







YOLOv4中相关优化方法
1.Bag of freebies(增加训练时间,不影响推理速度下提升性能)
1.1 数据增强:
-
亮度、对比度、色调、饱和度、噪音等
-
随机缩放、裁剪、翻转、旋转等
-
模拟遮挡
- random erase or CutOut: 随机将图像中的矩形区域随机填充像素值或置零
- MixUp:将两张图像按照一定比例因子进行叠加融合,该比例因子服从B分布。融合后的label包含两张图像的所有标签。
- CutMix:从一张图中crop一块矩形图像到另一张图中,对应融合后图像的label也要进行更新。
- 风格迁移GAN:通过GAN的方式扩增数据量
-
feature map层面的增强
-
DropOut:
- 原理:前向传播的时候,让某个神经元的激活值以一定的概率1-p停止工作(输出值清0),bp更新权值时,不再更新与该节点相连的权值。
- 作用:解决因参数过多导致的过拟合,多用于全连接层。
-
DropConnect:
- 原理:输出节点中将每个与其相连的输入权值以1-p的概率清0(模型权重清零),DorpConnect为DorpOut的改进
- dropout与dropconnect如下图:
-
DropBlock:
-
原理:在特征图中随机生成种子点,在种子点周围按照一定的宽高将元素置0。形象化地如下图:

-
作用:针对卷积层正则化。
-
-
1.2 解决语义分布差异(类别不平衡)
-
Two Stage检测使用:
-
OHEM:
-
优点:
- 对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强
- 当数据集增大,算法可以在原来基础上提升更大
-
核心:核心是选择一些hard example作为训练的样本从而改善网络参数效果,hard example指的是有多样性和高损失的样本
-
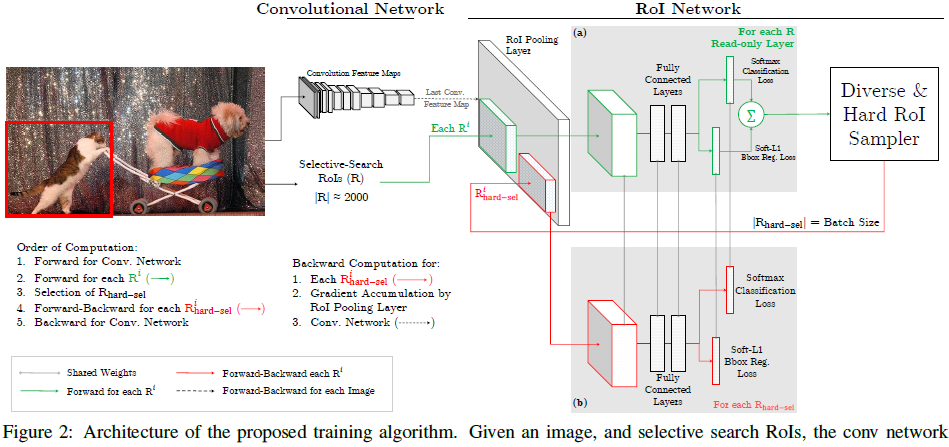
原理:(基于fast rcnn改进)hard example是根据每个ROI的损失来选择的,选择损失最大的一些ROI。首先,ROI经过ROI plooling层生成feature map,然后进入只读的ROI network得到所有ROI的loss;然后根据损失排序选出hard example,并把这些hard example作为下面那个ROI network(从图中可知两个RoI Network是参数共享的)的输入进行训练。下面为OHEM原理图:
-
-
-
One Stage检测使用:
-
focal loss:
-
动机:
- one-stage准确率不如two-stage的原因:样本的类别不均衡导致的
- OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本
-
原理:
-
focal loss是对交叉熵损失的改进。通过loss函数中乘一个因子a(很小)来控制正负样本对总的loss的共享权重(负样本多则会多次乘a,导致权重降低);引入gamma参数控制容易分类和难分类样本的权重。公式如下图,详细解读可参照
-
-
-
-
label smooth:
- 原理:将one hot 的label标签转为相近的数值,可以体现出类别相似度。典型的应用为知识蒸馏。
1.3 损失函数
-
MSE loss:通过估计{centerX, centerY, W, H}或{topleftX, topleftY, bottomrightX, bottomrightY}的偏移,直接进行位置回归,损失度量方式为MSE。
-
IoU loss:
- 公式:
L o s s = − l n ( I o U ) Loss = -ln(IoU) Loss=−ln(IoU)
- 特点:
- IoU=0,不能反映两者的距离大小
- IoU无法精确的反映两者的重合度大小
-
GIoU loss:
- 公式:
G I o U = I o U – ( C − ( A ∪ B ) ) / C , C 为 最 小 包 围 矩 形 GIoU = IoU – (C-(A ∪ B))/C,C为最小包围矩形 GIoU=IoU–(C−(A∪B))/C,C为最小包围矩形
L o s s = 1 − G I o U Loss = 1-GIoU Loss=1−GIoU
- 特点:
- GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度
- GIoU对scale不敏感
-
DIoU(Distance-IoU) loss:
- 公式:
D I o U = I o U − ρ 2 ( b , b g t ) c 2 DIoU = IoU - \frac{\rho^2(b, b^{gt})}{c^2} DIoU=IoU−c2ρ2(b,bgt)
L o s s = 1 − D I o U Loss = 1- DIoU Loss=1−DIoU
其 中 b , b g t 分 别 代 表 了 预 测 框 和 真 实 框 的 中 心 点 , ρ 是 计 算 两 个 中 心 点 间 的 欧 式 距 离 。 c 为 预 测 框 和 真 实 框 的 最 小 闭 包 区 域 的 对 角 线 距 离 。 其中b, b^{gt}分别代表了预测框和真实框的中心点,\rho是计算两个中心点间的欧式距离。 c为预测框和真实框的最小闭包区域的对角线距离。 其中b,bgt分别代表了预测框和真实框的中心点,ρ是计算两个中心点间的欧式距离。c为预测框和真实框的最小闭包区域的对角线距离。
如下图所示:
- 特点:
- 目标与anchor之间的距离,重叠率以及尺度都考虑进来
- DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多
-
CIoU loss:
-
公式:
C I o U = I o U − ρ 2 ( b , b g t ) c 2 − α v CIoU = IoU - \frac{\rho^2(b, b^{gt})}{c^2} - \alpha v CIoU=IoU−c2ρ2(b,bgt)−αv
v衡量长宽比的相似性,alpha为权重函数。
v = 4 π 2 ( a r c t a n w g t h g t − a r c t a n w h ) 2 v = \frac{4}{\pi^2}{(arctan\frac{w^{gt}}{h^{gt}}-arctan\frac{w}{h})}^2 v=π24(arctanhgtwgt−arctanhw)2α = v ( 1 − I o U ) + v \alpha = \frac{v}{(1-IoU)+v} α=(1−IoU)+vv
L o s s = 1 − C I o U Loss = 1 - CIoU Loss=1−CIoU
-
特点:在DIoU的基础上将预测框与真实框长宽比的相似性考虑到计算中
-
2.Bag of specials(推理中增加很小成本但能换来较大精度提升)
2.1增大感受野
-
SPP(空间金字塔池化):
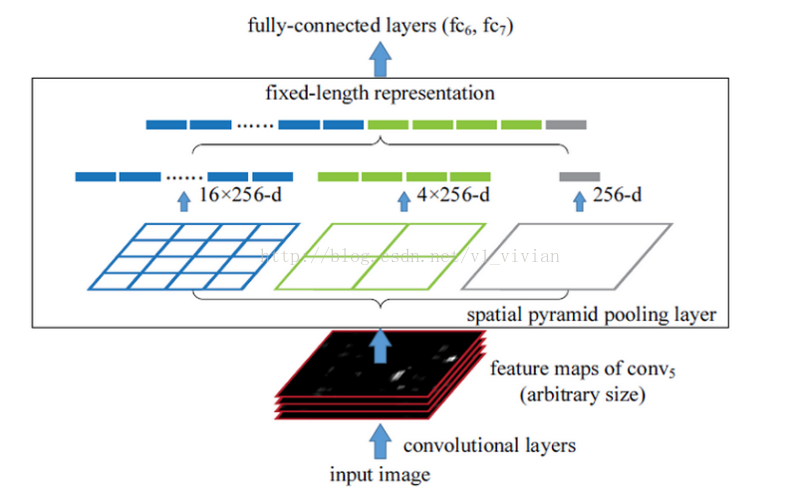
- 原理:通过对feature map 按照不同的网格尺寸进行切分,并对每个切分的格进行全局池化,可以生成固定大小的输出,在切分并下采样过程中可以增大感受野,并可保证在有全连接层的网络中输入可以是任意尺寸。
- 特点:输出为一维的vector,不适用与FCN(全卷积网络)
- 图示:
-
改进的SPP(YOLOv3设计)
-
特点:原始SPP中输出结果为1维vector,不能在FCN这种二维feature中使用SPP
-
原理:将SPP-Net不同kxk核大小的max pooling输出后的feature map进行concat(小feature map通过上采样的方式进行放大)这样就可以增加原始输出的feature map中较大feature map的感受野。
-
图示:
-
-
ASPP金字塔池化
-
背景:为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample,但由于FCN中使用诸如SPP中的pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,提出空洞卷积代替Pooling层既可保留更多信息,又能增大感受野。
-
原理:使用空洞卷积代替Pooling,无需下采样即可增大感受野,使用不同atrous rate 来生成特征金子塔。
-
图示:

-
-
RFB-Net
- 背景:在one stage检测中尽可能地增加backbone感受野
- 原理:借鉴了inception结构的并行结构,并对不同大小卷积核后加上不同空洞率的空洞卷积(卷积核为kxk,空洞率为k)(作者认为这样做对kernels的大小和离心率之间的关系进行了建模)
- 图示
2.2 注意力机制
-
SE
- 原理:基于feature map通道的注意力机制。Squeeze过程:通过Global Average Pooling将二维feature拉成一维,Excitation过程:输出的1x1xC数据再经过两级全连接。最后通过sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。
- 特点:cpu上增加2%的耗时带来1%的准确率收益(ImageNet classification),但在GPU上耗时增加大(10%)
- 图示:
-
CBAM(SE+SAM)
- 原理:即为SE和SAM的组合使用,SE上方已介绍,SAM原理:首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
- 特点:SAM比SE更小的速度损失即可带来不错的精度收益,CBAM将两者组合起来使用在多维度上执行注意力机制。
- 图示(上方为SE,下方为SAM):
2.3 特征融合
- Skip connection
- FPN style:见下图(d)
-
SFAM(尺度特征融合模块)–在SSD改进版本M2Det提出
-
M2Det整体思路的解析
-
原理:将多个TUM (联级轻量 U 形模块)生成的特征聚合成一个包含多级特征的特征金字塔,特征金子塔的每一层级的特征是基于各U形模块中相同尺寸特征基于SE模块进行加权的融合。下面给出SFAM的简要原理图。

-
-
ASFF(自适应尺度融合)
- 原理:首先通过FPN产生level1-level3不同尺度的特征图,作者使用ASFF(adaptively spatial feature fusion)思想进行融合,思想就是level1-level3个尺度图分别再融合成3个对应尺度的特征图,融合的权重自适应调整。拿ASFF-1作为例子,首先将3个尺度的图都resize到level1尺度大小,然后学习一个融合权重(使用softmax 做不同feature map加权),这样可以更好地学习不同特征尺度对于预测特征图的贡献。
- 原理图

-
BiFPN模块–来自EfficientDet
- 模块结构:BiFPN是对PANet的改动,提出了三个优化
- 删掉那些只有一个输入边的节点,因为只有一个输入边的节点就没有特征融合,对特征网络的贡献少
- 添加了从原始输入到输出节点的边(同一级别的输入输出)
- 把双向路径看作是一个特征网络层,就可以多次重复特征层得到更多的特征融合。(就是图中f子图,可以把f图当作一个层,可以多次重复,前一层的5个输出(
)当作后一层的5个输入)
- 特征融合方式:在相同size feature map相加时采用先特征加权在相加的方式,使两层的特征具有不同的权重。具体的加权方式为使用简化的softmax(去掉指数运输)进行加权
- 图示
- 模块结构:BiFPN是对PANet的改动,提出了三个优化
2.4 激活函数(目的:增加非线性)
-
Sigmod:
-
公式:
S ( x ) = 1 1 + e − x S(x)=\frac{1}{1+e^{-x}} S(x)=1+e−x1 -
曲线:
-
特点:计算量大,反向传播容易梯度消失或爆炸
-
-
ReLU:
-
公式:
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x) -
曲线:
-
特点:当x<0时结果为0,此时会出现0梯度
-
-
LReLU:
- 公式:
f ( x ) = { x , i f x > 0 0.01 ∗ x i f x < = 0 f(x)=\begin{cases} x,\quad if \quad x>0\\ 0.01*x \quad if \quad x<=0\end{cases} f(x)={x,ifx>00.01∗xifx<=0
- 特点:方式ReLU出现0梯度情况
-
PReLU:
- 公式:
f ( x ) = { x , i f x > 0 a x i f x < = 0 f(x)=\begin{cases} x,\quad if \quad x>0\\ ax \quad if \quad x<=0\end{cases} f(x)={x,ifx>0axifx<=0
- 特点:同LReLU
-
ReLU6:
- 公式:
f ( x ) = m i n ( 6 , m a x ( 0 , x ) ) f(x)=min(6,max(0,x)) f(x)=min(6,max(0,x))
- 特点:限制其最大输出值为6,主要针对量化网络设计的,在移动端低精度时也能有较好的数值分辨率.
-
SELU:
-
公式:
f ( x ) = λ ∗ { x , i f x > 0 α ( e x − 1 ) i f x < = 0 f(x)=\lambda* \begin{cases} x,\quad if \quad x>0\\ \alpha (e^x-1) \quad if \quad x<=0\end{cases} f(x)=λ∗{x,ifx>0α(ex−1)ifx<=0 -
特点:x<0时使用指数激活函数.SELU可以使得输入在经过一定层数之后变为固定的分布,防止梯度爆炸。
-
-
Swish:
-
公式:
f ( x ) = x ∗ s i g m o i d ( β x ) f(x)=x*sigmoid(\beta x) f(x)=x∗sigmoid(βx) -
曲线:

- 特点:Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数,模型效果优于ReLU
-
-
Hard-Swish
-
公式:
h − s w i s h ( x ) = x ∗ R e L U 6 ( x + 3 ) 6 h-swish(x)=x*\frac{ReLU6(x+3)}{6} h−swish(x)=x∗6ReLU6(x+3) -
曲线:

-
特点:针对量化模式下对Swish的改进(Sigmoid比ReLU6耗时),使用ReLU6替换sigmoid
-
-
Mish:
- 公式:
M i s h = x ∗ t a n h ( l n ( 1 + e x ) ) Mish= x*tanh(ln(1+e^x)) Mish=x∗tanh(ln(1+ex))
-
曲线:
-
特点:Mish激活函数比ReLU等激活函数更加平滑,训练更稳定精度有提升,有望替换ReLU,只是计算更复杂.
2.5 后处理(anchor free无)
-
NMS
-
soft NMS:
-
特点: 对于重叠框中除置信度最高的框外,将其余框的置信度用稍低一点的置信度来代替原有置信度,而不是像NMS直接将iou超过阈值的框置信度置零.这种方式可以有效地增加重叠目标的召回.具体如何降低置信度的方式如下图公式:
-
-
DIoU NMS:
- 特点: 基于soft NMS进行改进.将bbox中心点之间的距离信息考虑到置信度更新中来,将中心点距离信息作为soft NMS公式的偏执项.
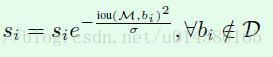
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









