







 文章介绍了HOME论文,它采用了denseheatmap输出来预测自动驾驶场景中的目标位置。通过渲染的bev图和轨迹信息作为输入,经过CNN处理生成heatmap。训练时使用高斯分布生成真值heatmap并采用像素级focalloss。文章重点在于后处理算法,包括基于MR的贪心采样和K-means优化FDE,以提高多目标预测的准确性。实验结果显示,在K=6时表现突出,特别是在减少FDE指标上。
文章介绍了HOME论文,它采用了denseheatmap输出来预测自动驾驶场景中的目标位置。通过渲染的bev图和轨迹信息作为输入,经过CNN处理生成heatmap。训练时使用高斯分布生成真值heatmap并采用像素级focalloss。文章重点在于后处理算法,包括基于MR的贪心采样和K-means优化FDE,以提高多目标预测的准确性。实验结果显示,在K=6时表现突出,特别是在减少FDE指标上。
前言
文章地址: HOME
上篇讲了dense TNT,把sparse 输出转换为dense的,获得更多有用的信息,2021年也有一篇论文就是本文的HOME,也使用了dense的heatmap输出,有着相似的思想。不过这篇文章没有采用vectornet的编码形式,还是用的渲染的bev图作为encoder的输入。(Thomas还发表了GOHOME,改为了vector形式的输入,这是后话)。下面让我们看一下这篇论文是如何训练和利用heatmap的。
框架
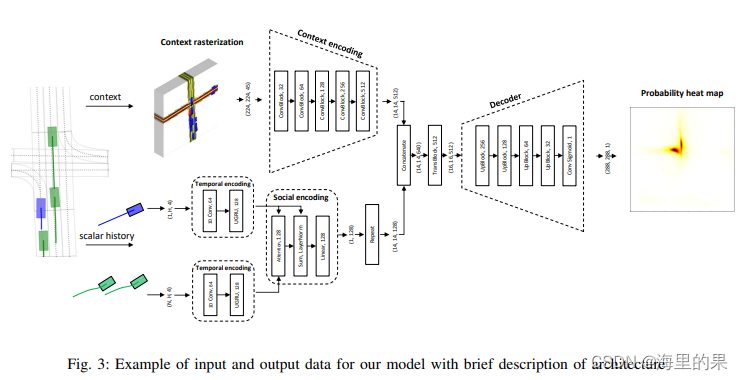
上图的pipline非常清晰,用渲染的bev图作为环境信息输入,concat上周围车辆的轨迹信息,最终decoder出来一个heatmap图。文章的重心在如何利用这个heatmap图上,也就是提取出K个goal点上,这一步dense TNT用的训练网络的方式选择,pseudo label 采用的随机优化算法寻找。这篇文章用的是后处理的算法,没有网络化。
想额外补充的是,无论这篇文章还是前面的dense TNT, 发力点都在:如何找出更好的topk多模组合,提升topk的MR,毕竟是为了打榜。即使我top1不行,但是采样的好,topk的指标就能上去。后面会看到,HOME的top1不是最好的,top6却有较大的提升。
文中采用渲染的bev图作为输入,shape大小是(225 225 45)
其中 5 个语义通道,描述可行驶区域,道路边界,和道路中心线。此外,用20个通道表达目标障碍物的其历史位置,用20个通道表达其他障碍物的历史位置。分辨率为0.5m/pixel。该45通道的输入,经过CNN网络经过卷积和降采样变成(14 14 512)。bev之外,论文还使用了一些补充的vector形式的输入,把历史的轨迹,经过Temporal encoding(1D卷积+UGRU)编码。之后以所预测的目标车辆为q, 其他车为k,进行信息融合,最终该部分的输出,经过concat和bev编码后的特征进行信息融合。最后经过一系列反卷积层操作,得到一个(288 288 1)的heatmap图,其分辨率为0.25m/pixel。
上述处理过程基本属于常规操作,只是之前没有这种dense输出的heatmap用于预测的论文。
heatmap的训练和使用
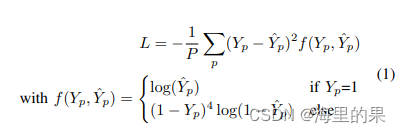
训练过程,需要准备一张真值的heatmap图,这张heatmap是由真值终点为中心点,按照高斯分布(标准差为4pixel)生成的。然后按照公式1,采用pixel-wise focal loss 进行训练。
得到heatmap之后,需要设计相应的sampling算法得到K个end points。这也是文章最重要的部分所在。
使用heatmap前,文章使用双线性插值得到了0.25m/pixel的分辨率,以得到更为精确的位置坐标。
step1 优化MR

设定heatmap上以采样点x为中心,半径为2m (打比赛中定的标准)的区域覆盖的点的概率之和为该点代表概率。文章期望k个采样点所覆盖的区域的概率之和是最大的,实现采用了一种贪心算法。每次选择使得覆盖区域概率和最大的位置,然后把覆盖区域的值都设为0,这样反复就能得到一组topk点。求取概率和时候,可以采用一个固定大小的Kernel,以卷积的方式计算。
step2 优化FDE

文章借鉴了Kmeans算法。前一步得到了k个点,及其计算的概率值。该位置被用于初始化为k个质心的位置。如上图所示,每个迭代中,需要计算heatmap中的每一个点到k个质心之间的距离d_k_i。再计算每个点到最近的质心之间的距离mi。计算新的质心位置的公式可以这样理解。首先是只有距离在3m以内的点有贡献。其次,加权系数在kmean中一般是只有概率p,这里考虑到了距离, 除了d_k_i,也就是越近的贡献越大。第二个系数考虑了是否属于c_k点的控制范围,如果x_i最近的就是c_k点,那该系数为1,如果x_i最近点已经不是c_k点,那该系数会随着越来越远soft减小到0。从计算过程可以看出,质心点移动方向,主要受专属c_k,距离近和概率高的点的牵引。
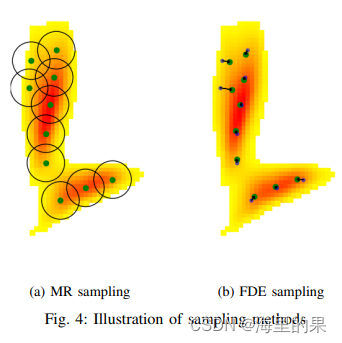
该步骤可以使得K个质心点变得互相之间距离更近,这一定程度上牺牲了K个圆的总覆盖率,但是微调使得他们更接近高概率区域,有利于降低FDE的指标。
实验
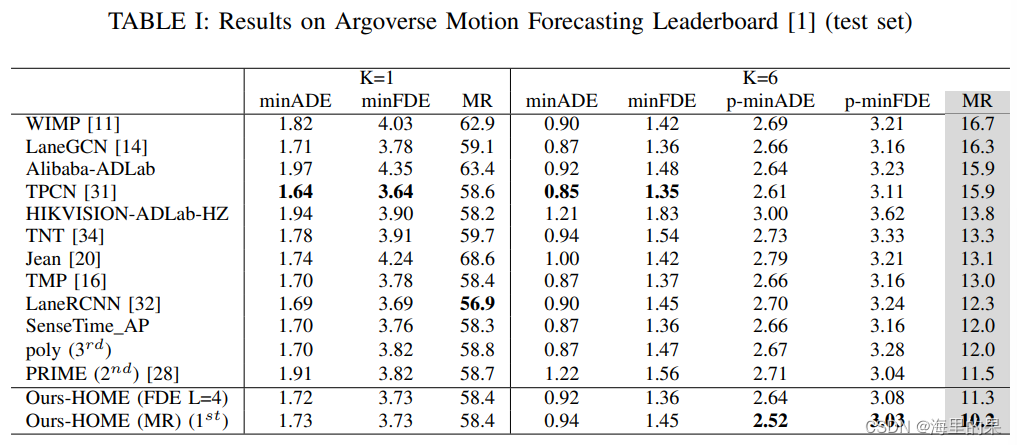
不同方法在argoverse的效果对比。HOME不意外的在K=6的指标上比较突出。最后一行的MR也就是参数L=0时,MR最小,因为MRsampling照顾了最大的覆盖区域,具有极致的交并比,其他的方法难以与之匹敌在情理之中了。
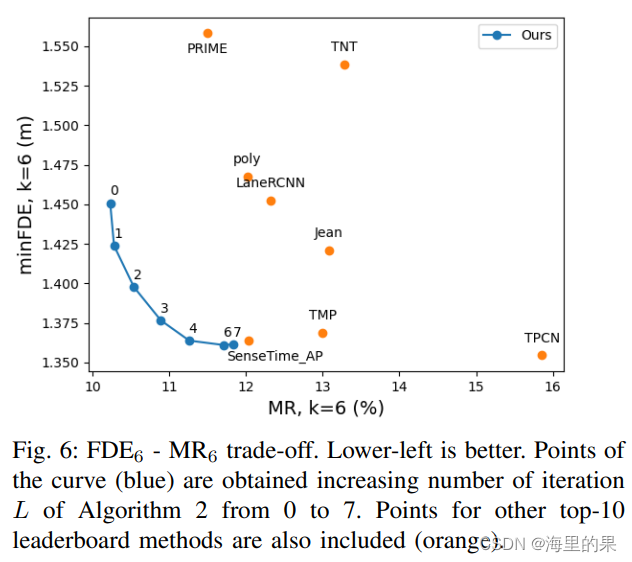
算法中L参数对结果的影响变化。L增加会使MR更worse,FDE提升。
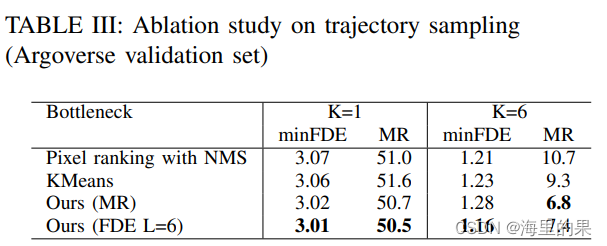
在输出相同的heatmap基础上,对比一些直观的sample算法,展示其设计的sample方法的效果,如按pixel最大的选择,配合NMS算法,采样6个。Kmeans 聚类得到k个点。
文章方法的Top1效果一般,总体上是改为了heatmap输出 & 一定的后处理算法比较新颖。thomas 后面又搞了一篇GO HOME,有时间可以简单再过一下。

















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









