯等)
Occupany network 的一大核心目标在于将目标检测(Object Detection)为主转变为语义分割(Semantic Segmentation)
这种基于 Occupancy Grid Mapping 的表示⽅法,⼜叫体素(Voxel)占据。它与机器人技术中使用的占用网格映射(OGM)有着一定的相似之处。
基本的思想是将三维空间划分成体素voxel,通过0/1赋值对voxel进行二分类:有物体的voxel赋值为1,表示voxel被物体占据;没有物体的voxel被赋值为0。
这种方法将世界划分成为⼀系列 3D ⽹格单元,然后定义哪个单元被占⽤,哪个单元是空闲的,并且每个占据单元同时也包含分类信息,⽐如路⾯、⻋辆、建筑物、树⽊等。在⾃动驾驶感知中,相⽐普通的 3D 检测⽅法,这种基于体素的表示可以帮助预测更精细的异形物体。
实际的应用中的Voxel的属性一般不是简单的 0或1 ,而一般为概率值,表示voxel存在物体的概率。Voxel的属性除了占用概率值这个属性之外,可能还包含语义信息和速度信息(Occupancy Flow)等。其中速度信息是一个三维向量,用于表述voxel运动的速度和方向,类似于2D图像中的光流(Optical Flow)。通过occupancy flow可以用于判断物体是否运动。
通过获取立体的Voxel属性信息,使感知能够在三维空间中确定物体的位置、形状、速度等信息,进而有效识别和处理那些未被明确标注或形状复杂的障碍物,如异形车、路上的石头、散落的纸箱等。
总而言之,这种占据栅格网络使得自动驾驶系统能够更准确地理解周围的环境,不仅能识别物体,还能区分静态和动态物体。并以较高的分辨率和精度表示三维环境,对提升自动驾驶系统在复杂场景下的安全性、精度和可靠性有着较大的作用。
以下Occupany network简称为Occ
1.2 Occ 相关的概念
接下来熟悉并知晓一下Occ 相关的概念,方便后续的研究
1.2.1 Voxel
Voxel是三维像素的简称,它是将像素的概念扩展到三维空间中的一种技术。在计算机图形学和三维建模中,Voxel(体素)是指体积像素,即空间中的小块体积元素,每个体素可以包含颜色和透明度信息,用于构建三维模型或场景。这种技术允许在三维空间中以像素化的方式表示对象,创造出具有特定风格和视觉效果的模型,如《我的世界》和《纪念碑谷2》中所展示的鲜明风格。
《我的世界》游戏展示图:

在lidar的点云设置中,点云的范围通常被设置为[-55, -55, -5, 55, 55, 3],分别表示
相对应的在Occ中:
voxel占据状态一般可以分为3种:Occupied(被占用的)、Free(空闲的)、Unobserved(无法被观测的)
voxel 的大小常被设置为0.5m或0.2m
1.2.2 3D点云语义分割(3D-Semantic-Segmentation)
3D-Semantic-Segmentation:
Awesome-3D-Semantic-Segmentation
3D语义分割框架综述
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Surfaces
3D语义分割与Occ的区别其实不大,主要还是两者的侧重点不同。3D语义分割是基于点级别的,是需要评估模型对每个点(点云)、像素(图像)的分类的准确性,而Occ是基于体素的,是需要评估模型是否能准确的判断每个体素是否被占用。
其中3D语义分割的真值是每个点的标签,每个点的标签表示了这个点所属的类别;Occ的真实是体素标签,每个体素的标签表示了这个体素是否被占用。
下图展示的为3D点云语义分割的图像,每个点都包含了这个点属于什么类别的信息:

下图展示的为Occ的图像,每个体素都包含了这个体素是否被占用的信息(图中为了可视化,区分了颜色):

简而言之,就是3D语义分割更注重于这个物体的类别,而Occ更注重这个空间的体素是否被占用了,输出的该体素被占用的概率。
如果’free’作为一个表示空白区域的类别,occ将会把’free’定义为0,然后其他被占用的区域定义成1
感觉其实现在做3D 分割的不多了,在落地方面作用稍微下降了
1.2.3 语义场景补全(Semantic Scene Completion, SSC)
3D 语义场景完成(Semantic Scene Completion)是一种机器学习任务,涉及以体素化形式预测给定环境的完整3D场景(完成3D形状的同时推断场景的 3D 语义分割的任务)。这是通过使用深度图和为场景提供上下文的可选 RGB 图像来完成的。SSC通过使用计算机视觉和深度学习技术,将输入的不完整或缺失的场景图像补全为完整的、具有语义信息的场景图像的任务。SSC的概念最初在SSCNet中提出,其核心思想是通过对场景的部分可见区域进行分析,预测出场景中不可见区域的语义信息,从而实现对场景的全面理解。近年来,SSC的研究得到了显著扩展,尤其是在小型室内场景的背景下,研究者们提出了多种方法来提升语义补全的精度和效率。
SSC任务的核心是将输入的不完整场景图像补全为完整的场景图像,并且保持补全后的图像具有语义信息。这意味着补全后的图像应该能够准确地还原缺失的区域,并且能够根据场景的语义结构进行合理的补全。核心目标是生成具有高质量、真实感和一致性的完整场景图像。
SSC任务的难点主要包括以下几个方面:
语义理解和推理
为了能够准确地补全缺失的区域,模型需要具备对场景的语义理解和推理能力。这需要模型能够理解场景中的物体、场景结构和语义关系,并且能够根据已有的信息进行合理的推断和补全。
视觉一致性和真实感
补全后的图像应该具有与原始图像一致的视觉风格和真实感。这需要模型能够学习到场景的视觉特征和纹理,并且能够将这些特征应用到补全的区域中,以保持整体图像的一致性和真实感。
数据稀缺性
由于补全任务的复杂性和数据获取的困难性,很难获得大规模的高质量标注数据集。因此,缺乏大规模的训练数据可能会限制模型的学习能力和泛化能力。
多样性和复杂性
场景图像的多样性和复杂性使得补全任务变得更加困难。不同场景可能具有不同的结构和语义关系,模型需要能够适应不同场景的特点,并且能够处理复杂的场景结构和语义关系。
1.2.4 纯视觉Occ、Lidar Occ、融合Occ
纯视觉Occ
纯视觉Occ难度比其他两种方法要大,因为需要大量来自数据集真值的训练,才能准确的输出结果
Lidar Occ
如果输入的信息是lidar的点云,通过输入的点云信息从而输出Occ的信息。其实该基于Lidar 的Occ任务与语义场景补全(Semantic Scene Completion, SSC)这个任务类似,甚至可以认为是同一种任务。如果硬要具体细分其中的不同点的话,主要的区别可以说是在于输出的信息类型。Occ任务一般只关注于物体是否占用了该体素空间,而SSC需要预测占用该体素空间的物体的所属类别。
但是其实目前来说很多Occ也并不只是预测物体是否占用了空间,同样也会输出一些类别
融合Occ
将Lidar的点云信息与相机的语义信息作为输入,从而输出Occ的信息。
1.3 评价指标
1.3.1 对于Occ预测的评价指标
可以用交并比 (intersection over union, IoU)、(mean intersection over union, mIoU)来评价
其中IoU是不计算分类的,也就是忽略Occ对类别的预测,只关注Voxel是否预测的准确
而mIoU则是计算了每个类的平均IoU,把类别的预测考虑了进去
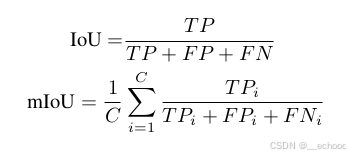
一般视觉 Occ的评价都是基于可见区域的,也就是不可见区域不进行评价,不加入计算
此外,[CVPR 2024自动驾驶国际挑战赛(Autonomous Grand Challenge)],中也采用了一种更好的评价指标:Ray-level mIoU
该指标的提出来自ECCV2024的:Fully Sparse 3D Occupancy Prediction
该评估指标包含基于光线的平均交并比(RayIoU)和占用流的绝对速度误差。
基于光线的 mIoU 在不同距离阈值下对查询光线执行平均交并比计算。对于占用流,它测量在 2m 距离阈值下对 8 个类别的真阳性检测的速度误差。最终的占用评分定义如下:
OccScore = mIoU ∗ 0.9 + max(1 − mAVE, 0) ∗ 0.1.
传统的voxel-level mIoU局限性:
-
传统的voxel-level mIoU指标存在局限性,尤其是在处理稀疏数据时
-
mIoU是基于voxel级别的评估,它需要对整个3D体积进行密集的预测,这在计算上非常昂贵,尤其是在处理大规模场景时。
-
mIoU在评估时没有考虑深度方向上的不一致惩罚,这可能导致模型倾向于预测厚表面以获得更高的指标,即使这并不意味着性能的实际提升。
-
此外,mIoU评估指标通常只关注当前时刻的可见区域,忽略了场景补全能力。这意味着,即使模型能够准确地预测出可见区域的占用状态,它也可能无法有效地补全场景中不可见或被遮挡的部分。
RayIoU:
- RayIoU的核心思想是将查询光线投射到预测的3D占用体积中,并计算光线与任何表面相交之前所经过的距离。对于每个查询光线,只有当其类别预测正确,并且深度预测误差在一定阈值内时,才被视为真正例(True Positive)。
- 这种方法不仅能够更公平、合理地评估占用预测的性能,而且还能够更好地处理稀疏数据。
1.3.2 对于3D 语义场景补全的评价指标
如下表所示:
Acc值、Comp值、CD值越低表示模型性能越好
Prec值、Recall值、F-score值越高表示模型性能越好
其中的p表示预测值、p*表示真值点云

1.4 相关数据集概览
可以看来自OpenScene的总结的两个表格:
| Dataset | Sensor Data (hr) | Scan | Annotated Fame | Sensor Setup | Annotation | Ecosystem |
|---|---|---|---|---|---|---|
| KITTI | 1.5 | 15K | 15K | 1L 2C | 3D box, segmentation, depth, flow | Leaderboard |
| Waymo | 6.4 | 230K | 230K | 5L 5C | 3D box, flow | Challenge |
| nuScenes | 5.5 | 390K | 40K | 1L 6C | 3D box, segmentation | Leaderboard |
| Lyft | 2.5 | 323K | 46K | 3L 7C | 3D box | - |
| ONCE | 144 | 1M | 15K | 1L 7C | 3D box, 3D lane | - |
| BDD100k | 1000 | 100K | 100K | 1C | 2D box, 2D lane | Workshop |
| OpenScene | 120 | 40M | 4M | 5L 8C | Occupancy | Leaderboard Challenge Workshop |
| Dataset | Original Database | Sensor Data (hr) | Flow | Semantic Categories |
|---|---|---|---|---|
| MonoScene | NYUv2 / SemanticKITTI | 5 / 6 | ❌ | 10 / 19 |
| Occ3D | nuScenes / Waymo | 5.5 / 5.7 | ❌ | 16 / 14 |
| Occupancy-for-nuScenes | nuScenes | 5.5 | ❌ | 16 |
| SurroundOcc | nuScenes | 5.5 | ❌ | 16 |
| OpenOccupancy | nuScenes | 5.5 | ❌ | 16 |
| SSCBench | KITTI-360 / nuScenes / Waymo | 1.8 / 4.7 / 5.6 | ❌ | 19 / 16 / 14 |
| OccNet | nuScenes | 5.5 | ❌ | 16 |
| OpenScene | nuPlan | 120 | ✔️ | - |
1.5 最终总结
-
Occ 任务的 input & output
input:相机输入 or lidar输入
真值:voxel 的标注信息:0或1、速度信息
output:自车系周围的范围内的所有voxel占用情况以及voxel的速度信息 -
Occ 更多的应用在于纯视觉的方案,其中包括 monocular、Multi-View的传感器配置,当然传感器能够覆盖的区域越全面,对场景的理解会更好,占用预测的准确率也会越高。
-
因此目前所提的Occ算法,一般指的也是纯视觉Occ算法。在 CVPR 2024自动驾驶国际挑战赛(Autonomous Grand Challenge) 中的占据栅格和运动估计(Occupancy & Flow)赛道也是同样以Multi-View Camera的图像数据作为输入。
-
在纯视觉Occ算法中,lidar并不是完全舍弃了,lidar的一种作用在于监督纯视觉Occ模型的训练或者是生成纯视觉Occ所需的真值。
-
而上面所提及的SSC,也就是基于点云的语义场景补全这个任务与Lidar Occ基本上属于同一种任务,都是通过输入稀疏点云,利用深度学习的方法生成了周围环境的3D 语义的Voxel信息,这里的Voxel往往会带有类别信息。可以说目前SSC更多是在雷达领域中的概念,包括lidar、radar(当然视觉也有)。
-
SSC主要关注如何根据可见区域推断出不可见区域的占用情况,即通过部分信息推测整体场景的语义结构;而 Occ 则更侧重于对可见区域的占用情况进行精确预测,通常用于实时场景理解和动态环境感知。
最后放上一些经典的参考文献:
- Scene as Occupancy
- Occupancy Flow Fields for Motion Forecasting in Autonomous Driving
- Convolutional Occupancy Networks
二、 Occ的真值数据标注与生成
Occ的真值数据标注与生成存在一定的难度,因为数据的生成与优化很大程度上影响Occ模型的检测性能
Occupancy真值通常不会直接进行人工标注,因为直接人工标注的难度较大,往往需要借助3D box的位置和语义信息间接生成。
较好的的Occ真值往往需要具备:
- 真值较为稠密,过于稀疏将导致模型难以学习到其中的特征,细粒度尽量满足需求也就是分辨率不能过低
- 动静态目标标注干净且没有过多的拖影
- 标注的地面干净且坡度更接近真实
- 能够区分遮挡和非遮挡元素
- Voxel的类别划分正确
2.1 真值数据标注
如SemanticKITTI dataset,Occupancy 数据集依靠语义分割的结果生成,通过人工对每个体素进行占用、非占用的标注。
待记录…
2.2 真值数据生成
通过稀疏的点云数据生成:
在 SurroundOcc 中只需要数据集中已有的三维目标检测和三维分割标签,无需昂贵的稠密三维占据标注。对于多帧时序激光雷达点云,本文通过三维目标检测标签将场景和物体点云分割开,并利用位姿信息将场景和物体点云分别拼接起来。之后将两种点云合并起来得到稀疏占据标签。为了填补空洞和进一步稠密化,使用泊松重建和最近邻算法得到稠密占据标签。
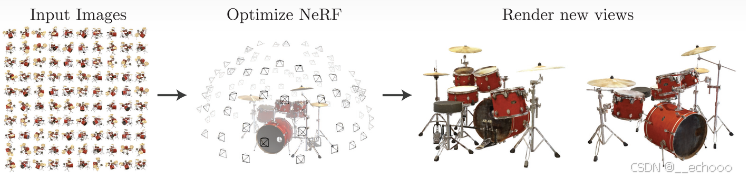
除此之外,也可以通过三维重建的方法,简单来说可以通过对场景的多个不同角度的2d 图像,从而隐式的表达复杂的三维场景,以此来获取真值的数据(特斯拉的纯视觉方案的真值生成貌似就是参考了这种nerf的方法)
三维重建领域,由传统sfm方法逐渐过渡到Nerf方法,NeRF(Neural Radiance Fields)是最早在2020年ECCV会议上的Best Paper,其将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景。
三、 Occ 算法解析与实践
纯视觉的Occ 算法往往分为以下几种:
- 基于点云监督的
- 基于真值监督的
- 基于自监督的
3.1 SurroundOcc
SurroundOcc github
SurroundOcc 论文
3.1.1 算法解析
SurroundOcc是一款基于点云监督的Occ算法
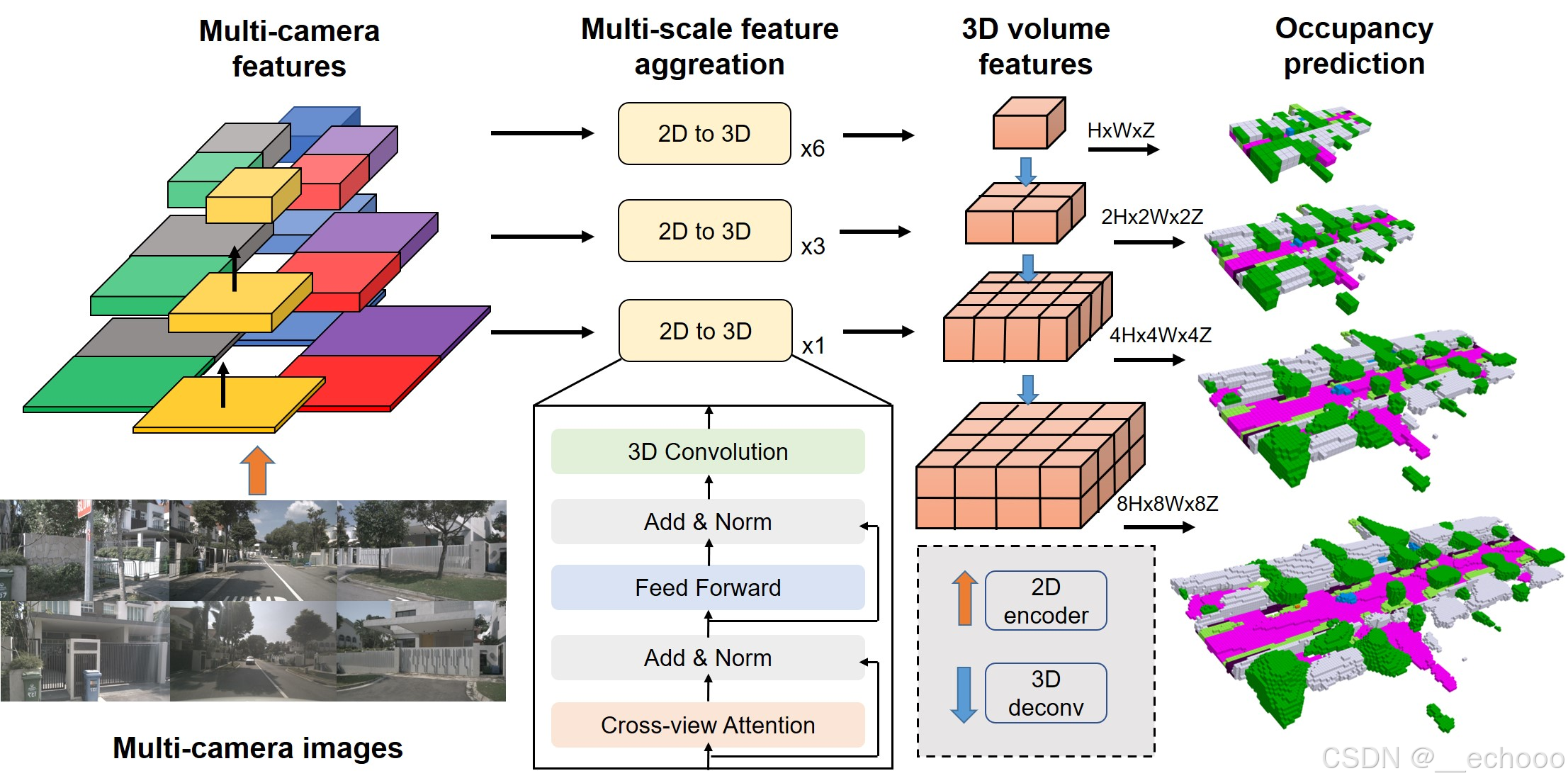
算法pipeline:
下表是模型的性能对比, 测试使用的是RTX 3090, 图像输入为6张1600x900分辨率的图像
可以看到近年来的深度估计以及Occ预测的相关算法,延迟基本在0.5s左右
| Method | Latency (s) | Memory (G) |
|---|---|---|
| SurroundDepth | 0.73 | 12.4 |
| NeWCRFs | 1.07 | 14.5 |
| Adabins | 0.75 | 15.5 |
| BEVFormer | 0.31 | 4.5 |
| TPVFormer | 0.32 | 5.1 |
| MonoScene | 0.87 | 20.3 |
| SurroundOcc | 0.34 | 5.9 |
Occ真值生成:
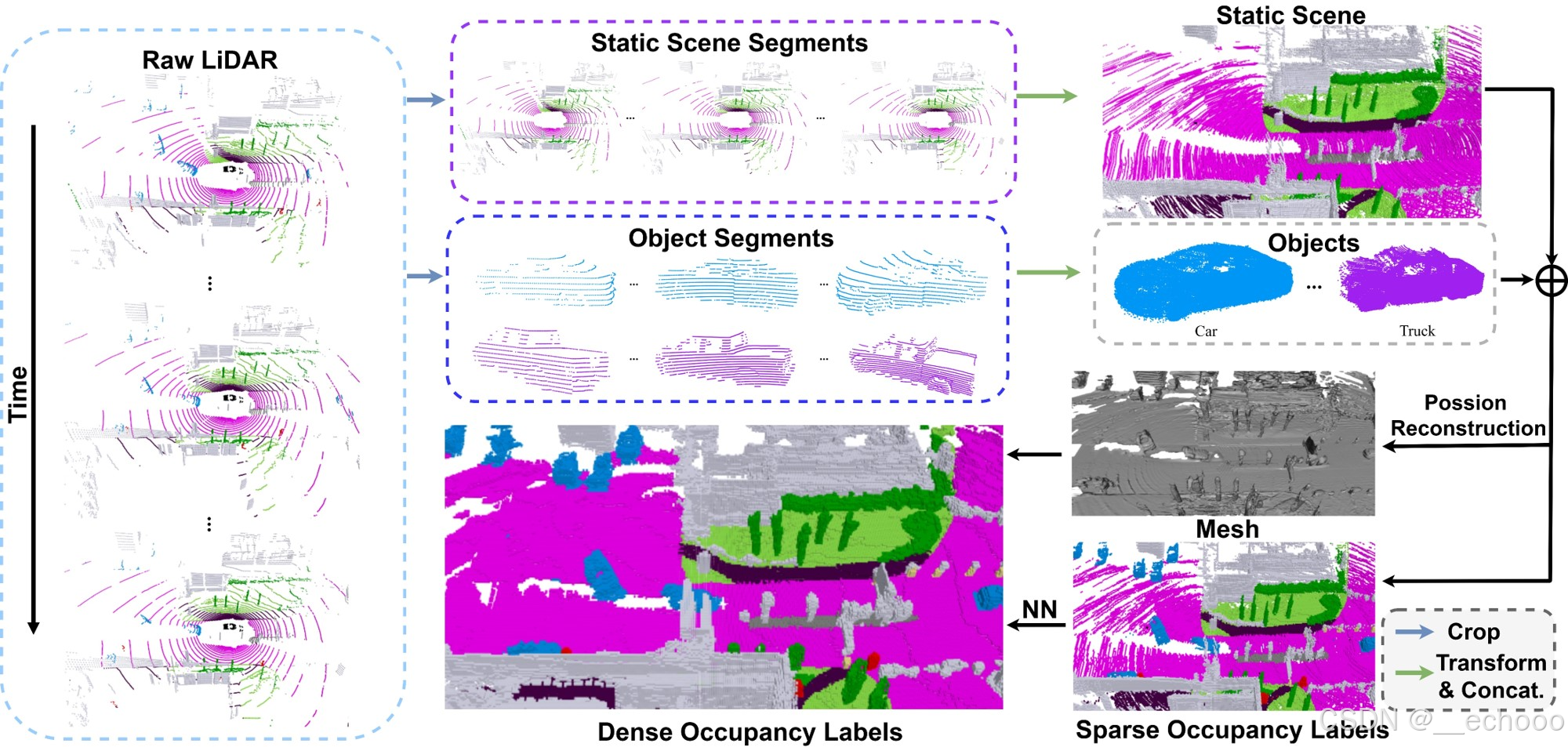
1):多帧点云拼接,提出了一种 two-stream pipeline,可以将静态场景和可移动物体分别拼接,然后在体素化之前将它们合并成完整的场景。
2):Poisson 重建密集化,首先根据局部邻域中的空间分布计算法向量,随后将点云重建成三角网格,进而填补点云中的空洞,得到均匀密布的顶点,最后再转换回密集的体素
3):使用 NN 算法进行语义标注,对具有语义信息的点云进行体素化得到稀疏的占据标签,然后使用最近邻算法(Nearest Neighbor, NN )算法搜索每个体素最近的稀疏体素,并将其语义标签分配给该体素。这一过程可以通过 GPU 进行并行计算以提高速度。最终得到的密集体素提供了更加真实的占据标签和清晰的语义边界。
3.1.2 环境配置
基本上按照项目的 install.md 安装没有什么问题,但是这里为了避免一下后续的麻烦,把可能遇到的问题也记录下来了
1. 创建虚拟环境并激活
conda create -n lidarocc python=3.7 -y
conda activate surroundocc
2. 安装 PyTorch 与 torchvision.
pip install torch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1
要注意这里!!如果自己本机的CUDA版本高于11.3太多(如11.6),则可以选择下面这条命令安装
conda install pytorch1.10.1 torchvision0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
3. Install gcc>=5 in conda env.
conda install -c omgarcia gcc-6 # gcc-6.2
4. Install MMCV.
这里推荐不要随意更换 mmcv-full 的版本,否则可能后续有很多坑…
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
注意!!这里推荐后面加上 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
并且!!后面改成自己的torch对应的版本以及torch所对应的cuda版本!!!
如上面 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
则是安装适配 torch1.9.0+cu111 版本的mmcv-full==1.4.0
安装 MMCV时可能的报错:
The detected CUDA version (11.6) mismatches the version that was used to compile PyTorch
可以参考 :【bug记录】The detected CUDA version (11.6) mismatches the version that was used to compile PyTorch
5. Install mmdet and mmseg.
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
注意!!版本尽量一致,因为mmdet版本之间有一定的变化,版本不一致可能导致后续报错
6. 使用源码安装 mmdet3d.
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1 # Other versions may not be compatible.
python setup.py install
注意!!编译安装 mmdet3d 时,可能遇到超时报错,只需手动安装对应的包,对应的版本即可
如果手动下载太慢,可以使用镜像源,以下附上清华源地址:
https://pypi.tuna.tsinghua.edu.cn/simple
注意!!安装后,可能出现显示某些安装包之间版本不匹配的情况
因此建议降低其中一个安装包的版本以适应其他的安装包
比如:提示A(目前版本3.5)需要 B(目前版本1.7)2.5以上。那么选择将A的版本降低到合适的版本即可
7. 安装其他相关依赖
pip install timm
pip install open3d-python
8. 安装 Chamfer Distance.
cd SurroundOcc/extensions/chamfer_dist
python setup.py install --user
3.1.3 算法实践
下载相关数据
下载准备生成的Occ的标注文件:
文档中提供了两种,一种是较为稀疏的Voxel数据,一种是全分辨率的mesh数据(可以根据该数据,自行下采样)
下载相关的pkl文件:

按照以下结构放置:
SurroundOcc
├── data/
│ ├── nuscenes/
│ ├── nuscenes_occ/
│ ├── nuscenes_infos_train.pkl
│ ├── nuscenes_infos_val.pkl
尝试可视化生成的occ信息
可视化命令:
python visual.py /path/to/xxxxxxxxx.pcd.bin.npy
报错:导入cv2的相关动态库报错
报错信息
ImportError: /lib/x86_64-linux-gnu/libgobject-2.0.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
解决方案:
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libffi.so.7
可视化效果如下图:
可以看到这个是比较稀疏的OCC标注,文档中也说明了这是分辨率为 200x200x16 , voxel size 为0.5m的occ标注

训练
训练需要完整的nuscenes数据集或nuscenes mini数据集
待记录…
测试
测试需要完整的nuscenes数据集或nuscenes mini数据集
待记录…
3.2 OpenOccupancy
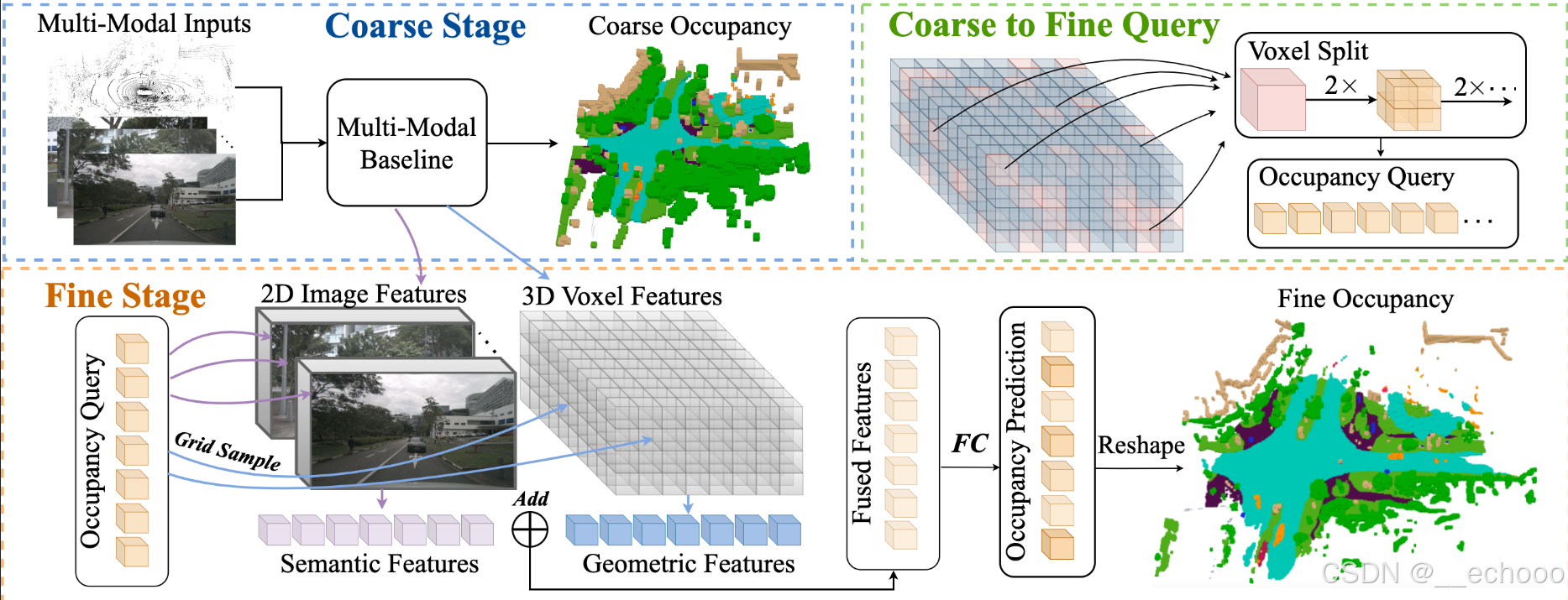
OpenOccupancy中提出的Baseline: Cascade-Occupancy-Network
3.2.1 环境配置
待记录…
3.2.2 算法解析
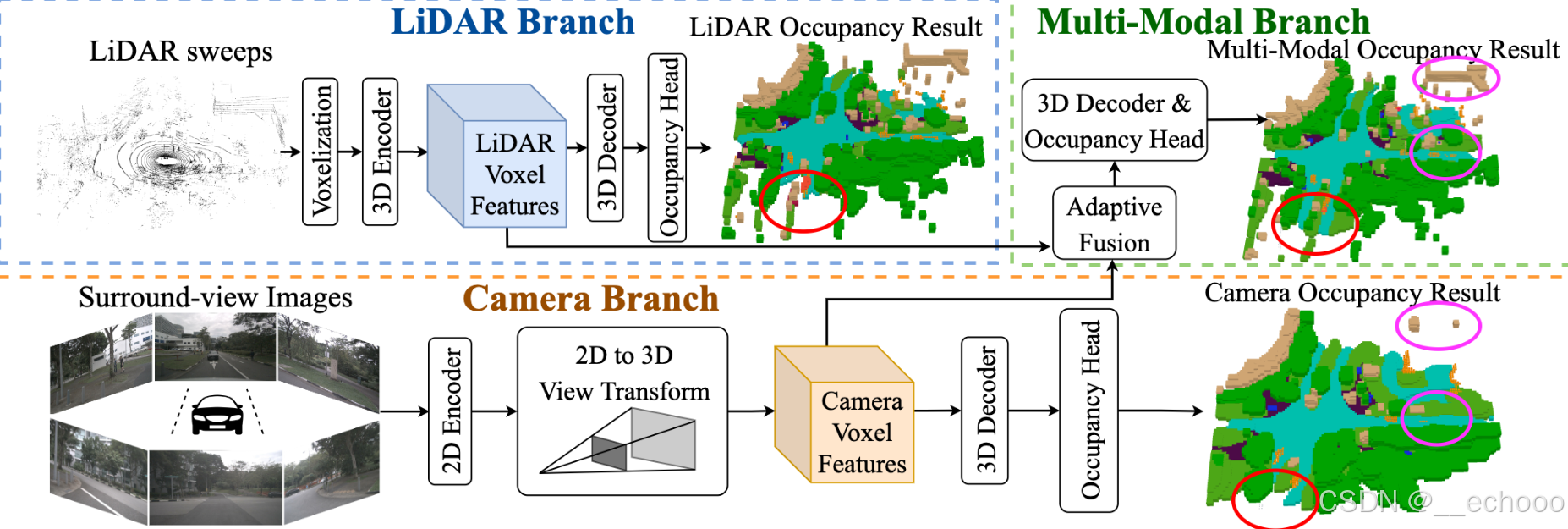
其中基于LiDAR的基线算法步骤如下:
(1)Voxellization:输入的原始点云首先通过参数化体素的方式转化为初始的体素特征。
(2)3D Encoder:为了提高计算效率,采用 3D 稀疏卷积编码体素空间的特征,产生 LiDAR voxel features。
(3)3D Decoder:体素特征被 3D 卷积进一步编码和解码,生成多尺度体素特征。这些特征被上采样然后沿着通道串联。
(4)Occupancy Head:最后,利用 occupancy head 来减少特征通道,并利用softmax函数来产生语义占用概率。
基于Camera的基线算法步骤如下:
(1)2D Encoder:首先利用 2D 编码器(具体地,使用ResNet和FPN结合产生多尺度特征)来提取多视图特征。
(2)2D to 3D view transformer:将 2D 特征投影到 3D 自车坐标中,与现有的 BEV 方案不同的是,这里我们保留了高度信息以得到三维网格特征,以便于细粒度的 3D 语义占有预测。
(3)Camera Voxel Encoder:使用 3D 卷积对相机体素特征进行编码,所产生的体素特征与LiDAR对应的特征形状相同。
(4)3D Decoder和 Occupancy Head:与基于LiDAR的基线算法相同,我们进一步采用 3D 解码器和语义占用头来输出语义占用概率。
3.3 Flash-Occ
Flash-Occ是一款基于真值监督的Occ算法
Flash-Occ 论文
3.3.1 Pipeline
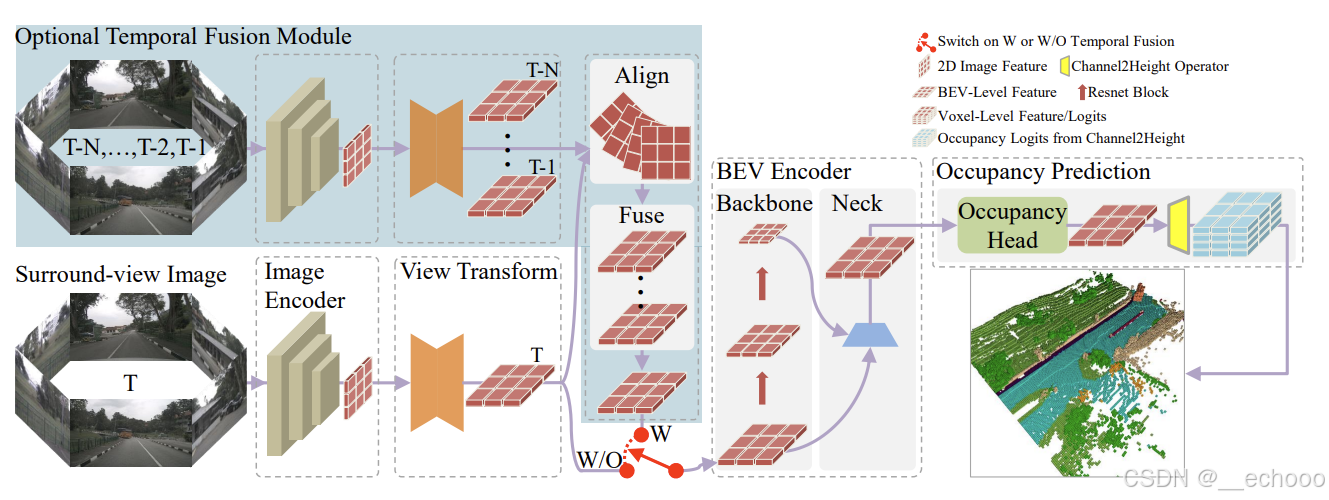
Flash-Occ 的网络主要分为以下几个部分:
- 主干网络模块:ResNet50+FPN
- View transform 模块:用的是 LSS 将从 2D 图像特征转换到 BEV 空间
- BEV 多尺度融合:一些多尺度的bev特征融合
- 检测头模块:occ的检测头
3.3.2 核心的模块:
第一个模块:时间融合模块,实际中取三帧的multi view的图像(N=6),经过2d主干网络,t时刻只下降到当前特征图的1/2倍
其中时序融合的作用: 避免遮挡,利用多帧进行特征加强
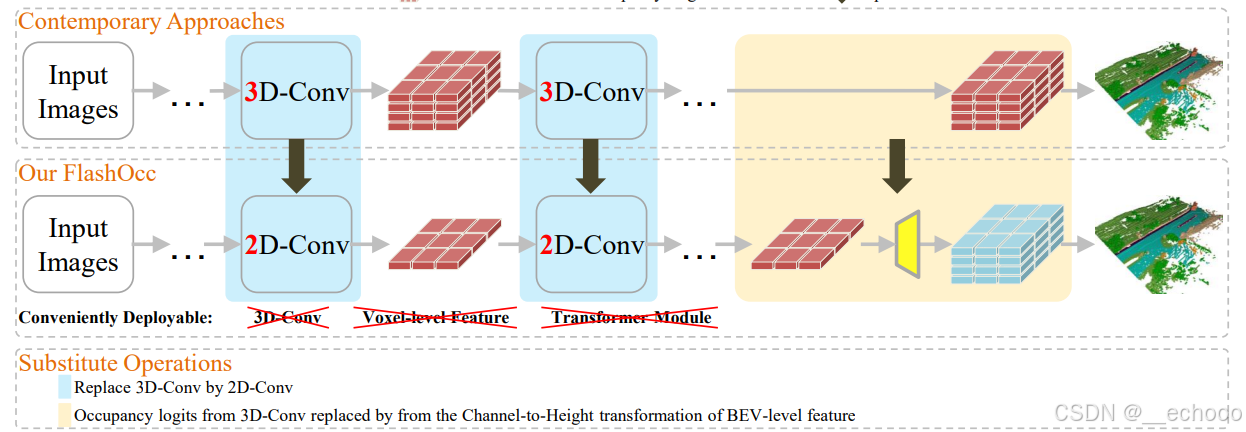
第二个模块:2D转换3D空间的模块
核心在于舍弃了3D卷积,避免了复杂冗余的计算,加入了通道转换到高度的操作,形成了3D特征
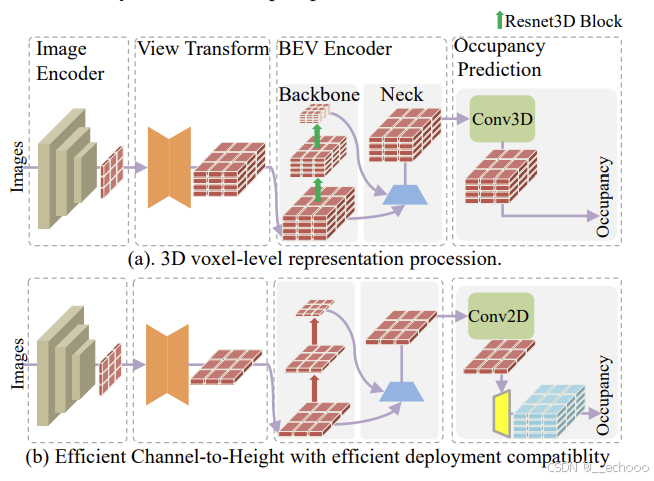
Flash-Occ也可以作为一个插件,文章里面也做了相对应的消融实验,证明了加入插件之后,精度、推理速度都有所提升,资源的消耗
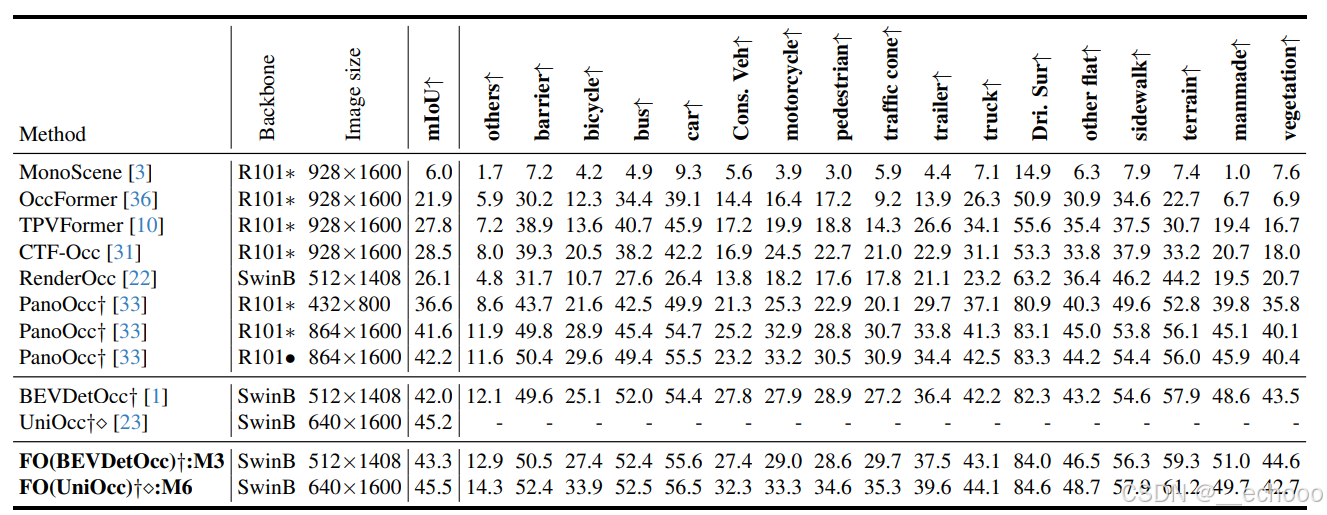
3.3.3 性能对比
下面是在 Occ3D-nuScenes valuation dataset 的表现
可视化效果:
设置的预测范围是 X和Y都是 -40 ~ 40m的范围,Z轴是 -1 ~ 5.4m的范围,超过这个范围的的目标则不预测

3.3.4 优化思考
- 可以根据实际需求修改输入图像的大小、BEV网格的大小
- 主干网络可以替换为更高效的网络
- LSS模块可以加速优化处理
3.4 TPVFormer
TPVFormer 是一款基于点云监督的Occ算法
待记录…
四、 SemanticKITTI 数据集实践
4.1 下载并解压数据集
SemanticKITTI github
下载对应数据集,并解压到同一个文件中
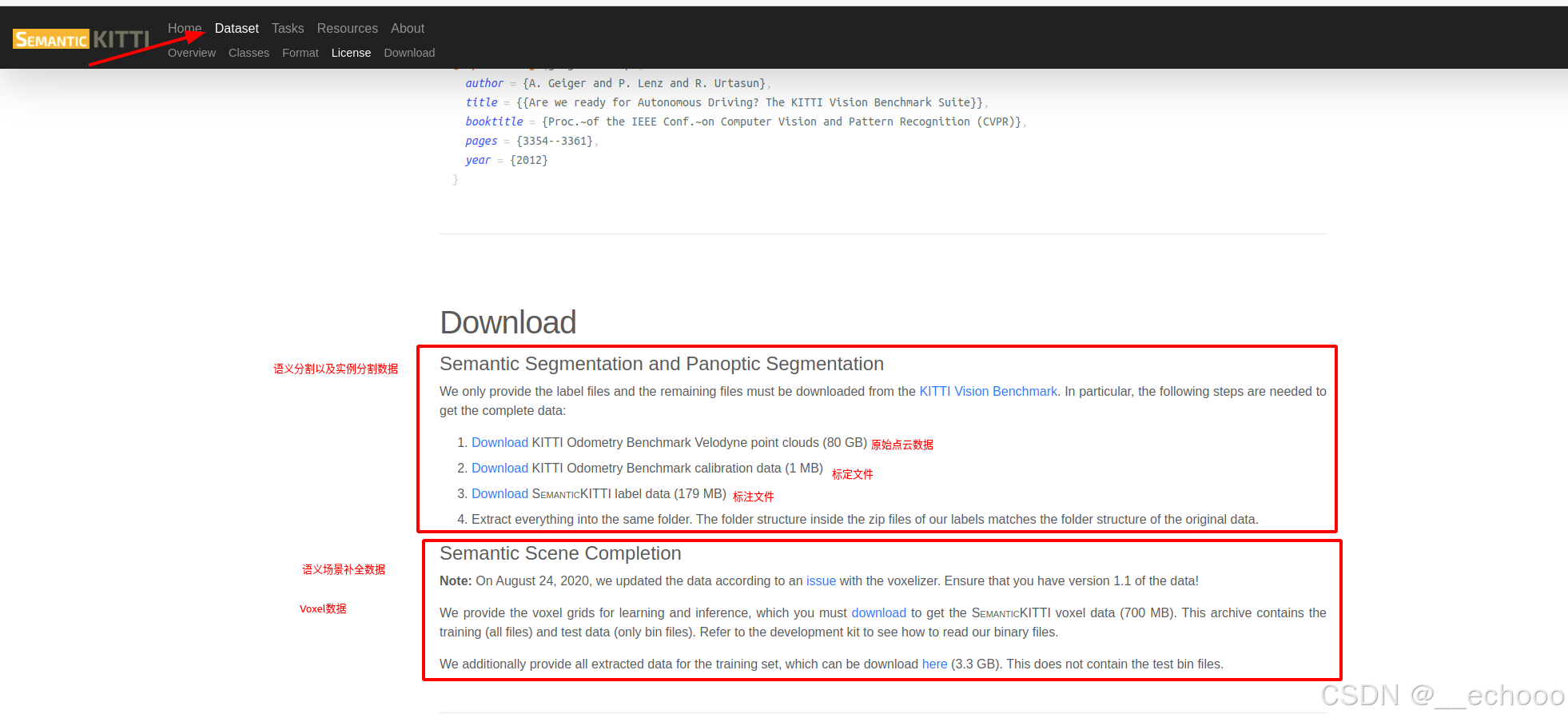
全部下载解压到同一个文件夹里面,可以获得以下文件:

4.2 可视化
运行以下命令即可开启可视化
python ./visualize.py --sequence 00 --dataset /path/to/semantic_kitti/dataset
点云数据如下图所示,左图为原始点云数据,右图为标注后的点云图像:
运行以下命令即可开始Voxel的可视化界面
python ./visualize_voxels.py --sequence 00 --dataset /path/to/semantic_kitti/dataset
下图是原始点云输入的Voxel的可视化图

下图是标注的Voxel可视化图

五、一些Occ 实战与思考
5.1 训练配置
Occ的模型如果想要训练出一个比较好的效果,通常算力不能太低,否则迭代时间太长,影响实验进程
参考:通常训练 nuScenes 这样规模的数据,需要8张卡,FP16 (TFLOPS) 在35以上。
当然,训练时长受多方面因素影响,比如超参数、网络层数、硬件性能等。因此上面的配置仅作为参考
5.2 数据规模
5.3 模型训练思考
- 时序的融合对 Occ 模型提升有这较大的帮助,但是同时会对算力提出较大的挑战…
六、 总结
结合自己经验和参考了一些资料后,整理了的有关Occ的一些内容:包括概念、常见算法解析以及实践,方便日后回顾
目前文中有一些模块还没实践完成,一些内容也未整理,后续会慢慢补充…


















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











