






基于Patch的MLP在长期时间序列预测中的应用
| 标题 | Unlocking the Power of Patch:Patch-Based MLP for Long-Term Time Series Forecasting |
|---|---|
| 作者 | Peiwang Tang , Weitai Zhang |
| 期刊 | AAAI | 2024,(Association for the Advancement of Artificial Intelligence) |
| 机构 | iFLYTEK Research(科大讯飞),University of Science and Technology of China(中国科学技术大学) |
| 论文 | Unlocking the Power of Patch: Patch-Based MLP for Long-Term Time Series Forecasting |
| 代码 | https://github.com/TangPeiwang/PatchMLP |
1 摘要(Abstract)
最近许多研究都试图改进Transformer的体系结构,以证明其在长期时间序列预测(LTSF)任务中的有效性。尽管性能不断提高,超越了许多线性预测模型,但作者仍然对Transformer作为LTSF解决方案持怀疑态度。
作者将这些模型的有效性主要归因于所采用的Patch机制,该机制在一定程度上增强了序列局部性,但未能完全解决固有的排列不变自注意力机制导致的时间信息丢失问题。进一步的研究表明,用Patch机制增强的简单线性层可能优于复杂的基于Transformer的LTSF模型。此外,与使用通道独立性的模型不同,作者的研究强调了跨变量相互作用在增强多变量时间序列预测性能方面的重要性。变量之间的相互作用信息是非常有价值的,但在过去的研究中被误用,导致了次优的交叉变量模型。
基于这些见解,作者为LTSF任务提出了一种新颖而简单的基于patch的MLP (PatchMLP)。具体来说,作者采用简单的移动平均线从时间序列数据中提取平滑分量和含噪声的残差,通过信道混合进行语义信息交换,并专门研究具有信道独立处理的随机噪声。PatchMLP模型在几个真实世界的数据集上始终如一地获得最先进的结果。
2 引言(Introduction)
首先强调了长期时间序列预测(LTSF)在统计学和机器学习领域的重要性,指出其在生物医学、经济金融、电力和交通等多个行业中的关键作用。接着,介绍了多变量时间序列(MTS)的概念,即由同一时间点记录的多个变量组成,每个维度可以视为单独的单变量时间序列或具有多个通道的信号。随着深度学习的发展,多种模型被开发用于提升MTS预测性能,其中Transformer架构在捕捉长期依赖关系方面显示出巨大潜力,但其在LTSF任务中的有效性受到质疑。近期PatchTST的研究表明,简单的线性模型(如MLP)在某些情况下可能优于复杂的Transformer模型,这引发了对Transformer在LTSF任务中有效性的重新思考。这项研究提出了三个关键问题:
PatchTST引出的关键问题:
-
通道混合策略是否对多变量预测无效?
- 现行的sota模型似乎都用的通道独立,但是自变量之间存在关联影响也是可能的,为什么一定要通道独立呢?是方法论的问题吗?
-
直接分解原始时序是否优于学习潜在分解?
- 从结果来看,NLinear、DLinear、FITS都是这样的思路。
-
分块Transformer的性能提升是源于架构优势还是分块本身?
- PatchTST中,到底是因为patch这种处理方法,还是因为Transformer架构本身起作用?这个问题很关键,因为如果是patch这种数据处理方法起作用,那么我们也可以尝试把Patch和MLP方法结合。用朴素的控制变量思想,如果是Patch起作用的话,Patch+MLP也应该有一定的效果提升。这就是本文的一个出发点。
针对上述问题,作者提出了PatchMLP,这是一种针对LTSF任务量身定制的新颖而简洁的Patch-based MLP模型。PatchMLP完全基于全连接网络,并融合了patch的概念。具体来说,作者采用patch方法将原始序列嵌入到表征空间中,然后使用简单的移动平均技术提取序列的平滑分量和噪声残差进行单独处理。独立地处理跨信道的随机噪声,并通过信道混合促进变量之间的语义信息交换。经过对大量真实数据集的评估,PatchMLP模型展示了最先进的(SOTA)性能。准确地说,作者的贡献可以概括为三个方面:
- 作者分析了补丁在时间序列预测中的有效性,并提出了一种多尺度补丁嵌入(MPE)方法。与以前使用单一线性层的嵌入方法不同,MPE能够捕捉输入序列之间的多尺度关系。
- 作者引入了一个全新的完全基于mlp的模型,命名为PatchMLP。通过使用移动平均线,它执行潜在向量的分解,并采用不同的方法进行通道混合,以实现跨变量的语义信息交换。
- 作者在不同领域的广泛数据集上的实验表明,PatchMLP在多个预测基准中始终如一地实现SOTA性能。此外,作者对基于patch的方法进行了广泛的分析,目的是为未来时间序列预测的研究绘制新的方向。
贡献:提出PatchMLP,结合多尺度分块、潜在特征分解和通道交互,实验证明其优于复杂模型。
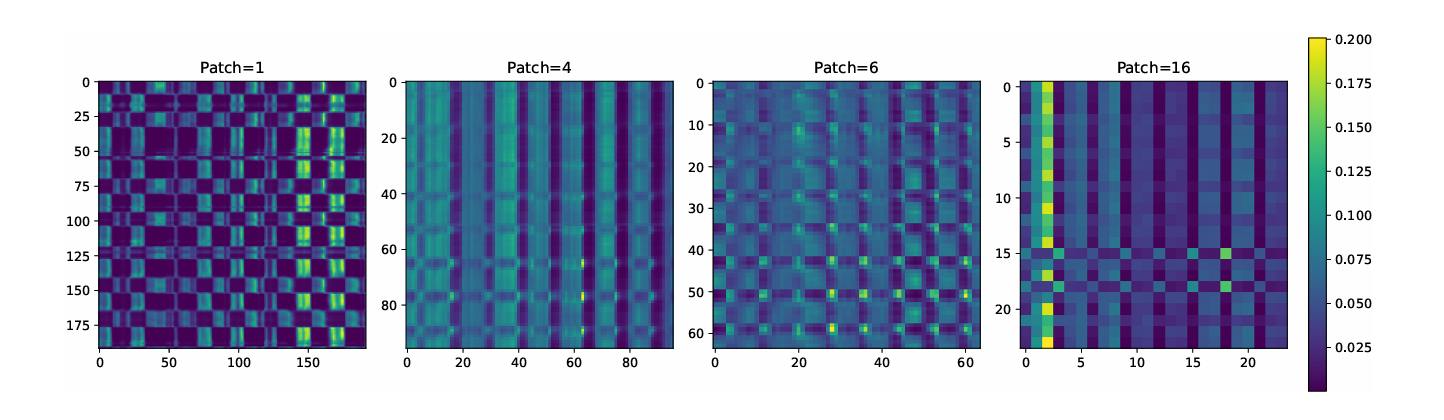
图1:在ETTh1上训练的具有不同Patch大小的2层Transformer的自关注分数。作者遵循PathcTST (Nie等人,2022)的设置,仅保留编码器,同时用简单的MLP替换解码器,并使用信道独立的方法。patch大小为1相当于原始Transformer,说明时间序列数据往往呈现被分割成patch的趋势(Zhang和Yan 2022;Tang and Zhang 2023),而增加Patch大小可以在一定程度上缓解这种情况。
3 分块在LTSF中的作用(Patch for LTSF)
作者通过实验对比揭示了传统Transformer的注意力机制(self-attention)在长序列预测中的局限性。如图2b所示,当输入长度固定时,随着Patch尺寸的增大,模型的均方误差(MSE)呈现先下降后上升或趋于稳定的趋势。这表明,过小的Patch可能无法有效捕捉长期依赖,而过大的Patch则会导致信息过度压缩,尤其是当嵌入维度( d m o d e l d_{model} dmodel)固定时,更多时间点被映射到同一维度,可能损失关键细节。例如,当输入序列长度增加时,模型需逐步增大Patch尺寸以达到最优性能,但若Patch尺寸过大(如将整个序列作为一个Patch),其压缩方式类似于iTransformer,虽能简化计算,却可能因参数过多导致欠拟合,如图2c所示。
其次,原始时间序列因高频采样包含大量冗余特征,且易受噪声干扰(如传感器误差或异常值)。传统注意力机制对噪声敏感,难以区分有效信号与噪声,而稀疏注意力(Sparse Attention)虽通过减少关注点缓解了噪声影响,却可能削弱原始特征的表达。相比之下,Patch机制通过将序列分割为局部块并线性嵌入,实现了双重优化:一是通过降维减少冗余特征,二是通过局部平滑抑制噪声和异常值,保留更稳定的信息。例如,在CV领域,ViT和MAE的成功已验证了Patch在提取局部特征中的普适性;在时间序列中,Patch不仅能增强短期模式的捕捉(如日内波动),还能通过多尺度设计(如混合不同长度的Patch)建模长期趋势。
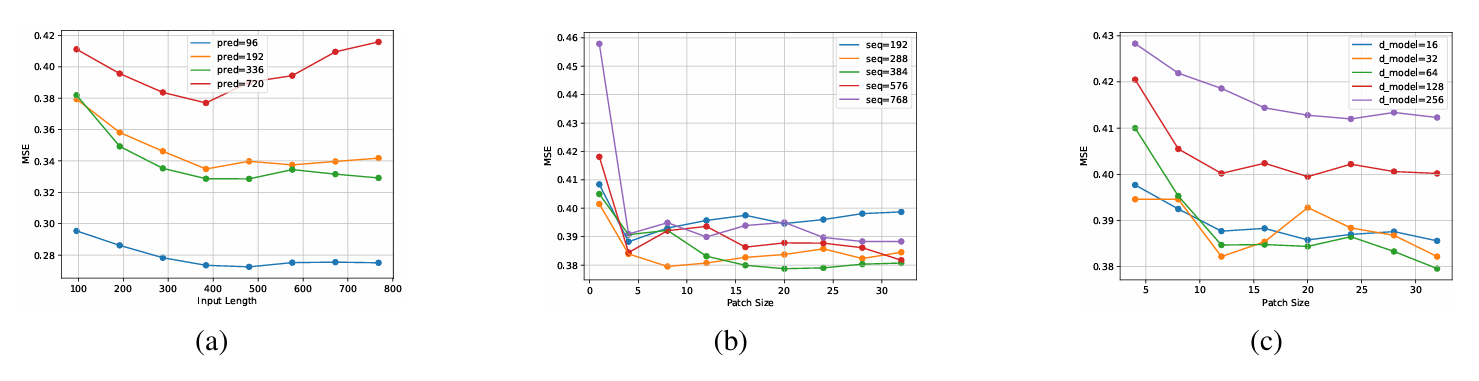
图2:Patch Transformer在ETTh2数据集上的实验结果。(a)保持所有其他参数不变,只改变输入长度,给出四个预报长度的MSE结果。(b)保持所有其他参数不变,只改变patch的大小,MSE得到5种不同输入长度的预测长度为720。©保持所有其他参数不变,只改变补丁大小,五个不同的dmodel值的MSE结果,输入和预测长度均设为720。
进一步地,作者强调,Patch的有效性并非源于Transformer架构本身,而是其数据压缩与局部增强的能力。实验表明,当完全依赖注意力机制(如Patch尺寸为1,即原始序列)时,模型性能甚至不及单层MLP,这直接挑战了注意力机制在时间序列建模中的必要性。相反,合理的Patch设计(如中等尺寸结合多尺度)能够平衡信息保留与压缩,同时适配不同复杂度的模式。例如,在电力需求预测中,短Patch捕捉小时级波动,长Patch建模月度周期,而嵌入维度 d m o d e l d_{model} dmodel的适度增加(如图2c)可提升特征表达能力,但需避免参数过多导致的过拟合风险。
4 PatchMLP模型(PatchMLP)
多元时间序列预测的问题是输入历史观测值 X = { x 1 , ⋯ , x L ∣ x i ∈ R M } \mathcal{X}=\{x_{1},\cdots,x_{L}|x_{i}\in\mathbb{R}^{M}\} X={x1,⋯,xL∣xi∈RM},输出为预测相应的未来序列 X = { x L + 1 , ⋯ , x L + T ∣ x i ∈ R M ] \mathcal{X}=\{x_{L+1},\cdots,x_{L+T}|x_{i}\in\mathbb{R}^{M}] X={xL+1,⋯,xL+T∣xi∈RM],其中 L L L和 T T T分别为输入和输出序列的长度,M为变量的维数。
如图3所示,PatchMLP由多尺度补丁嵌入层、特征分解层、多层感知器(Multi-Layer Perceptron, MLP)层、投影层四个网络组件组成。多尺度补丁嵌入层将多变量时间序列嵌入到潜在空间中。特征分解层将潜在向量分解为平滑分量和噪声残差,然后通过MLP层分别进行操作。最后,通过投影层将潜在向量映射回特征空间,得到未来序列 X ^ \hat{\mathcal{X}} X^。
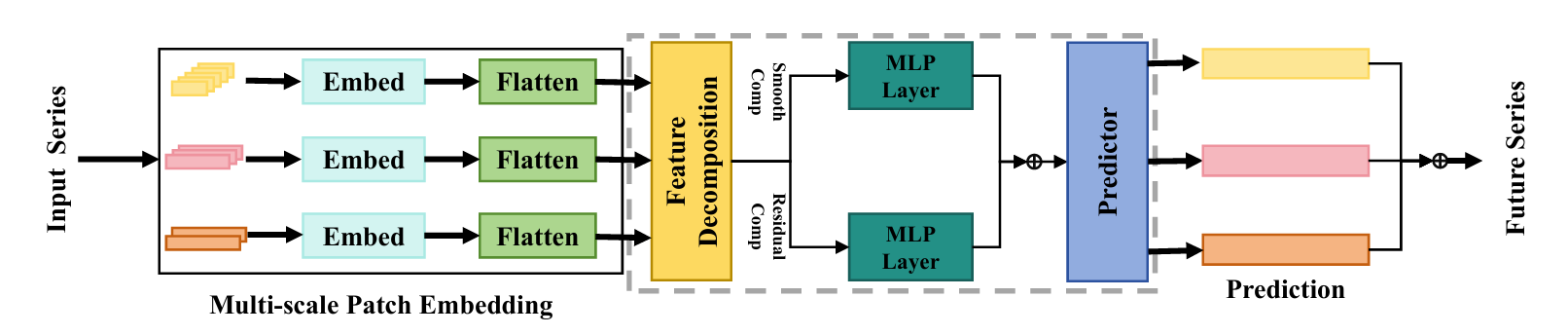
图3:PatchMLP的整体结构。首先,通过多尺度补丁嵌入对不同变量的原始时间序列进行独立处理。然后,特征分解使用移动平均将嵌入的标记分解为平滑分量和噪声残差。接下来,MLP以两种方式处理序列:变量内和变量间。最后,Predictor将潜在向量映射回预测,并将其聚合到未来的序列中。
4.1 多尺度Patch嵌入层(Multi-Scale Patch Embedding)
- 多尺度分割:先将多变量时间序列分解为单变量序列 x x x,按预定义尺度集合 P = { p 1 , p 2 , … , p k } \mathcal{P}=\{p_1,p_2,\ldots,p_k\} P={p1,p2,…,pk}分割为非重叠局部块。例如,短尺度 p 1 = 24 p_1=24 p1=24捕捉日内波动,长尺度 p 2 = 48 p_2=48 p2=48建模周趋势,生成对应Patch序列 x p ∈ R N × p x_p\in\mathbb{R}^{N\times p} xp∈RN×p( N N N 为块数)。
- 独立嵌入:每个尺度的Patch通过独立的线性层映射到潜在空间,得到不同维度的嵌入向量 x e ∈ R N × d x_{e}\in \mathbb{R}^{N\times d} xe∈RN×d( d d d可随尺度调整)。例如,短尺度嵌入维度 d 1 = 64 d_1=64 d1=64,长尺度 d 2 = 128 d_2=128 d2=128,以适配不同时间跨度的特征复杂度。
- 整合与对齐:将不同尺度的嵌入向量展平并拼接,通过线性层压缩至统一维度 d m o d e l d_{model} dmodel,形成最终嵌入 X ∈ R 1 × d m o d e l X\in\mathbb{R}^{1\times d\mathrm{model}} X∈R1×dmodel。这一过程保留多尺度信息,使模型能够同时学习短期细节(如小时级波动)与长期模式(如季节趋势)。
假设单变量时间序列 x x x长度为96,短尺度 p 1 = 24 p_1=24 p1=24,长尺度 p 2 = 48 p_2=48 p2=48,生成对应Patch序列 x p ∈ R N × p x_p\in\mathbb{R}^{N\times p} xp∈RN×p( N N N 为块数),即生成 x 1 ∈ R 4 × 24 x_1\in\mathbb{R}^{4\times 24} x1∈R4×24和 x 2 ∈ R 2 × 48 x_2\in\mathbb{R}^{2\times 48} x2∈R2×48两个矩阵。对于每个尺度的补丁序列,我们使用单层线性层将其嵌入到潜在空间中。假设嵌入维度为 d 1 = 64 d_1=64 d1=64, d 2 = 128 d_2=128 d2=128,则嵌入后的潜在向量 x e 1 = x 1 ⋅ W 1 , x e 1 ∈ R 4 × 64 x_{e1}=x_1\cdot W_1,x_{e1}\in\mathbb{R}^{4\times64} xe1=x1⋅W1,xe1∈R4×64, x e 2 = x 2 ⋅ W 2 , x e 2 ∈ R 2 × 128 x_{e2}=x_2\cdot W_2,x_{e2}\in\mathbb{R}^{2\times128} xe2=x2⋅W2,xe2∈R2×128,将不同尺度的潜在向量展开并组合,分别展开为一维向量 x e 1 ∈ R 256 x_{e1}\in\mathbb{R}^{256} xe1∈R256, x e 2 ∈ R 256 x_{e2}\in\mathbb{R}^{256} xe2∈R256,将 x e 1 x_{e1} xe1和 x e 2 x_{e2} xe2拼接在一起,再通过线性压缩层对齐为统一维度 d m o d e l d_{\mathrm{model}} dmodel,输出整合后的潜在向量 X ∈ R M × d m o d e l X\in\mathbb{R}^{M\times d_{\mathrm{model}}} X∈RM×dmodel(每个变量独立处理,共 M 个变量)。
4.2 特征分解层(Feature Decomposition)
传统方法直接对原始序列进行分解,但在处理复杂混合模式(如噪声干扰、非线性成分)时难以准确分离趋势与季节成分。为此,作者转向对嵌入向量的分解:通过将时间序列映射至高维空间形成嵌入表示,这些向量能够更有效地捕捉数据的核心特征,同时过滤表层噪声。具体而言,在潜在空间中,嵌入后的向量被分解为平滑分量(smooth components)和噪声残差(noisy residuals)。具体操作是通过移动平均(如平均池化)提取平滑趋势,剩余部分则视为噪声。例如,对潜在向量 X ∈ R M × d m o d e l X\in\mathbb{R}^{M\times d_{\mathrm{model}}} X∈RM×dmodel,平滑分量 X s X_{s} Xs通过平均池化计算,残差 X r = X − X s X_r=X-X_s Xr=X−Xs。这种分解使模型能够分别处理主要趋势与随机波动,减少噪声对预测的干扰,同时保留关键语义信息。
X s = A v g P o o l ( X ) X r = X − X s \begin{aligned}&X_s=AvgPool(X)\\&X_r=X-X_s\end{aligned} Xs=AvgPool(X)Xr=X−Xs
X s ∈ R M × d m o d e l X_s\in\mathbb{R}^{M\times d_{\mathrm{model}}} Xs∈RM×dmodel和 X r ∈ R M × d m o d e l X_r\in\mathbb{R}^{M\times d_{\mathrm{model}}} Xr∈RM×dmodel分别表示提取的平滑分量和残差分量。通过对嵌入向量而不是原始序列进行操作,该模型可以更精确地提取和识别时间序列的基本成分,从而更好地理解时间序列的内在结构,最终提高时间序列预测的准确性。
4.3 MLP层(Multi-Layer Perceptron)
MLP层交替处理时间维度(Intra-Variable)和变量维度(Inter-Variable)的信息:
- Intra-Variable MLP:针对每个变量单独建模时间依赖。将 X s X_{s} Xs和 X r X_{r} Xr重塑为 R M × d m o d e l \mathbb{R}^{M\times d_{\mathrm{model}}} RM×dmodel,沿时间维度应用全连接层(如 d m o d e l → 4 d m o d e l d_\mathrm{model}\to4d_\mathrm{model} dmodel→4dmodel),经GELU激活和Dropout后恢复维度。此过程捕捉变量内局部模式。
- Inter-Variable MLP:建模跨变量交互。将输入重塑为 R d m o d e l × M \mathbb{R}^{d_{\mathrm{model}}\times M} Rdmodel×M,沿特征维度应用全连接层(如 M → 2 M M\to2M M→2M),并通过点积操作 X i n t e r = X M L P ⊙ X i n X_\mathrm{inter}=X_\mathrm{MLP}\odot X_\mathrm{in} Xinter=XMLP⊙Xin增强非线性交互,捕捉变量间关联。
- 残差连接:将MLP输出与输入相加,保留原始信息并稳定训练,即 X o u t = X i n t e r + X i n X_\mathrm{out}=X_\mathrm{inter}+X_\mathrm{in} Xout=Xinter+Xin。
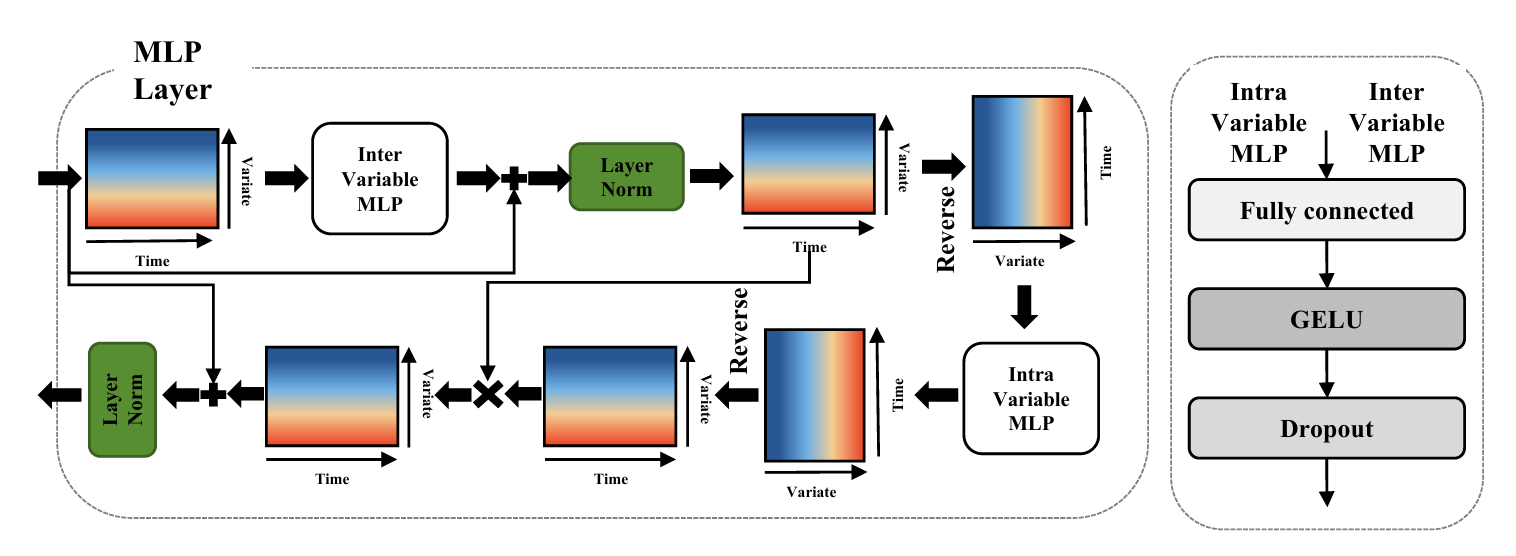
图4:MLP层整体结构。嵌入的向量首先通过变量内MLP与变量内的时间信息交互。然后通过变量内MLP与变量之间的特征域信息交互。随后,使用点积方法将它们乘以变量间MLP的输入。最后,使用跳过连接将它们添加到MLP层的初始输入中。
4.4 投影层(Projection Layer)
将MLP层输出的潜在向量 X o u t ∈ R M × d m o d e l X_\mathrm{out}\in\mathbb{R}^{M\times d_\mathrm{model}} Xout∈RM×dmodel映射为未来预测序列:对每个变量独立应用线性投影层,将 d m o d e l d_{\mathrm{model}} dmodel维度映射到目标时间步 T \mathrm{T} T,即, W p r o j ∈ R d m o d e l × T W_{\mathrm{proj}}\in\mathbb{R}^{d_{\mathrm{model}}\times T} Wproj∈Rdmodel×T生成 X ^ ∈ R M × T \hat{\mathcal{X}}\in\mathbb{R}^{M\times T} X^∈RM×T。最终输出 X ^ = { x ^ L + 1 , … , x ^ L + T } \hat{\mathcal{X}}=\{\hat{x}_{L+1},\ldots,\hat{x}_{L+T}\} X^={x^L+1,…,x^L+T},其中每个时间步的预测值整合了多尺度特征、平滑趋势与跨变量交互信息。
整体流程示例:
以电力需求预测(M=8,L=96,T=192)为例:
- 多尺度嵌入:每个变量的96小时序列被分割为24小时和48小时两种尺度,经线性嵌入(如24→64维,48→128维)后压缩为统一维度512,生成潜在向量 X e m b e d ∈ R 8 × 512 X_{\mathrm{embed}}\in\mathbb{R}^{8\times512} Xembed∈R8×512。
- 特征分解: X e m b e d X_{\mathrm{embed}} Xembed分解为平滑分量 X s X_s Xs和残差 X r X_r Xr,分别输入MLP层。
- MLP处理:Intra层学习每个变量的日内周期,Inter层建模温度与需求的关联,残差连接确保关键信息不丢失。
- 投影输出:最终潜在向量经投影层生成未来192小时的8变量预测值 X ^ ∈ R 8 × 192 \hat{\mathcal{X}}\in\mathbb{R}^{8\times192} X^∈R8×192。
通过这一流程,PatchMLP将多尺度局部特征、噪声鲁棒性分解与跨变量交互有机结合,实现了对复杂多元时间序列的高效建模与精准预测。
5 实验(Experiments)
5.1 实验设计与评估总结
数据集(8个)
| 数据集名称 | 领域 | 来源/描述 |
|---|---|---|
| Solar-Energy | 能源 | 太阳能发电量数据 (Lai et al., 2018) |
| Weather | 气象 | 多变量气象指标(温度、湿度等) |
| Traffic | 交通 | 道路传感器记录的交通流量数据 |
| ECL | 电力 | 电力消耗数据(Wu et al., 2021) |
| ETTh1/ETTh2 | 电力变压器 | 电力变压器油温监测数据(每小时采样,Zhou et al., 2021) |
| ETTm1/ETTm2 | 电力变压器 | 电力变压器油温监测数据(每15分钟采样,Zhou et al., 2021) |
基线模型(10类)
| 模型类型 | 模型名称 | 描述 |
|---|---|---|
| Transformer | iTransformer | 基于倒置Transformer的时序预测模型 (Liu et al., 2023) |
| PatchTST | Patch化的时序Transformer (Nie et al., 2022) | |
| Crossformer | 跨维度依赖建模的Transformer (Zhang & Yan, 2022) | |
| FEDformer | 频率增强分解Transformer (Zhou et al., 2022) | |
| CNN | TimeNet | 基于卷积网络的时序建模 (Wu et al., 2022) |
| SCINet | 样本卷积与交互网络 (Liu et al., 2022a) | |
| MLP | Timemixer | 多尺度混合MLP架构 (Wang et al., 2024) |
| DLinear | 简单线性分解MLP (Zeng et al., 2023) | |
| TiDE | 时间序列密集编码器 (Das et al., 2023) | |
| RLinear | 鲁棒线性模型 (Li et al., 2023a) |
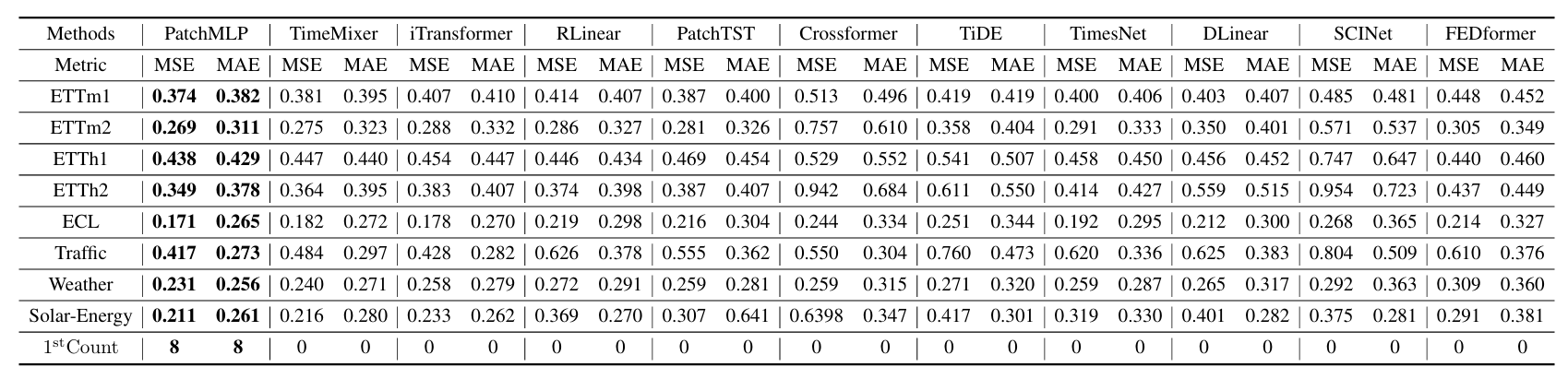
表1:长期时间序列预测任务的结果。对于所有基线,我们坚持使用输入序列长度为96的iTransformer设置。我们在不同的预测范围内对一系列竞争模型进行了比较。所有结果都是来自4个不同预测长度的平均值,即{96,192,336,720}。较低的MSE或MAE表示较好的预测,我们用黑体字表示最佳结果。
5.2 消融实验
9遵循传统的分解方法,即先对时间序列进行分解,然后进行嵌入,然后分别处理趋势和季节分量的预测。
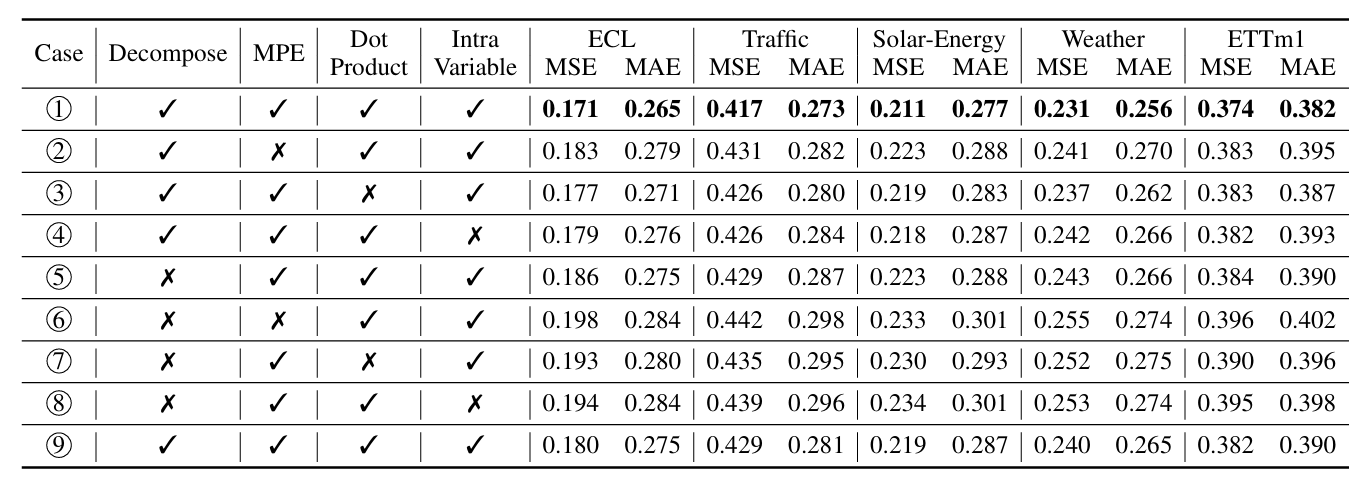
表2:PatchMLP消融。我们逐个替换PatchMLP的组件,并探索不同mlp的性能。所有的结果都是对4个不同的预测长度进行平均。
6 结论(Conclusions)
本文针对长期时间序列预测(LTSF)任务中Transformer架构的局限性展开研究,提出了一种创新的基于Patch的多层感知器(PatchMLP)。传统Transformer因自注意力机制的排列不变性和噪声敏感性,难以有效捕捉长期依赖关系。
PatchMLP通过引入多尺度补丁机制,将时间序列分割为局部块并嵌入潜在空间,结合移动平均分解平滑分量与噪声残差,减少冗余特征与噪声干扰。同时,其独特的通道混合策略通过跨变量交互增强语义信息交换,解决了传统“通道独立”策略的不足。
实验证明,PatchMLP在多个真实数据集上超越现有Transformer、CNN及MLP模型,验证了简化架构与多尺度建模的有效性。该研究不仅挑战了复杂模型在LTSF中的必要性,还强调了跨变量交互与可解释性设计的重要性,为未来开发高效、轻量且面向实际问题的时间序列预测方法提供了新方向。

















 30
30

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









