






SRA-Toolkit下载
SRA(Sequence Read Archive)数据库是用于存储二代测序的原始数据的数据库。除了原始序列数据外,SRA现在也存在raw reads在参考基因的比对信息。
根据SRA数据产生的特点,将SRA数据分为四类:
- Studies 研究课题
- Experiments 实验设计
- Runs 测序结果集
- Samples 样品信息
SRA中数据结构的层次关系为 Studies -> Experiments -> Samples -> Runs。
- Studies是就实验目标而言的,一个study可能包含多个experiments。
- Experiments包含了Sample、DNA source、测序平台、数据处理等信息。
- 一个experiment可能包含一个或多个runs。
- Runs表示测序仪运行所产生的reads。
SRA数据库用不同的前缀加以区分:
- ERP或SRP表示Studies;
- SRS表示Samples;
- SPX表示Experiments;
- SRR表示Runs;
下载数据使用专门的SRA工具:
1. 下载最新版SRA Toolkit
(1)进入NCBI官网,选择“Transfer NCBI data to your computer”
(2)选择“Download Tools”
(3)选择SRA Toolkit下载 (4)选择自己需要的版本,我这里是选择了Ubuntu Linux 64位版本,获取下载地址后用wget命令进行下载
(4)选择自己需要的版本,我这里是选择了Ubuntu Linux 64位版本,获取下载地址后用wget命令进行下载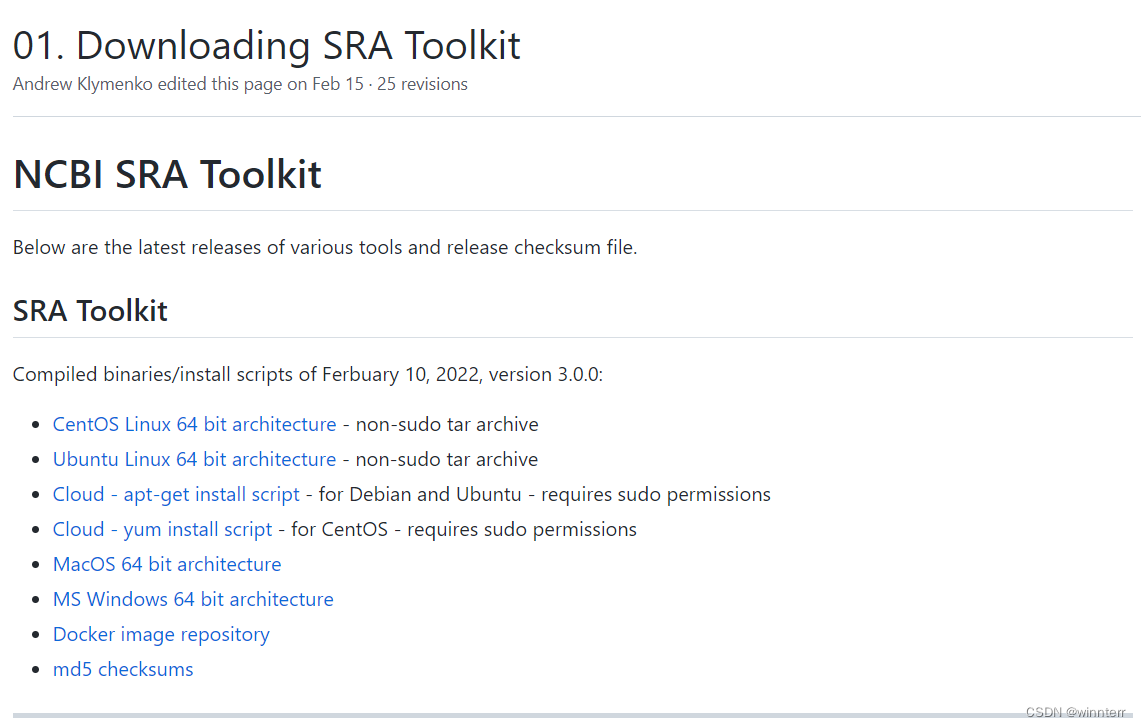
在ubuntu系统中,使用wget命令进行下载:
wget “https://ftp-trace.ncbi.nlm.nih.gov/sra/sdk/3.0.0/sratoolkit.3.0.0-ubuntu64.tar.gz”
(5)解压并配置环境
tar xzvf sratoolkit.3.0.0-ubuntu64.tar.gz
cd ./sratoolkit.3.0.0-ubuntu64/bin
./vdb -config --interactive
弹出如下交互终端
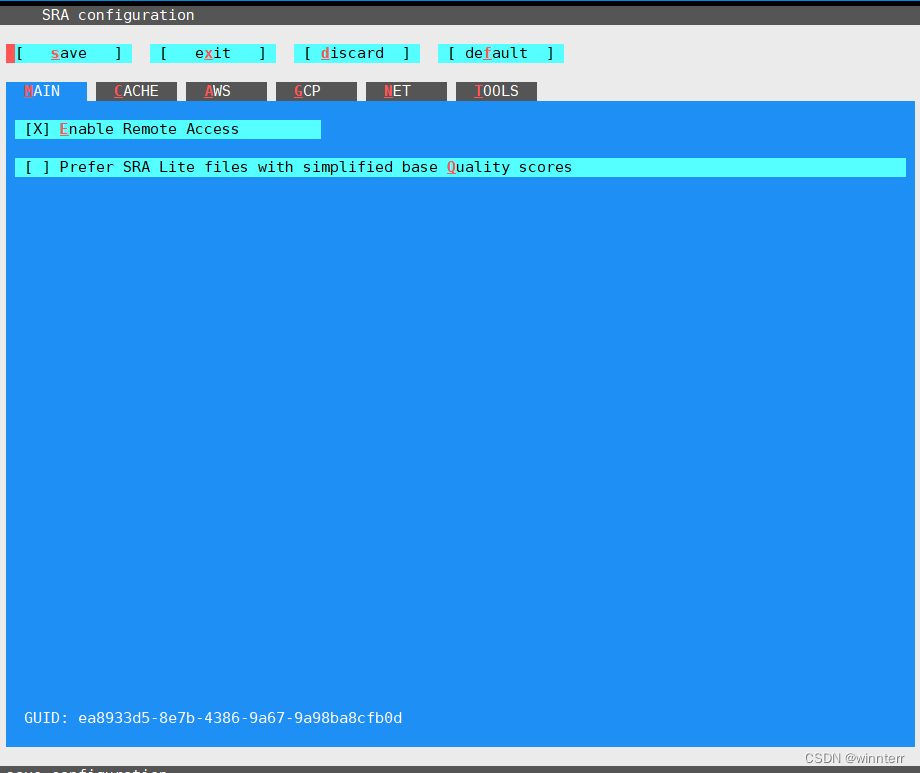
按c直接进入配置信息,按TAB键切换到第一个choose选项,enter键可以进行文件夹的选择,是存放以后下载的SRA数据。这里需要提前建好一个空文件夹,若文件夹非空,则不会设置成功;
第二个choose存放的是SRA-Toolkit的可执行命令路径;
设置完成后按X保存退出。
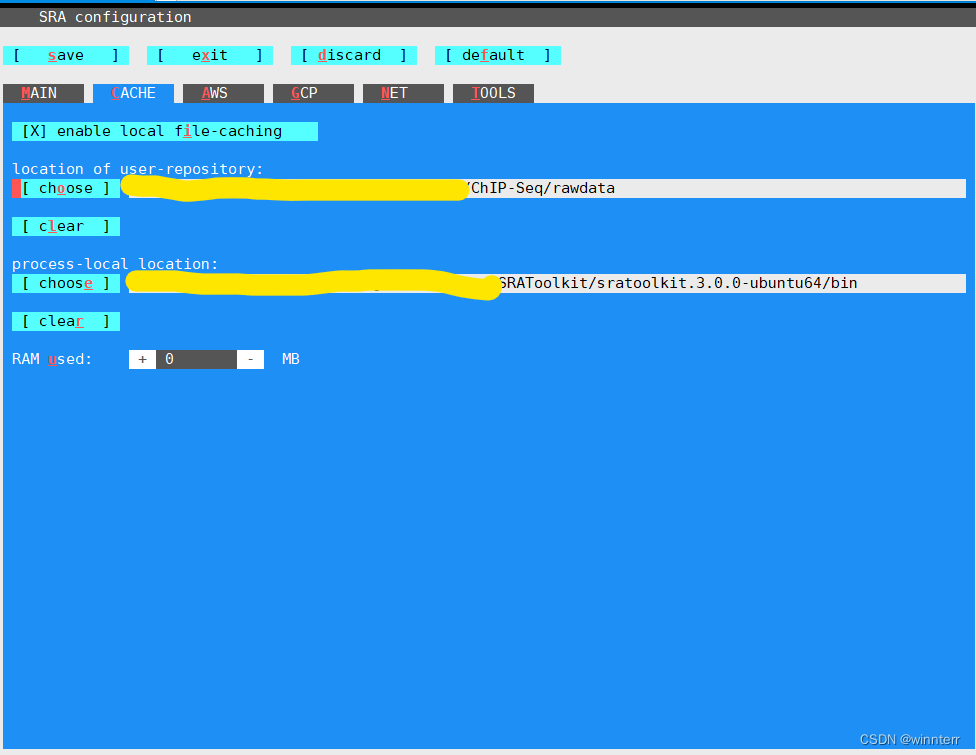
按s保存,按enter。然后点击Esc两次退出。
接下来设置环境变量
vim ~/.bashrc
在末尾添加:export PATH=“$PATH:/XXXX/software/sratoolkit.3.0.0-ubuntu64/bin”;
source ~/.basrc
设置环境变量,配置完成!!!可正常使用了。若再次安装不同的版本,需要再次设置。

















 8368
8368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









