






在机器人的发展历程中,让机器人实现灵活操作一直是科研人员努力攻克的难题。
我们这篇文章给大家带来一份新的工作:DexForce
一、研究背景:机器人灵活操作的困境
在机器人操作领域,灵巧操作一直是研究的重点和难点,尤其是在处理需要精细动作和接触力控制的任务时,机器人面临着诸多挑战。
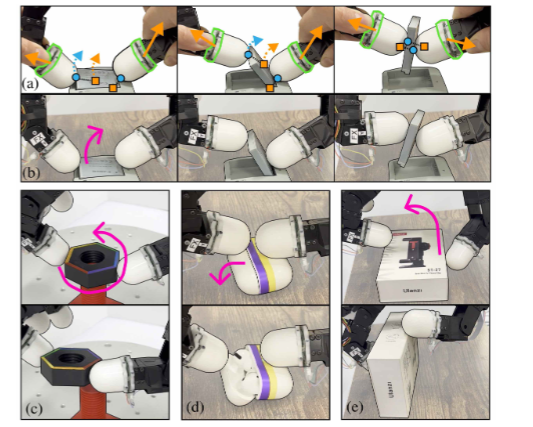
在日常生活中,像打开 AirPods 盒子、翻转盒子、抓取薄电池、拧螺母这些看似简单的动作,对机器人来说却非常困难。因为这些接触丰富的任务,不仅要求机器人在正确的时间、正确的接触位置施加合适的力,还需要在接触过程中进行精确的协调和控制。比如打开 AirPods 盒子,需要在多个接触点施加精确的力,力度小了打不开,力度大了又可能损坏盒子;抓取薄电池时,既要施加足够的力抓取,又不能用力过度导致电池损坏,还得协调好与电池的接触和脱离。
目前,模仿学习是教机器人执行任务的常用方法之一。它需要高质量的示范,也就是一系列的状态 - 动作对。在接触丰富的灵巧操作中,这些动作必须能产生合适的力。然而,现有的收集灵巧操作示范的方法存在很大问题。
最常用的遥操作方法,通过跟踪人类手部动作并将其重定位到机器人位置来获取机器人动作。但这种方法有两个大麻烦:
一是人类手部运动和大多数机器人手部运动方式不同,这就是所谓的 “人 - 机器人对应问题”。简单来说,人很难通过自己手部的动作,直观地让机器人手部做出精确的动作。就好比你想让机器人手指像你手指一样灵活弯曲,但你会发现很难通过自己的动作准确传达给机器人。
二是在任务执行过程中,演示者无法感受到机器人所感受到的力,缺乏这种触觉反馈,很难让机器人对物体施加正确的力。想象一下,你看不见也摸不着机器人抓东西时的力度,怎么能保证它抓得恰到好处呢?
其他一些改进方法,比如 ResPilot 通过残差高斯过程学习改进遥操作,Tilde 使用双机器人操控定制的四指手,虽然在一定程度上缓解了 “人 - 机器人对应问题”,但都没有给操作人员提供触觉反馈。
还有一些类似 “手把手” 或外骨骼的方法,虽然能让人类手部运动更接近机器人手部运动,但这些方法大多只适用于演示抓取动作,对于我们所关注的指尖灵巧操作并不适用。
正是因为现有方法存在这些不足,研究人员提出了 DexForce 方法,旨在解决接触丰富的灵巧操作示范收集问题,让机器人能够更好地学习和执行这些复杂任务。
二、DexForce 方法:力感知下的精准行动
DexForce 方法的核心就是利用在运动学演示过程中测量到的接触力,来计算用于策略学习的力感知动作,从而收集高质量的演示数据,让机器人学会接触丰富的灵巧操作任务。
(一)硬件准备:赋予机器人 “触觉”
要实现这一目标,首先得给机器人配备特殊的 “装备”。研究人员在机器人手上的每个指尖底部安装了 6 轴力 - 扭矩传感器(就像图 1a 里绿色部分所示),这样操作人员在操作机器人手指时,无论在传感器上方的哪个位置抓握,都不会影响力的测量。同时,还在机器人手腕上安装了 RealSense D435 相机,并配上鱼眼镜头,用于捕捉 RGB 图像,获取场景的视觉信息。有了这些硬件设备,机器人就能 “感受” 到接触力,还能 “看到” 周围的环境了。
(二)计算力感知位置目标:让动作更合理
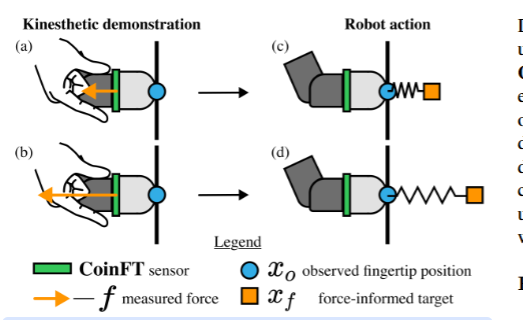
在运动学演示过程中,机器人会记录下每个手指的状态,包括观察到的指尖位置xo∈R3xo∈R3(图 2 里的蓝色圆圈)和相应的接触力f∈R3f∈R3(橙色箭头)。但要注意,观察到的指尖位置并不能直接作为机器人执行任务的动作,因为它无法再现测量到的力。
为了得到合适的动作,研究人员利用观察到的指尖位置和测量到的接触力来计算力感知位置目标xfxf。这里用到了笛卡尔阻抗控制的原理,简单来说,阻抗控制就像给机器人设定了一个类似弹簧的模型,通过控制弹簧的刚度、阻尼等参数,来产生期望的运动和力。在笛卡尔阻抗控制器中,控制力(F)的计算公式是F=Kp(xd−xc)−Kv(x˙c)F=Kp(xd−xc)−Kv(x˙c) ,其中KpKp是刚度增益矩阵,KvKv是阻尼增益矩阵,xdxd是期望的指尖位置,xcxc是当前的指尖位置,x˙cx˙c是指尖速度。
而要计算力感知位置目标xfxf,则是基于控制律的第一个项,把力和位移的关系看作一个弹簧模型。在准静态运动的假设下,得到公式xf=xo+Kffxf=xo+Kff,这里的KfKf是手动调整的刚度矩阵。
打个比方,当操作人员在运动学演示中用机器人指尖按压一个表面时,就像给弹簧施加了压力。随着施加力的增加,根据这个公式,力感知目标就会像弹簧被压得更深一样,更深入地进入表面(如图 2c 和 2d 所示)。虽然这个公式没有考虑软接触和摩擦的情况,但在很多任务中,通过实验发现它已经足够用了。
(三)演示数据收集过程:两步走获取优质数据
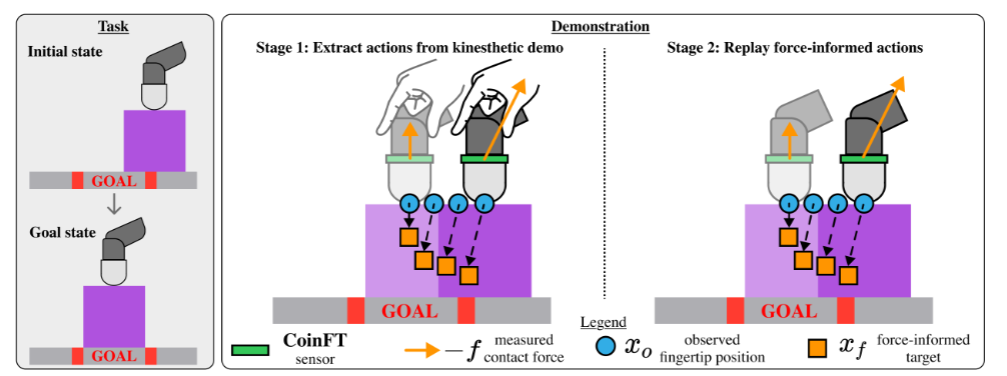
DexForce 演示数据收集过程分为两个阶段。
第一阶段是提取力感知目标。在运动学演示中,机器人会记录下每个手指在(T)个时间步长内的轨迹,包括观察到的指尖位置xo,1...xo,Txo,1...xo,T和相应的接触力f1...fTf1...fT。然后利用前面提到的公式xf=xo+Kffxf=xo+Kff,计算出力感知位置目标xf,1...xf,Txf,1...xf,T(图 3 里的橙色方块)。
第二阶段是获取最终用于策略学习的演示数据。在第一阶段收集的运动学演示数据不能直接用于训练策略,因为这些数据里包含操作人员的手,而测试时的图像只有机器人。所以,研究人员通过笛卡尔阻抗控制器跟踪第一阶段计算出的力感知目标xf,1...xf,Txf,1...xf,T,重新播放运动学演示。在这个过程中,调整公式里的弹簧刚度KfKf ,这里Kf=(1/220)∗I3Kf=(1/220)∗I3,I3I3是 3x3 的单位矩阵,确保重放能够成功再现运动学演示。同时,利用手腕上的相机捕捉图像观察,记录新的观察到的指尖位置xo,1∗...xo,T∗xo,1∗...xo,T∗、接触力f1∗...fT∗f1∗...fT∗、接触力矩m1∗...mT∗m1∗...mT∗和图像I1...ITI1...IT。这样,就得到了符合测试条件、只包含机器人的演示数据。
(四)策略学习:让机器人学会 “思考”
有了演示数据,接下来就是让机器人通过学习这些数据,掌握执行任务的策略。研究人员使用 Diffusion Policies(扩散策略)进行学习。在每个时间步(t),观察数据由图像ItIt的特征、第二阶段的接触力ft∗ft∗和每个手指的力矩mt∗mt∗连接组成。策略的输出是力感知目标,通过前面提到的阻抗控制器来执行这些目标。在训练过程中,以力感知目标xfxf为监督,让机器人不断学习,调整自己的策略,逐渐学会如何在不同的情况下执行任务。
三、实验:验证 DexForce 的实力
为了验证 DexForce 方法的有效性,研究人员进行了一系列实验,主要围绕三个关键问题展开:一是使用 DexForce 的力感知动作对模仿学习的成功有多重要?二是在策略观察中包含接触力数据对策略性能有什么影响?三是策略在具有不同力特征的分布外场景中的泛化能力如何?
如下图所示:
点击机器人灵巧操作新突破,力感知技术让机械手更精准查看全文

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









