







| 基本信息 | 发表刊物 | ICLR2024 | 发表年份 | 2024 | 第一完成单位(国内) | 清华大学软件学院 |
| 作者 | 刘勇,胡腾阁,张浩然,吴海旭,王士玉,马林涛,龙明生 | |||||
| 关键词(中文) | 无 | |||||
| 关键词(英文) | 无 | |||||
| 论文内容 | 解决的问题(如有实际应用场景请说明) | 传统Transformer将同一时间步具有不同物理意义的数据点嵌入为一个token,导致重要的多变量相关性丢失; 单个时间步形成的token由于感受野过于局部,无法有效捕捉到有用的信息,尤其是在时间上未对齐的事件; 序列的变化受到顺序的显著影响,但传统Transformer采用的置换不变注意力机制在时间维度上的应用不当,削弱了模型捕捉关键序列表示的能力。 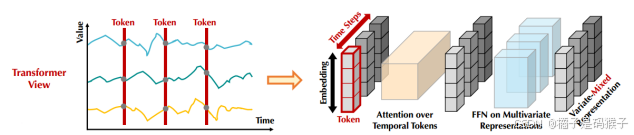 | ||||
| 解决问题的方法(采用什么模型框架等) | iTransformer: 将单个变量的整个时间序列视为一个Token; 将self-attention和FNN职责倒置。 (self-attention捕获变量之间的相关性;FNN来进行序列内的全局表示) 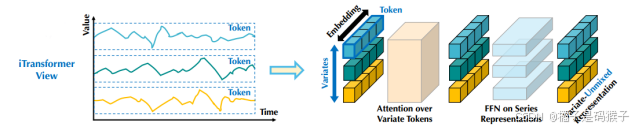 整体结构: 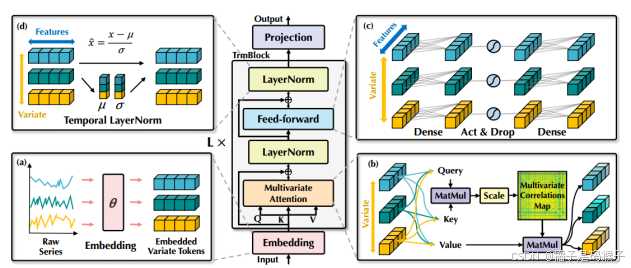 (a)Embedding: 将一个变量的整个时间序列嵌入为一个token 具体实现:将(B,T,N)转为(B,N,T)然后再通过一个linear层进行Embedding (b)self-attention: 将每个变量的时间序列序列视为独立的过程,提取全面的时间序列表示; 采用线性投影获取Q、K、V的值,计算前Softmax分数,揭示变量之间的相关性 (c)FFN: 包括了两个Dense层(全连接层),以及中间的激活和Dropout层 ·Dense层:第一层对历史时间数据编码,第二层解码进行预测 ·Act & Drop:激活函数引入非线性,学习更复杂的特征;Dropout防止过拟合,增强模型泛化能力 FNN对变量的整个序列进行token表示,对每个变量(variate)独立作用,可以用于复杂的时间序列。 (d)layer normalization: 传统Transformer对同一时间戳的多变量表示进行归一化处理,逐渐将变量彼此融合。一旦收集的时间点不代表相同的事件,将在非因果或延迟过程中引入交互噪声。 本模型中,归一化用于单变量的时间序列表示。所有序列作为token被归一化为高斯分布,由不一致测量引起的差异就可以被减少。 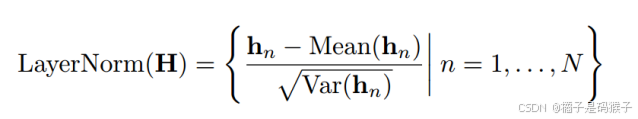 | |||||
| 仍旧存在的问题(注明论文中说明的问题或自己认为的问题) | 高维数据的计算复杂度: 通过反转架构在多变量时间序列上表现出色,但由于注意力机制的二次复杂度,在处理高维度数据时,计算开销依然很大,尤其是当变量数(即通道数)较多时,这种开销会显著增加 | |||||
| 实验内容 | 实验采用的数据集 | 7个广泛用作基准的数据集: ECL、ETT(4个子集)、Exchange、Traffic、Weather、Solar-Energy、PEMS(4个子集) 一个真实应用程序的数据集: 支付宝在线交易的的服务器负载数据(Market)(6个子集) | ||||
| 数据集内容是否和待解决问题模型对应 | 遵循TimesNet 中的数据处理和训练-验证-测试集的划分协议。训练集、验证集和测试集严格按照时间顺序划分,以确保没有数据泄漏问题。 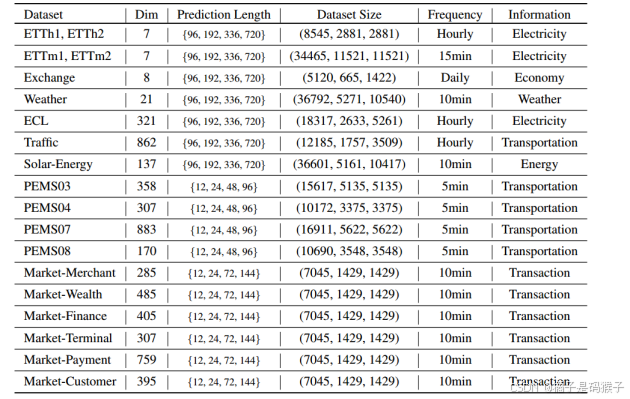 | |||||
| 实验是否涉及实际应用场景 | 是,数据集的选取反映了对实际应用场景的预测,尤其是对一组真实应用程序的Market数据集的选择。 该数据集记录了2023年1月30日至2023年4月9日期间支付宝在线交易的分钟采样服务器负载,变量数量从285到759不等。 | |||||
| 实验采用的对比方法 | 选择了10个公认的预测模型作为基准进行预测准测性的比较; 选择将模型应用于其它基于Transformer的模型测评通用性; 通过组件消融验证模型组件的有效性。 | |||||
| 实验任务 | 1、评估模型的预测性能 2、评估模型框架的通用性 3、消融实验探讨模型不同组件的有效性,验证其合理性 | |||||
| 实验衡量指标 | MSE、MAE | |||||
| 实验说明所提出方法的优点 | 1、在处理高维时间序列预测时表现突出,能够更准确地捕捉和预测高维数据的复杂关系 2、能够更好地处理如PEMS数据集中那样极度波动的时间序列(优于PatchTST) 3、在捕捉多变量相关性方面优于Crossformer 通过反转架构自然地融合了时间和多变量信息,避免了CrossFormer基于时间不对齐的多变量切片的交互带来的不必要的噪声。 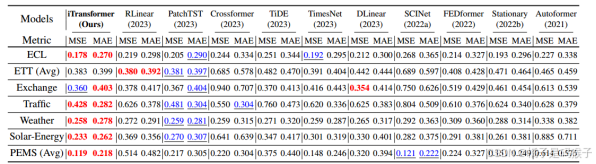 4、提高了计算效率与未见量的泛化能力 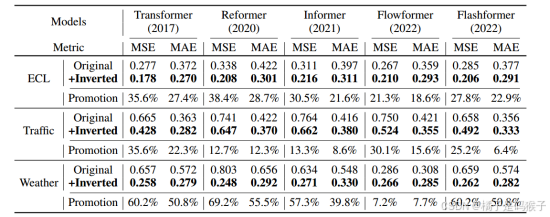 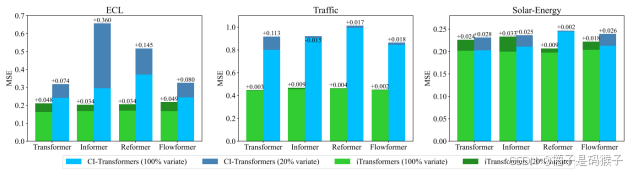 5、可以从扩展的回看窗口中受益,从而获得更精确的预测 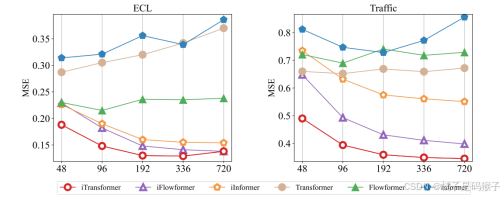 | |||||
| 思考内容(阅读论文后自己思考填充) | 论文的主要优点 | iTransformer将每个独立的时间序列视为独立的token,在变量维度上应用自注意力机制来捕捉多变量之间的相关性。 通过分离时间和变量维度,有助于获得更精确的多变量关联表示,同时利用层归一化和前馈网络学习到更优的序列全局表示。这一改进使得模型在处理多变量时间序列时更加高效和精准。 | ||||
| 论文仍然可以改进的地方是什么 | 部分实验场景的性能劣化 在消融实验中,当在变量维度上采用前馈网络(而不是注意力机制)时,模型在一些数据集上的表现会有所下降,表明在某些场景下,模型在捕捉多变量相关性方面可能存在不足。 在增大回看窗口时的局限性 尽管iTransformer在增大回看窗口时能有所提升,但某些Transformer变体在窗口增大时的效果并不明显,这可能归因于模型注意力分配的分散性,从而导致对增长的输入信息利用不足。 | |||||
| 选择读这篇论文的原因是什么 | 比较经典,对多变量时间序列预测中变量间的关系进行合理判断。 | |||||
| 以此论文为出发点,如果需要你做一篇和其相关的顶会论文,你需要的资源是什么?数据,硬件,技术支持等 | 需要相关数据集 | |||||
| 所选这篇论文和目前自己在做的内容能够想到的相关点 | 可以借鉴它的架构(Attention+FNN) | |||||
| 其他想要补充说明的内容 | 无 | |||||

















03-13
 1364
1364
1364
04-11
638
638
09-15
6万+
6万+
03-02
10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









