






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
摘要
本文提出了一种基于神经网络的(NN-based)数据驱动迭代学习控制(ILC)算法,用于具有未知模型和重复任务的非线性单输入单输出(SISO)离散时间系统的跟踪问题。控制目标是使系统的输出在每次迭代过程中跟踪参考轨迹。因此,在每次迭代过程的每个相对时间点上,使用广义回归神经网络(GRNN)作为估计器来解决系统的关键参数,并使用径向基函数神经网络(RBFNN)作为控制器来解决控制输入。与传统的ILC算法相比,两个复杂的求解过程,即动态线性化和准则函数最小化,被替换并简化为GRNN和RBFNN的迭代训练。所提出的算法是即插即用的,并使用点对点方法来计算系统迭代的每个相对时间点的控制输入,将系统的跟踪误差驱动到接近零。此外,证明了在所提出的控制算法下系统的跟踪误差是一致最终有界的。最后,通过数值示例展示了控制算法的有效性和优越性,并通过无人车的路径跟踪实验进一步验证了其实用性。
1. 引言
对于具有重复运行模式的单输入单输出(SISO)离散时间系统的轨迹跟踪控制的目标是使系统的输出在每次迭代中接近参考轨迹(刘 & 魏,2014)。众所周知,通过重复迭代纠正错误,迭代学习控制(ILC)可以提高跟踪性能(宋等,2016)。将数据驱动思想(Djordjevic等,2023年;戈,2017年;魏等,2022年;张等,2011年;张等,2017年)引入ILC可以有效地克服由复杂系统环境和模型不确定性引起的控制器设计困难。特别是随着机器学习和大数据方法的发展,基于数据而不是模型的自学习优化决策,即数据驱动ILC,在无人系统(陈等,2022年;普尔温和德安德烈,2011年)和安全控制(沈和李,2021年;尹等,2022年)等人工智能领域得到了充分肯定和广泛研究。
目前,对数据驱动ILC的研究主要集中在三个方向:
第一方向是通过整合基于数据的方法来增强传统的系统识别和控制方法。具体而言,ILC可用于基于先验知识离线或在线构建模型,或者与传统控制方法结合设计控制器。这个想法启发了一些研究。李等(2020年)引入了一种将ILC和模型预测控制(MPC)相结合的跟踪控制方法,以解决由于模型不确定性而导致的控制过程收敛缓慢的问题。陈等(2023年)设计了一种交叉耦合ILC(CCILC)方法和具有可变遗忘因子的变增益ILC方法(VFF-VGILC),以解决双轴机构控制中的轮廓误差问题。针对系统中不同试验长度的问题,管等(2023年)提出了一种反馈辅助的PD型ILC算法,庄等(2022年)开发了一种具有原始-对偶内点方法的ILC算法。如果从数据驱动的角度研究控制问题,就可以有效增强控制系统的鲁棒性。然而,上述方法旨在解决具有已知或部分已知先验知识的系统的特定控制问题。因此,考虑开发一个即插即用的数据驱动算法更加值得。
第二个方向是通过与无模型自适应控制(MFAC)结合,发展ILC,统称为MFAC-ILC(Madadi & Soeffker,2018)。MFAC-ILC主要利用MFAC的动态线性化(DL)方法和最优自适应控制的概念。具体而言,MFAC-ILC将首先利用迭代轴中的窗口信息和伪偏导数(PPD)或伪偏雅可比矩阵(PPJM)的概念构建虚拟等效的DL数据模型。然后,基于等效模型,将设计控制输入准则函数进一步解决控制器。通过使用这种设计思想,已经提出了许多研究成果,如紧凑格式DL-MFAC-ILC(CFDL-MFAC-ILC)(林等,2019年)、部分格式DL-MFAC-ILC(PFDL-MFAC-ILC)(余等,2022a)、完全格式DL-MFAC-ILC(FFDL-MFAC-ILC)(王等,2022年)和比例积分-ILC(PI-ILC)(王等,2013年)。毫无疑问,MFAC-ILC是一种在新框架下的数据驱动控制方法。然而,值得注意的是,MFAC-ILC仍然使用最小二乘法或投影算法来处理未知的函数关系。算法中的超参数不容易调整。因此,MFAC-ILC本身必然会产生错误,这将对控制系统的收敛性和稳定性产生很大影响。因此,我们需要考虑如何简化控制器或估计器的设计,同时仍然保证所设计算法的收敛性。
第三个方向是通过与神经网络集成,发展ILC,统称为基于神经网络的ILC(NN-ILC)(侯等,2023年;刘等,2022年)。实际上,随着神经网络技术的成熟,使用神经网络解决非线性系统的控制问题已成为一个新的研究热点(陈等,2020年;伊扎德巴赫等,2022年;郭和杨,1997年;李等,2017年;倪等,2013年;魏和杜,2023年;赵等,2014年)。现有研究表明,神经网络可以完全嵌入ILC,因为神经网络也具有迭代运算模式。NN-ILC主要利用函数逼近理论和基于神经网络的自适应控制。
基于NN-ILC设计方法,取得了许多研究成果。Yu等人(2022b)提出了一种基于反向传播神经网络(BPNN)的ILC策略,利用BPNN描述了基于磁形状记忆合金(MSMA)的执行器中的滞后现象。Dong等人(2023)提出了一个用于车道变换的ILC框架,利用BPNN建立了交通模型。除了有效利用BPNN外,还有研究成功将RBFNNs和ELMs应用于ILC。例如,Yu等人(2021)提出了一种基于RBFNN的数据驱动ILC方法,用于未知非线性非仿射重复离散时间系统,可以通过更新RBFNN的权重矩阵来自动调整控制器增益。Li等人(2022)提出了一种基于RBFNN的数据驱动安全容错ILC算法,利用RBFNNs来抵御拒绝服务(DOS)攻击,可以通过训练RBFNNs来近似传感器失效函数。Zhou和Li(2021)提出了一种基于极限学习机(ELM)的迭代学习和优化控制方法,用于解决最优控制中的模型-系统不匹配和实时干扰问题。
尽管这些研究已经证明了在ILC中使用神经网络的有效性,但仍然存在一些问题需要解决。第一个问题涉及数据建模。对于一些神经网络,如BPNNs、RBFNNs和ELMs,最明显的特征是它们需要参考输出作为学习的标签。因此,这些神经网络直到控制系统完成每次迭代才开始训练。这个特性也增加了构建数据集的难度,因为一些隐藏变量必须基于先验知识来解决。此外,如果存在异常的参考输出,将严重影响神经网络的建模精度。第二个问题是,尽管这些方法利用了神经网络技术,但仍然依赖于传统的系统建模或控制器设计方案,并没有充分利用神经网络的优势。因此,值得探索一种跟踪控制算法,简化数据集构建的方法,并完全依赖神经网络进行系统建模和控制器求解。
事实上,具有良好非线性拟合性能的GRNNs值得考虑(Specht,1991)。它将样本数据作为后验信息,并通过最大化后验概率估计计算神经网络的输出。GRNN没有需要训练的参数,因此其收敛速度比RBFNN快。GRNN的局限性在于它需要存储和计算所有样本数据。随着数据量的增加,网络结构和计算复杂度将继续上升。然而,与其他模型相比,GRNNs不需要设置参考输出,这使它们特别适合学习特定的隐藏函数关系。
基于以上讨论,本文将提出一种新颖的NN-ILC算法,充分利用GRNNs和RBFNNs在ILC中的优势,提高难以建模的重复SISO离散时间系统的跟踪性能。在该控制算法下,GRNNs将通过估计系统关键参数构建RBFNNs的输入特征集,而RBFNNs将通过优化控制输入准则函数来解决控制输入。主要贡献总结如下。
1. 在DL技术的帮助下,GRNN的输入特征集在迭代轴上构建。GRNN直接充当参数估计器,并通过最小化参数估计准则函数输出PPD的最优估计。与现有的ILC算法相比,该算法简化了数据建模过程,避免了异常输出的影响。
2. 利用GRNN的输出,在迭代轴上构建RBFNN的输入特征集。RBFNN直接充当控制器,并通过最小化控制输入准则函数输出最优控制输入。与传统的ILC算法相比,该算法简化了控制器的设计,并配备了RBFNNs以确保收敛。
3. 迭代操作过程根据相对时间分组,每个相对时间对应一个神经网络组,其中包括一个GRNN和一个RBFNN。每个GRNN或RBFNN都依赖于迭代轴进行自学习/自训练。该算法充分利用了神经网络的优势,实现了点对点控制,并具有开箱即用的特性。
本文组织如下:第2节阐述了问题;第3节提出了控制算法并给出了收敛分析;第4节展示了一个数值模拟示例和一个无人车模拟示例,以验证所提出的控制算法的有效性和实用性;第5节提供了本文的结论。
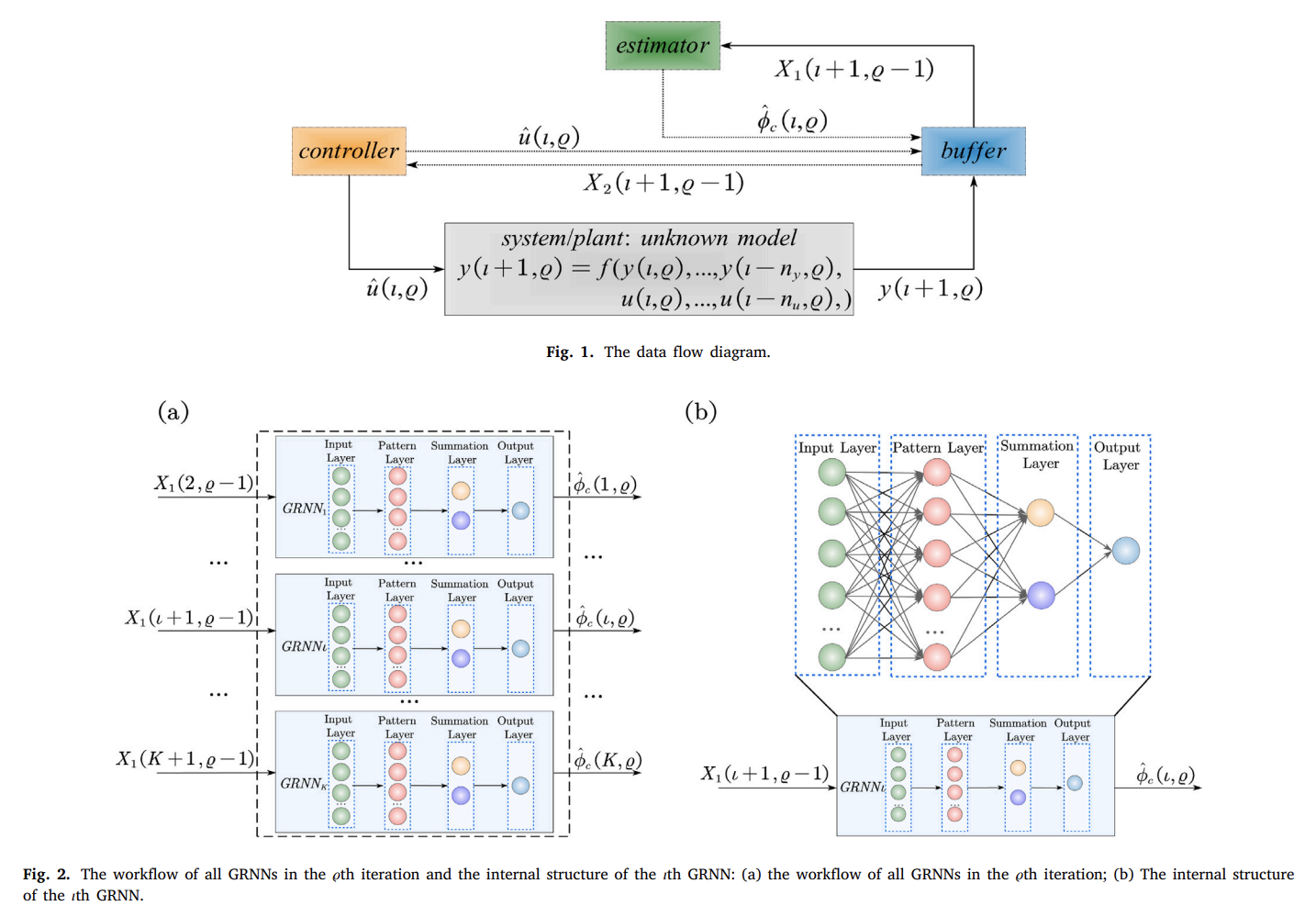
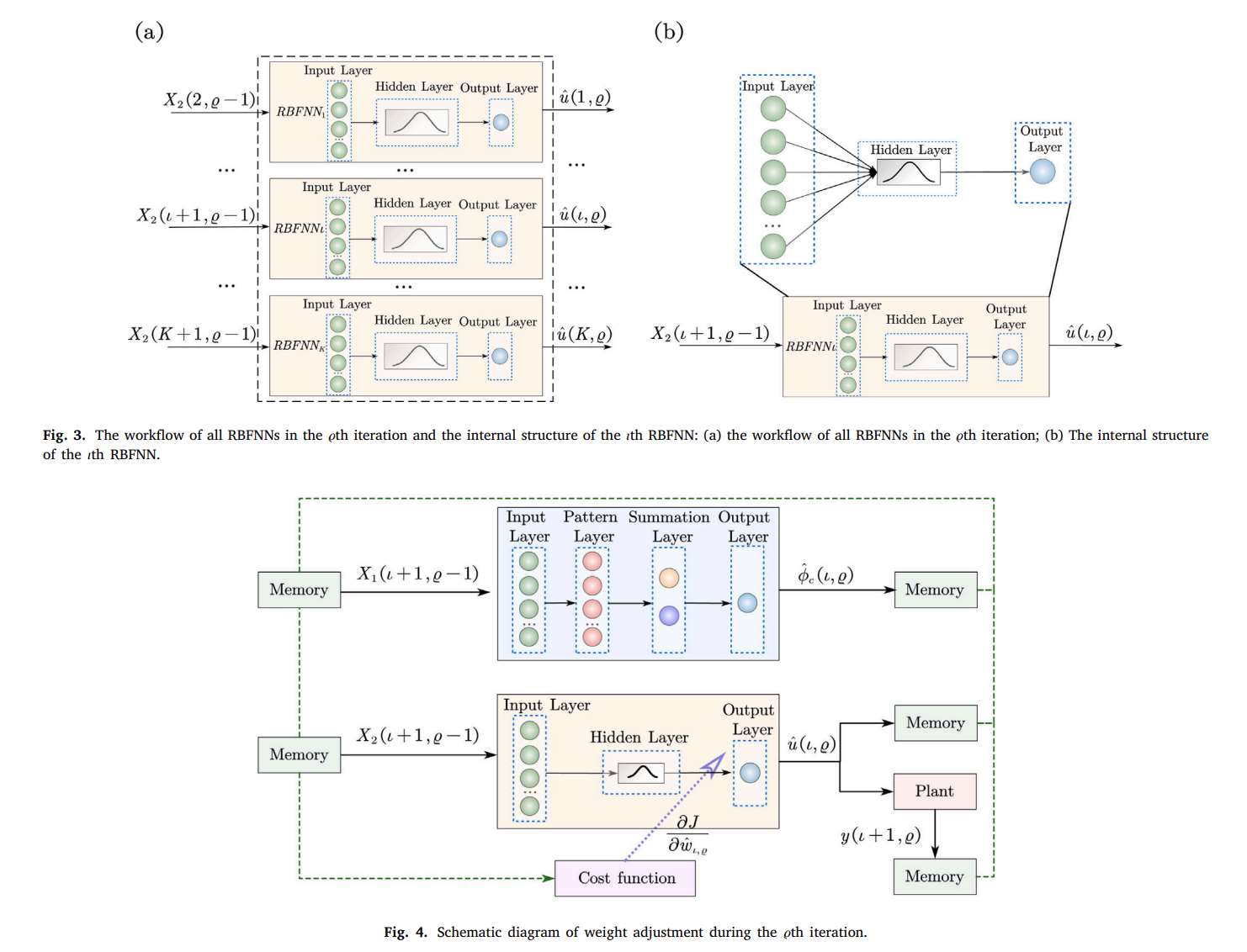
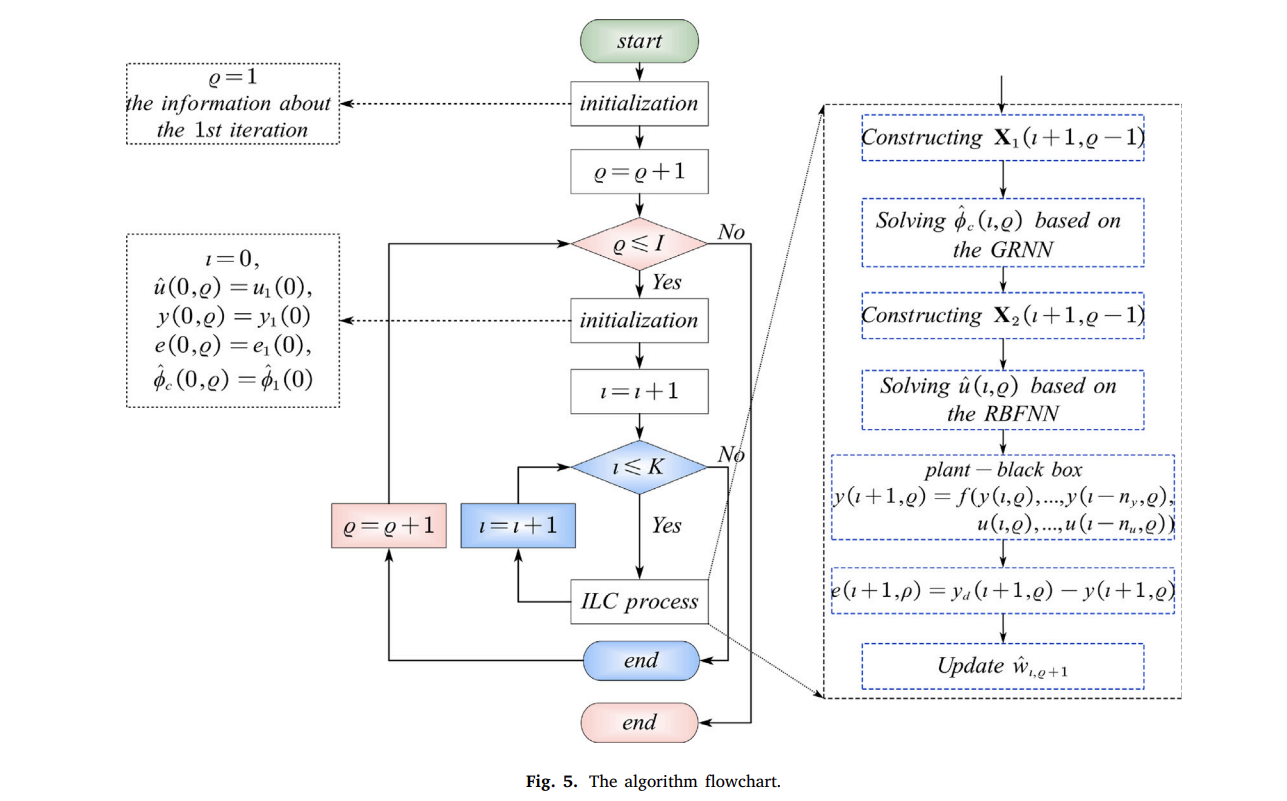
📚2 运行结果
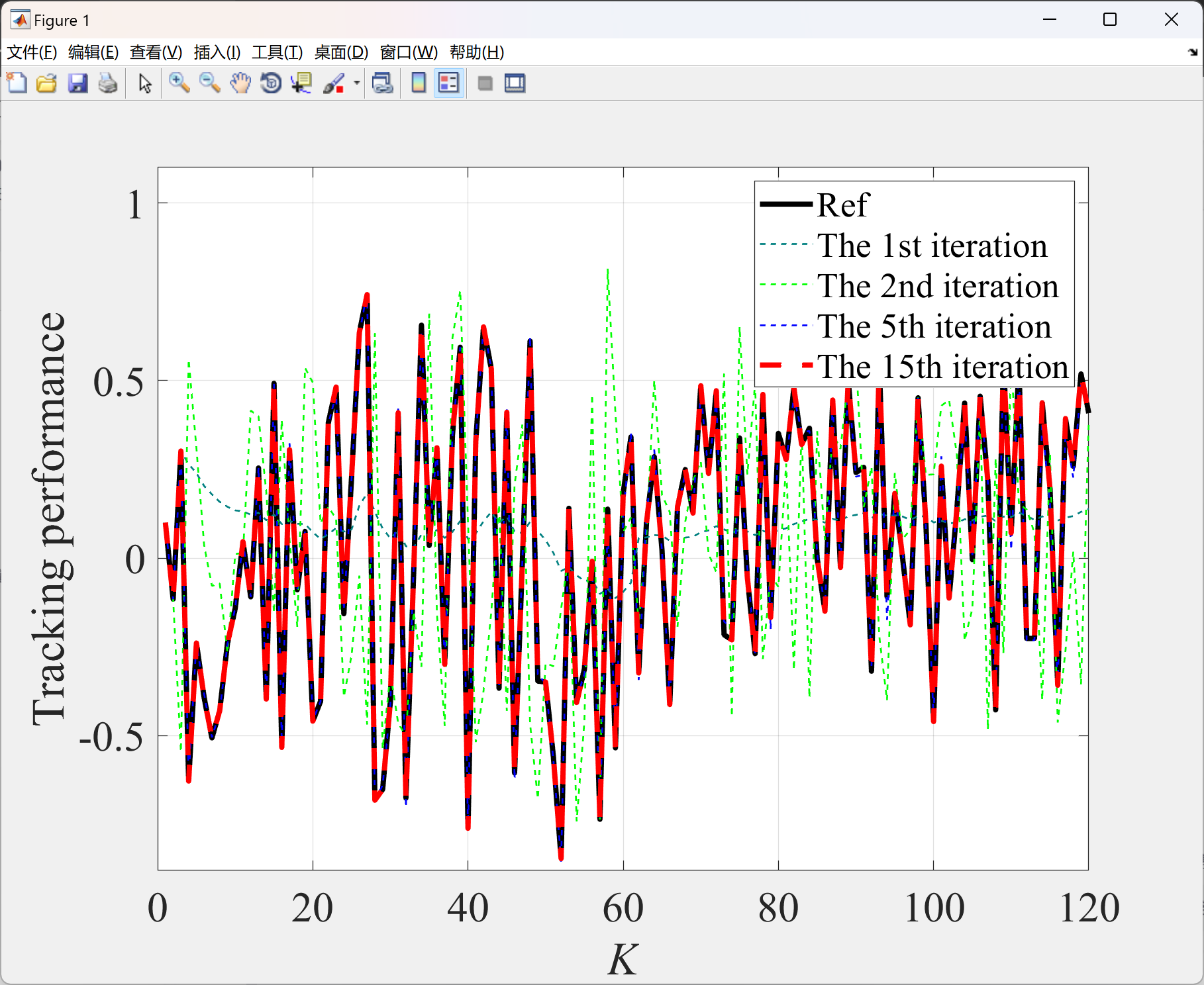
2.1 算例1
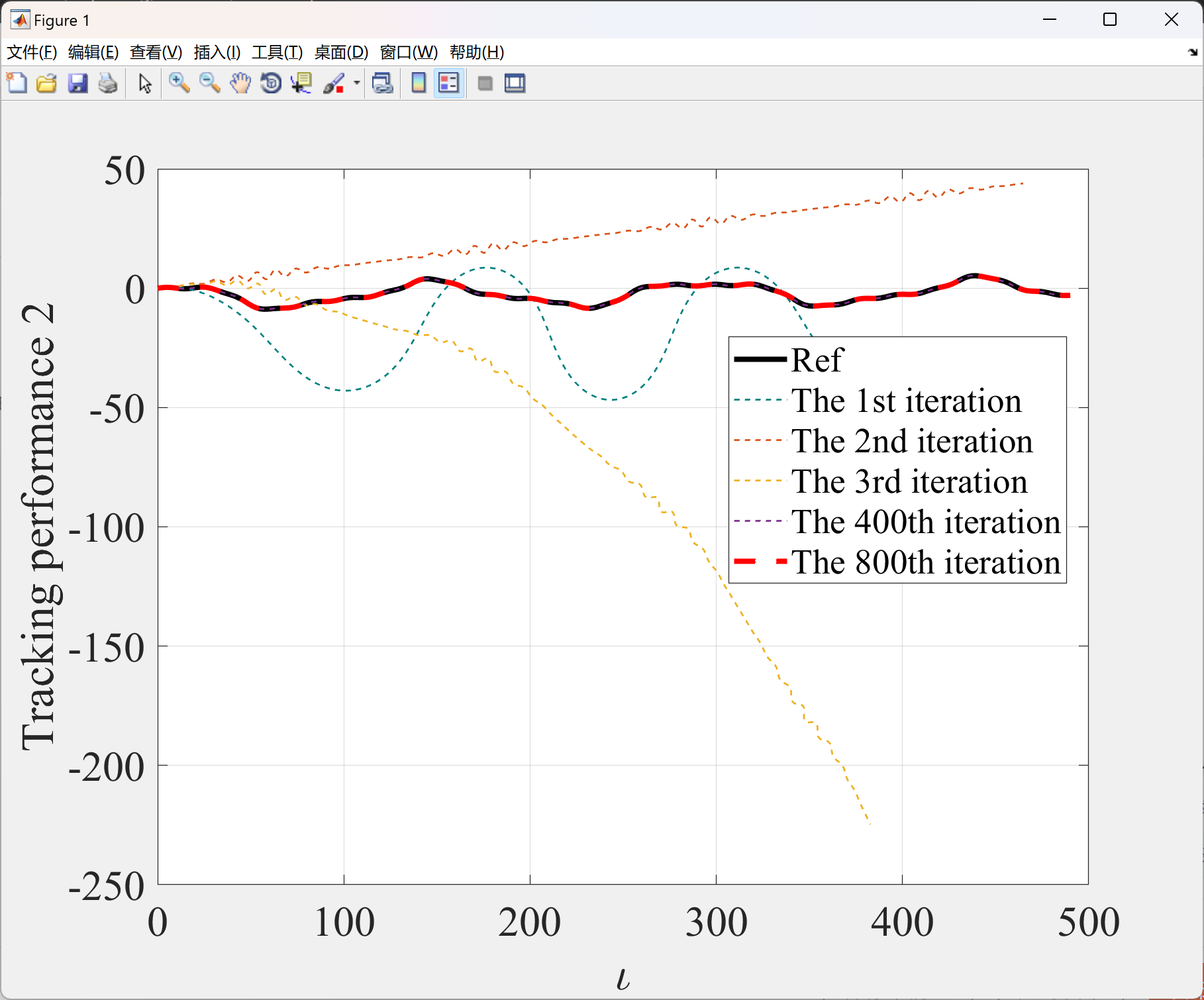
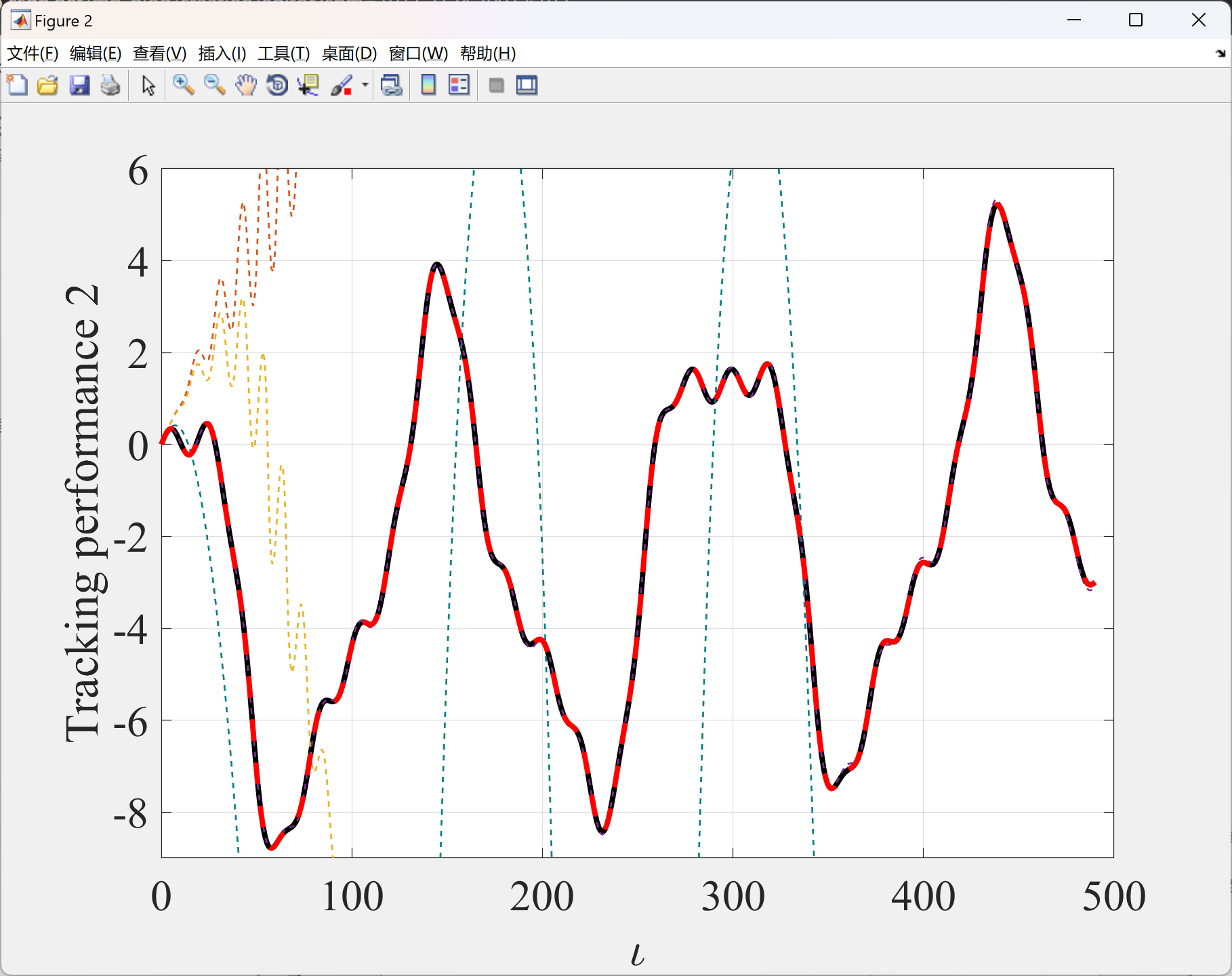
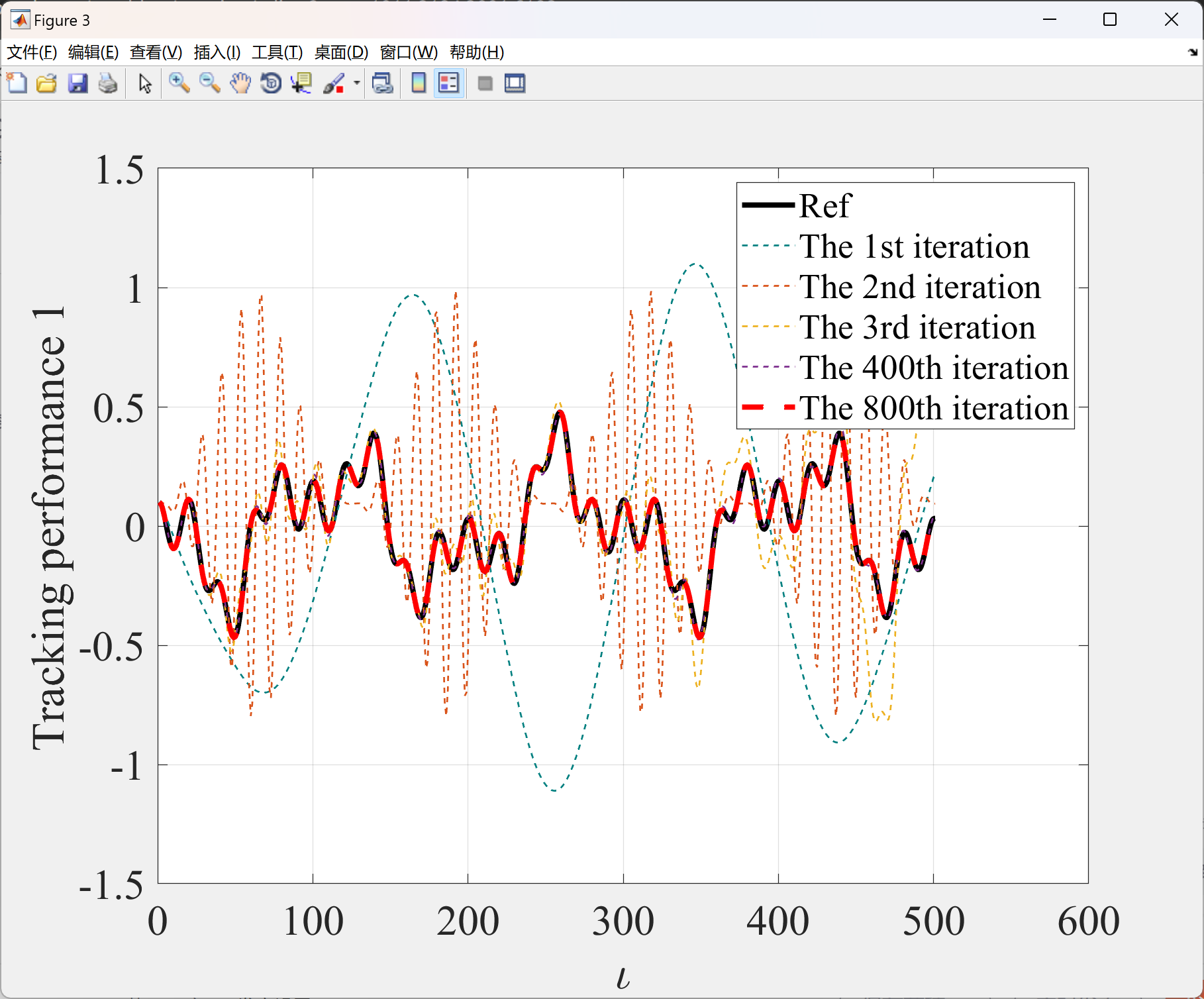
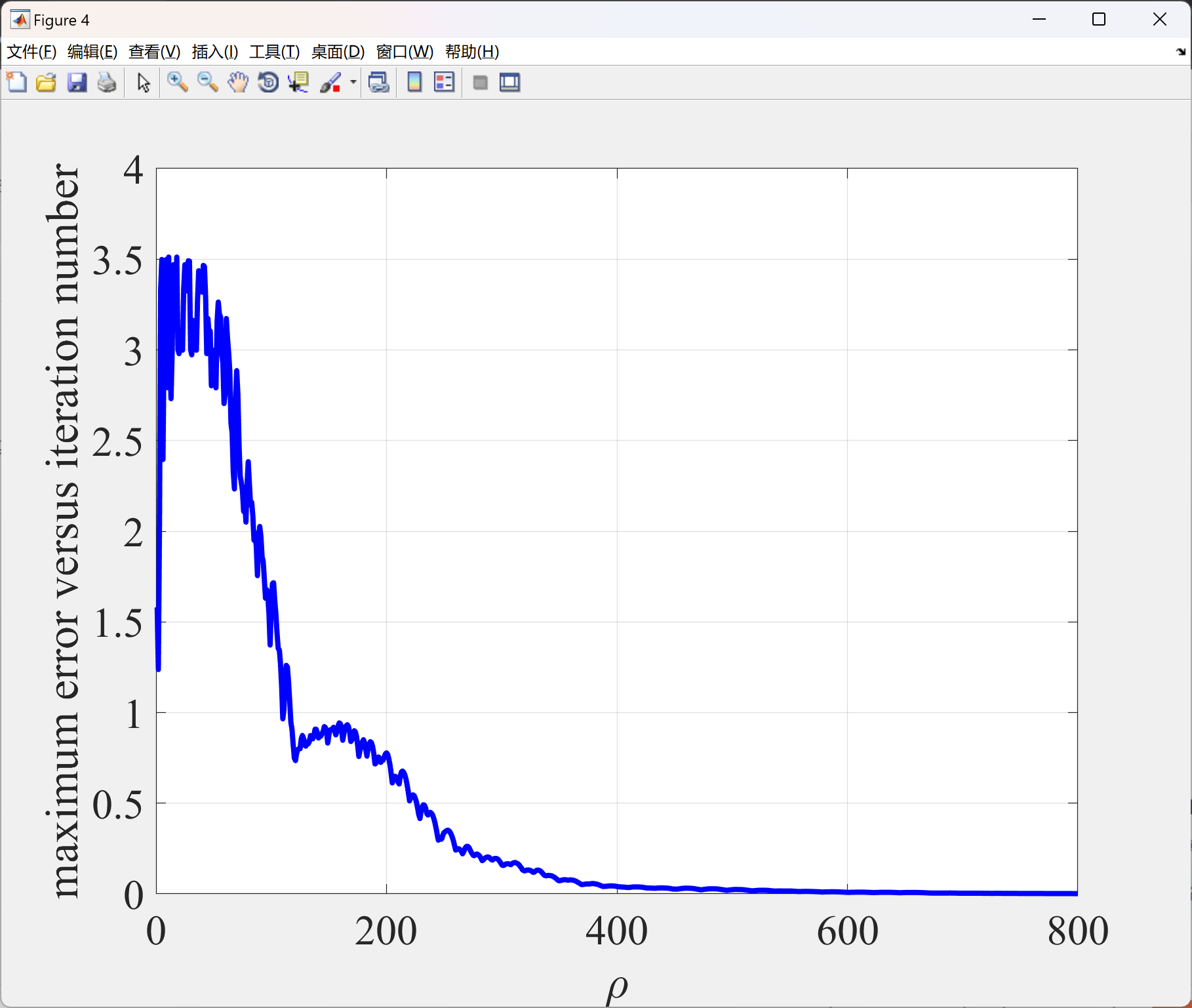
2.2 算例2
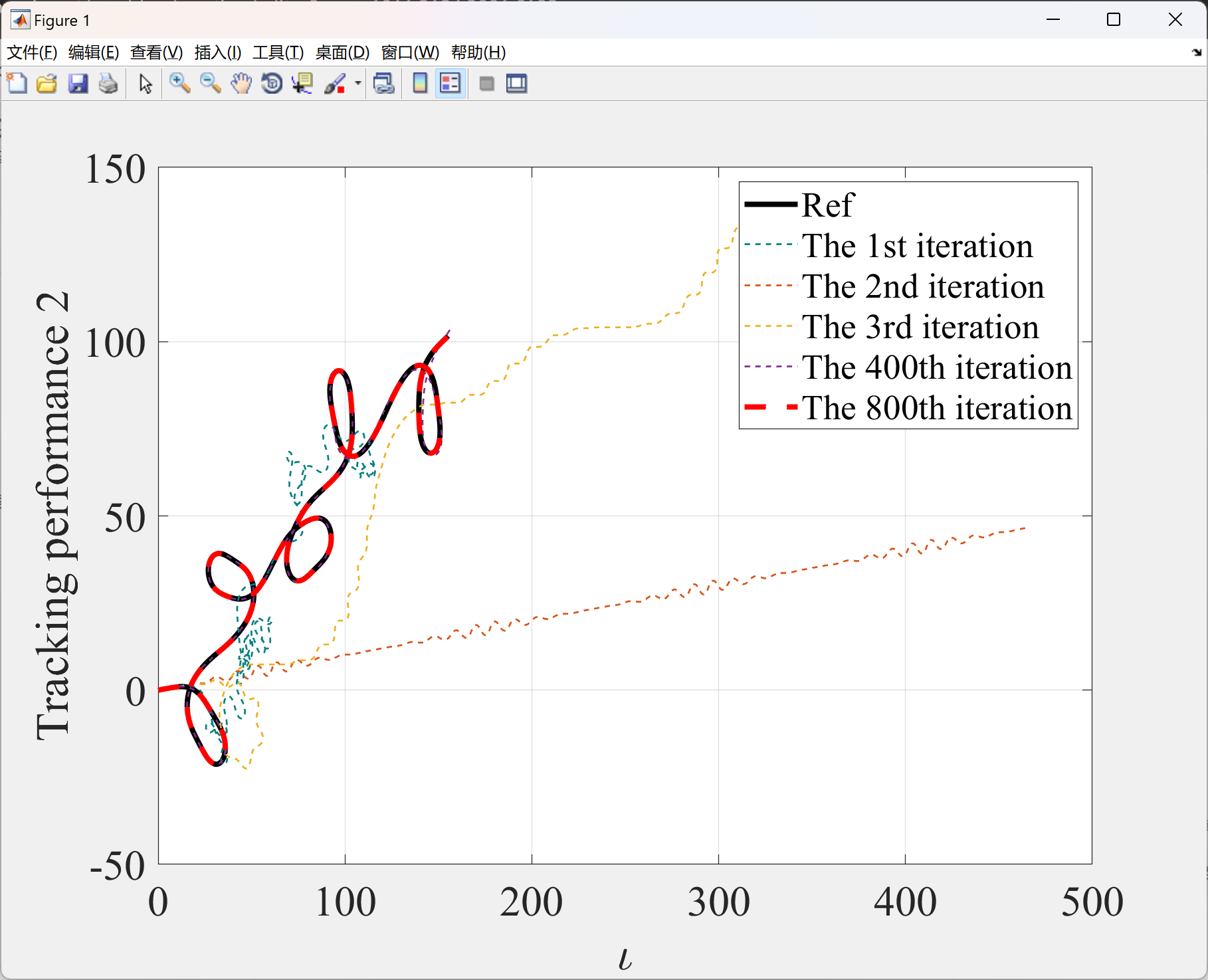
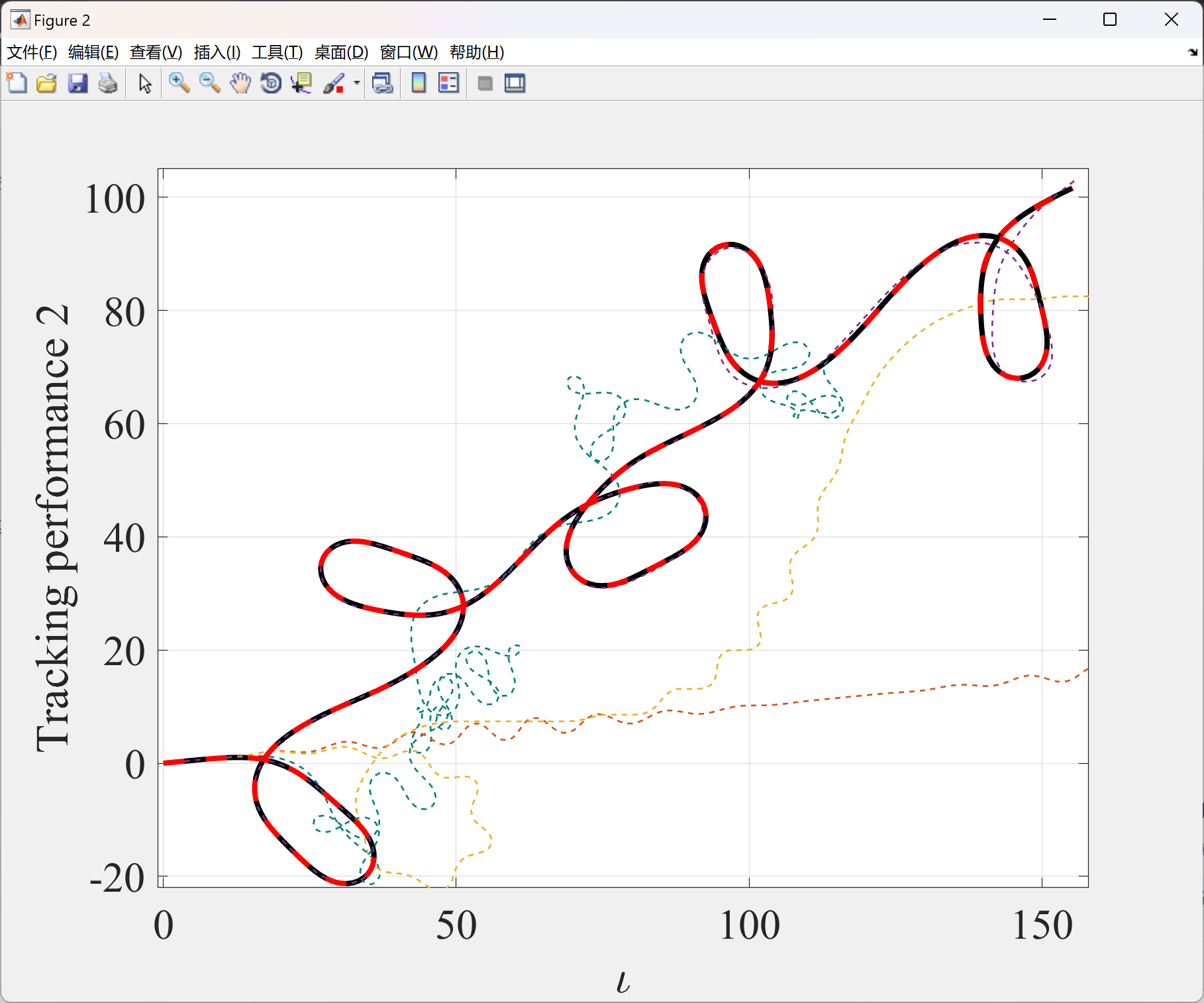
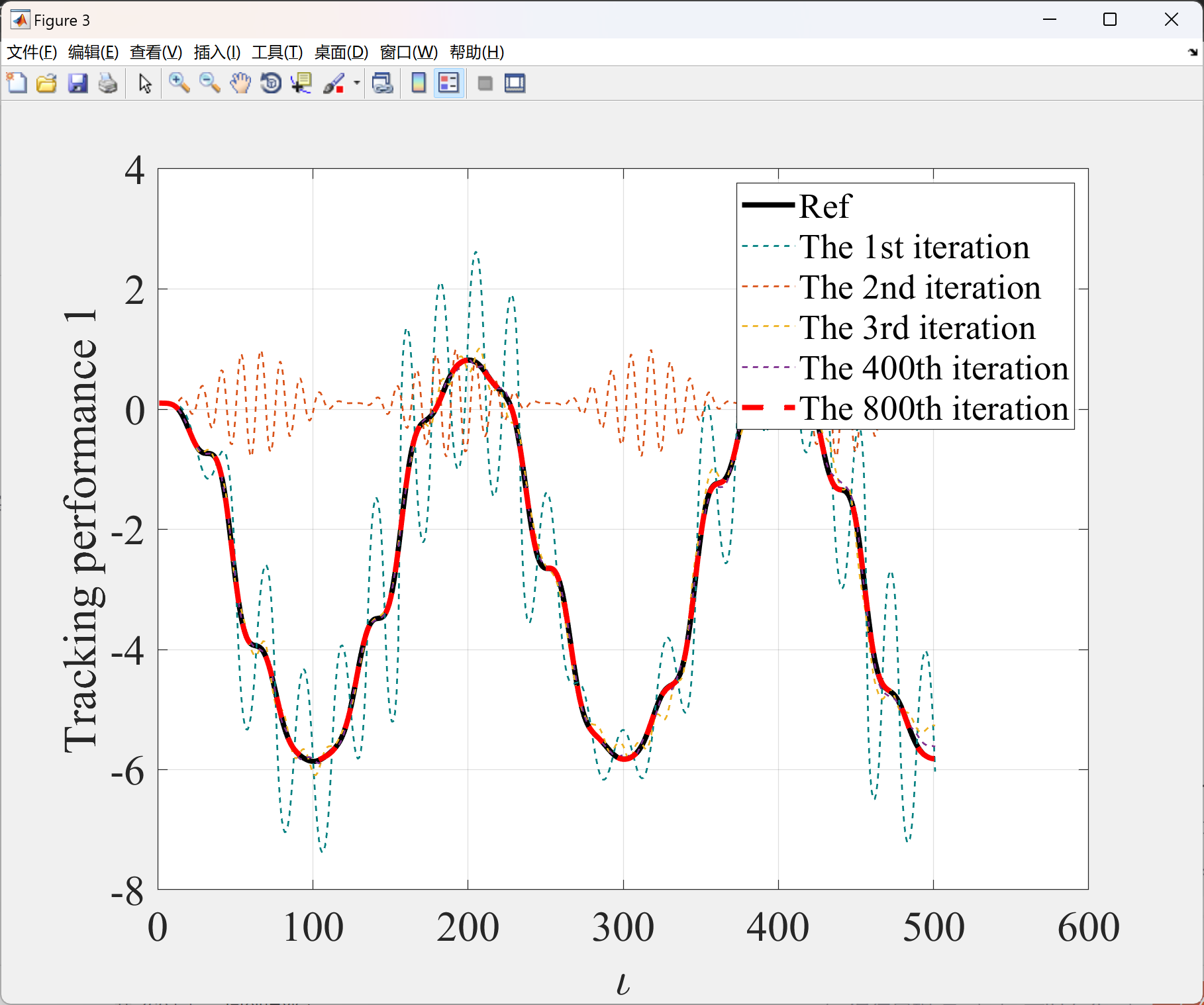
2.3 算例3
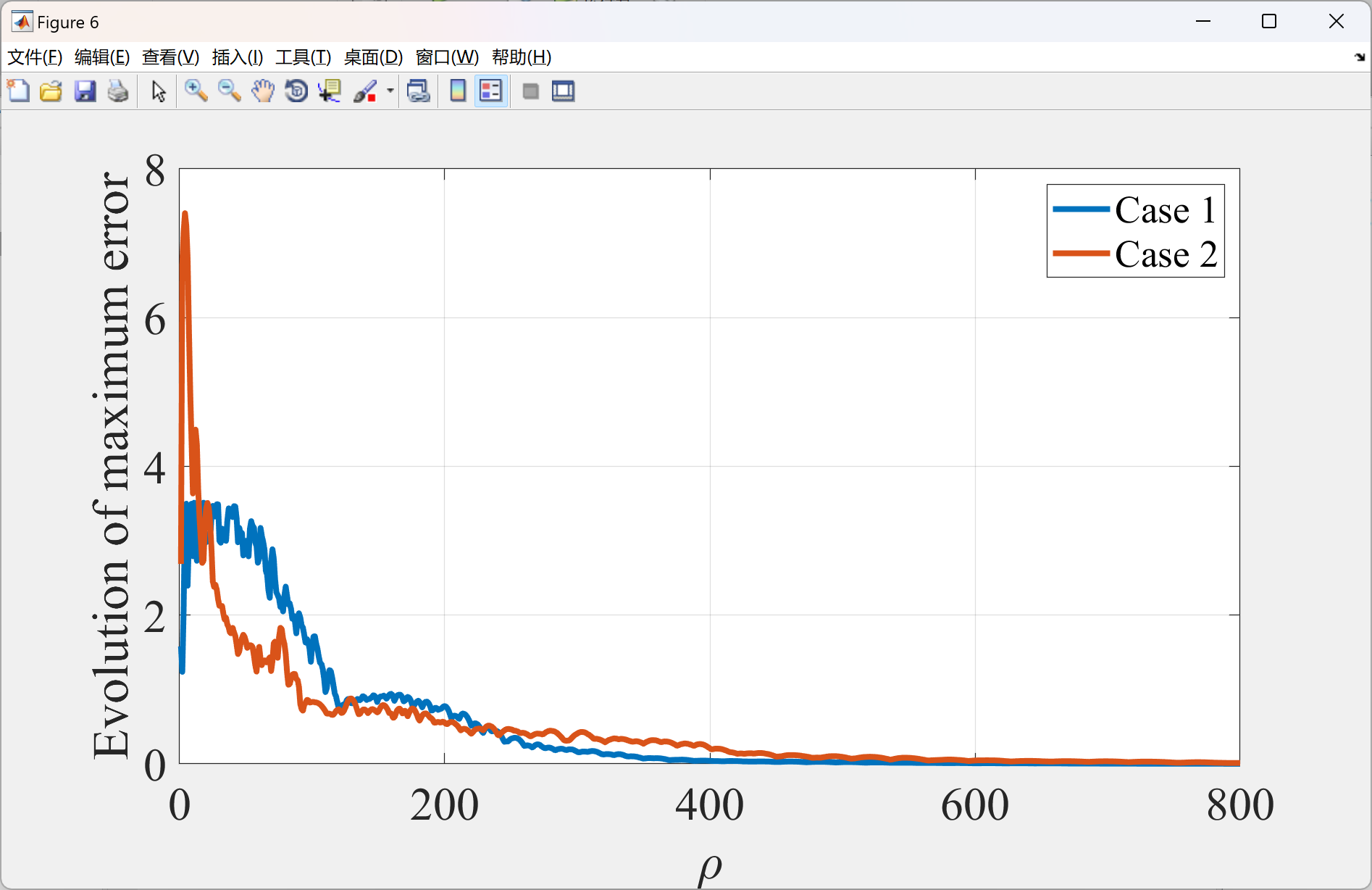
2.4 比较
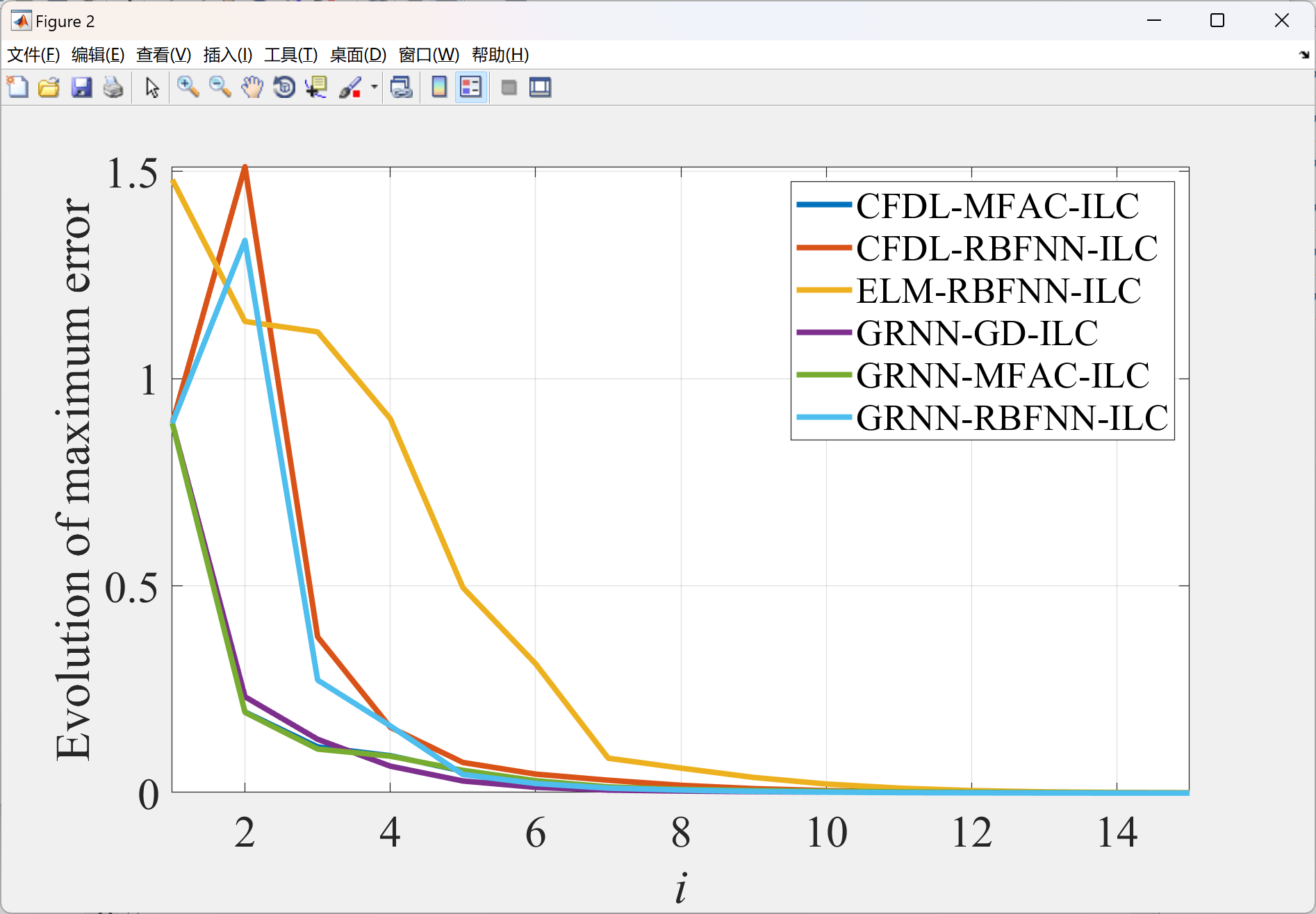
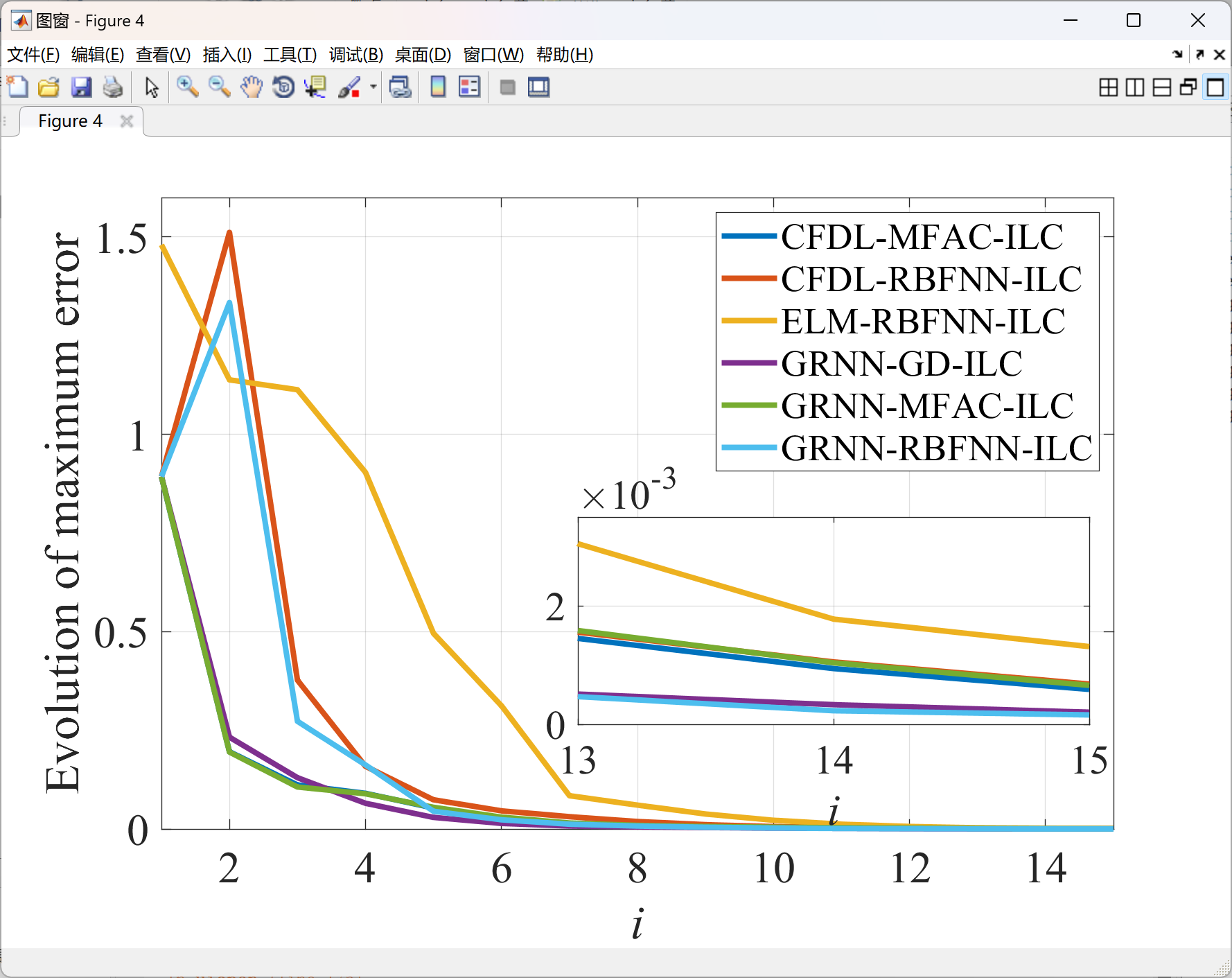
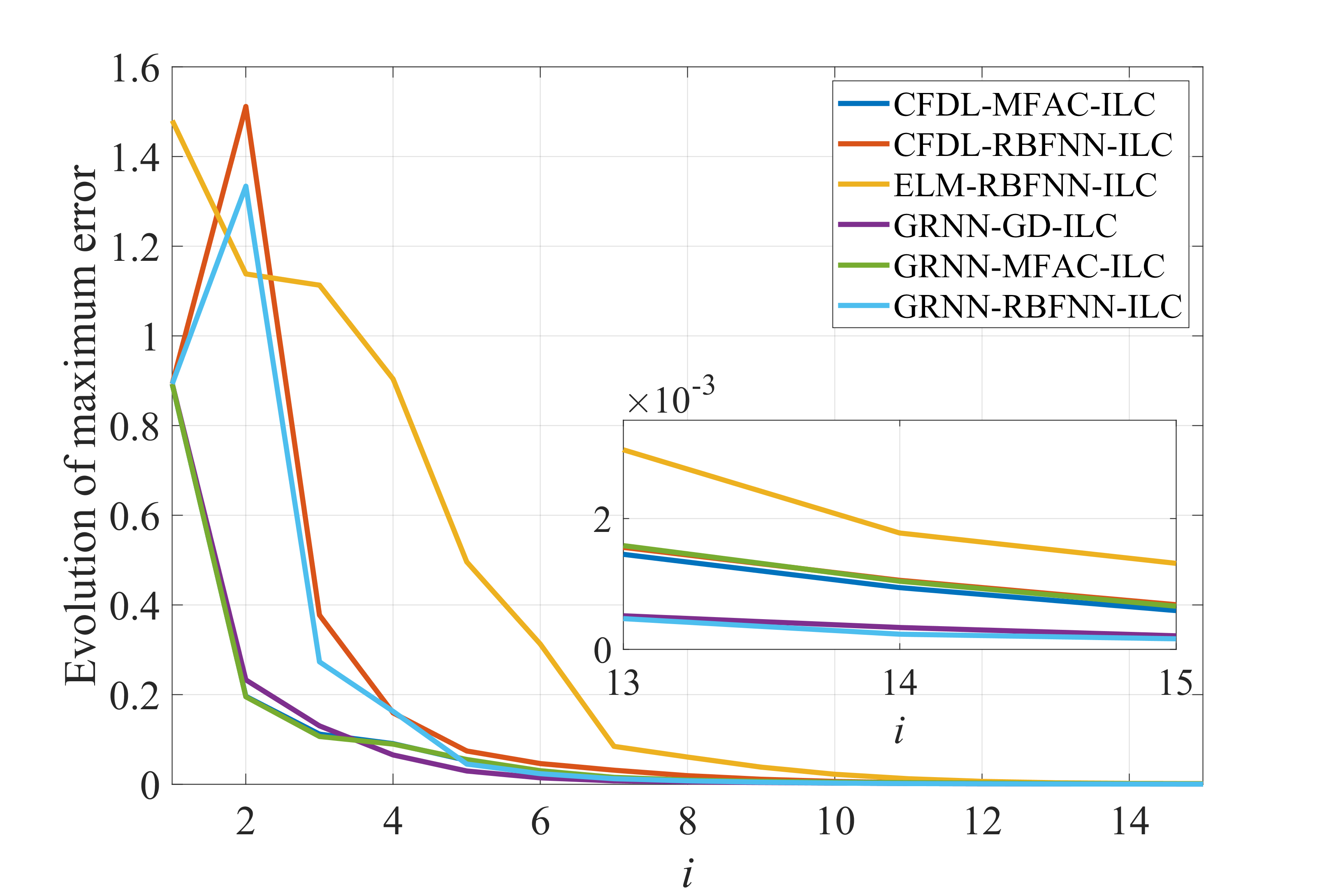
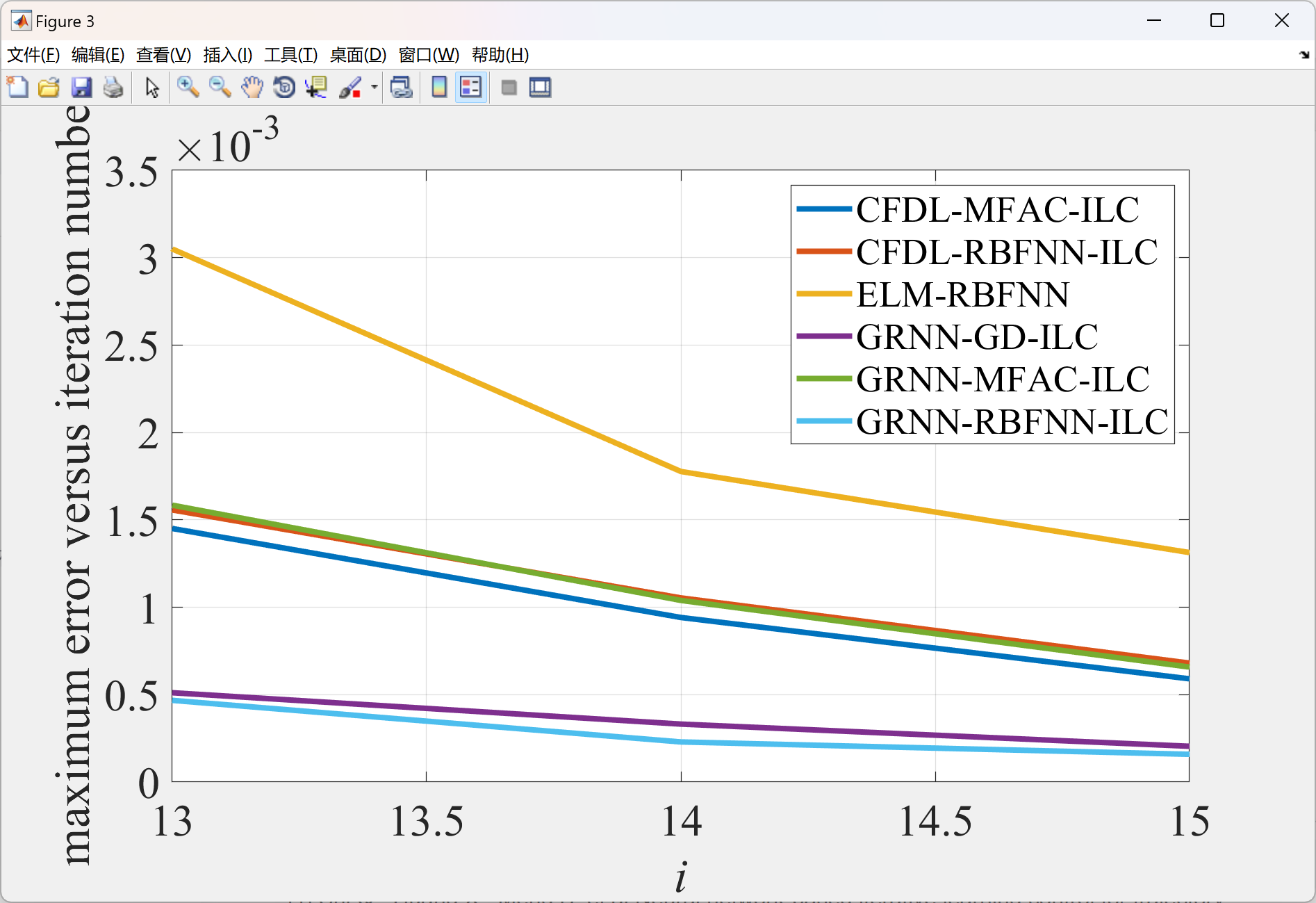
部分代码:
clc
clear
close all
%% 期望轨迹
load pdCASE2.mat
load w1CASE1.mat
load y1CASE2.mat
load y2CASE2.mat
pd = pdCASE2;
w1 = w1CASE1;
y1 = y1CASE2;
y2 = y2CASE2;
% figure
% plot(pd,'r')
% hold on
dt = 0.1;
L= 3;
%% maxmin约束
q_max = 100;
q_min = -100;
MFAC_ILC_max = 100;
MFAC_ILC_min = 0;
cm_11 = 0.01;
rm_11 = 100;
cm_q1 = 0.001;
rm_q1 = 100;
lammd1 = 0.1;
%% 载入信息
load p_i1CASE2.mat
load q_i1CASE2.mat
load Fai1CASE2.mat
load p_i2CASE2.mat
load q_i2CASE2.mat
load Fai2CASE2.mat
p_i1 = p_i1CASE2;
q_i1 = q_i1CASE2;
Fai1 = Fai1CASE2;
p_i2 = p_i2CASE2;
q_i2 = q_i2CASE2;
Fai2 = Fai2CASE2;
p1_i1 = p_i1;
q1_i1 = q_i1;
MFAC_ILC11_i1 = Fai1;
p1_i2 = p_i2;
q1_i2 = q_i2;
MFAC_ILC11_i2 = Fai2;
k_length = length(p1_i1)-1;
p6_1(1, 1) = 0;
p6_2(1, 1) = 0;
%% 第一次迭代
for k = 1:1:k_length
% 输入
q(1, k) = q1_i2(k);
% 输出
p(1, k) = p1_i2(k);
p6_1(1, k + 1) = p6_1(1, k) + 10 * cos( p(1, k) ) * dt;
p6_2(1, k + 1) = p6_2(1, k) + 10 * sin( p(1, k) ) * dt;
p(1, k + 1) = p1_i2(k + 1);
% 伪雅可比矩阵
MFAC_ILC(1, k) = MFAC_ILC11_i2(k);
fenzi_11(1,k) = 0;
fenmu_11(1,k) = 0;
W_i_k_q1(2,k) = w1(k);
e(1,k) = pd(k) - p(1,k);
e(1,k+1) = pd(k+1) - p(1,k+1);
end
%% 第二次迭代
i = 2;
for k = 1:1:k_length
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
















 4124
4124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









